 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Do Vision Language Models Struggle To Recognize Human Emotions?
Apr 16, 2026Understanding emotions is a fundamental ability for intelligent systems to be able to interact with humans. Vision-language models (VLMs) have made tremendous progress in the last few years for many visual tasks, potentially offering a promising solution for understanding emotions. However, it is surprising that even the most sophisticated contemporary VLMs struggle to recognize human emotions or to outperform even specialized vision-only classifiers. In this paper we ask the question "Why do VLMs struggle to recognize human emotions?", and observe that the inherently continuous and dynamic task of facial expression recognition (DFER) exposes two critical VLM vulnerabilities. First, emotion datasets are naturally long-tailed, and the web-scale data used to pre-train VLMs exacerbates this head-class bias, causing them to systematically collapse rare, under-represented emotions into common categories. We propose alternative sampling strategies that prevent favoring common concepts. Second, temporal information is critical for understanding emotions. However, VLMs are unable to represent temporal information over dense frame sequences, as they are limited by context size and the number of tokens that can fit in memory, which poses a clear challenge for emotion recognition. We demonstrate that the sparse temporal sampling strategy used in VLMs is inherently misaligned with the fleeting nature of micro-expressions (0.25-0.5 seconds), which are often the most critical affective signal. As a diagnostic probe, we propose a multi-stage context enrichment strategy that utilizes the information from "in-between" frames by first converting them into natural language summaries. This enriched textual context is provided as input to the VLM alongside sparse keyframes, preventing attentional dilution from excessive visual data while preserving the emotional trajectory.
A Causal Framework for Mitigating Data Shifts in Healthcare
Mar 13, 2026Developing predictive models that perform reliably across diverse patient populations and heterogeneous environments is a core aim of medical research. However, generalization is only possible if the learned model is robust to statistical differences between data used for training and data seen at the time and place of deployment. Domain generalization methods provide strategies to address data shifts, but each method comes with its own set of assumptions and trade-offs. To apply these methods in healthcare, we must understand how domain shifts arise, what assumptions we prefer to make, and what our design constraints are. This article proposes a causal framework for the design of predictive models to improve generalization. Causality provides a powerful language to characterize and understand diverse domain shifts, regardless of data modality. This allows us to pinpoint why models fail to generalize, leading to more principled strategies to prepare for and adapt to shifts. We recommend general mitigation strategies, discussing trade-offs and highlighting existing work. Our causality-based perspective offers a critical foundation for developing robust, interpretable, and clinically relevant AI solutions in healthcare, paving the way for reliable real-world deployment.
Beyond Pixel Histories: World Models with Persistent 3D State
Mar 03, 2026Interactive world models continually generate video by responding to a user's actions, enabling open-ended generation capabilities. However, existing models typically lack a 3D representation of the environment, meaning 3D consistency must be implicitly learned from data, and spatial memory is restricted to limited temporal context windows. This results in an unrealistic user experience and presents significant obstacles to down-stream tasks such as training agents. To address this, we present PERSIST, a new paradigm of world model which simulates the evolution of a latent 3D scene: environment, camera, and renderer. This allows us to synthesize new frames with persistent spatial memory and consistent geometry. Both quantitative metrics and a qualitative user study show substantial improvements in spatial memory, 3D consistency, and long-horizon stability over existing methods, enabling coherent, evolving 3D worlds. We further demonstrate novel capabilities, including synthesising diverse 3D environments from a single image, as well as enabling fine-grained, geometry-aware control over generated experiences by supporting environment editing and specification directly in 3D space. Project page: https://francelico.github.io/persist.github.io
Ambient Physics: Training Neural PDE Solvers with Partial Observations
Feb 14, 2026In many scientific settings, acquiring complete observations of PDE coefficients and solutions can be expensive, hazardous, or impossible. Recent diffusion-based methods can reconstruct fields given partial observations, but require complete observations for training. We introduce Ambient Physics, a framework for learning the joint distribution of coefficient-solution pairs directly from partial observations, without requiring a single complete observation. The key idea is to randomly mask a subset of already-observed measurements and supervise on them, so the model cannot distinguish "truly unobserved" from "artificially unobserved", and must produce plausible predictions everywhere. Ambient Physics achieves state-of-the-art reconstruction performance. Compared with prior diffusion-based methods, it achieves a 62.51$\%$ reduction in average overall error while using 125$\times$ fewer function evaluations. We also identify a "one-point transition": masking a single already-observed point enables learning from partial observations across architectures and measurement patterns. Ambient Physics thus enables scientific progress in settings where complete observations are unavailable.
CSEval: A Framework for Evaluating Clinical Semantics in Text-to-Image Generation
Feb 12, 2026Text-to-image generation has been increasingly applied in medical domains for various purposes such as data augmentation and education. Evaluating the quality and clinical reliability of these generated images is essential. However, existing methods mainly assess image realism or diversity, while failing to capture whether the generated images reflect the intended clinical semantics, such as anatomical location and pathology. In this study, we propose the Clinical Semantics Evaluator (CSEval), a framework that leverages language models to assess clinical semantic alignment between the generated images and their conditioning prompts. Our experiments show that CSEval identifies semantic inconsistencies overlooked by other metrics and correlates with expert judgment. CSEval provides a scalable and clinically meaningful complement to existing evaluation methods, supporting the safe adoption of generative models in healthcare.
GaussianHeadTalk: Wobble-Free 3D Talking Heads with Audio Driven Gaussian Splatting
Dec 11, 2025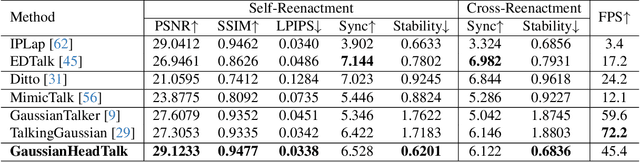
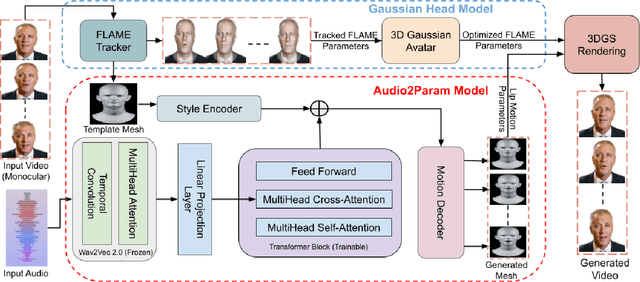
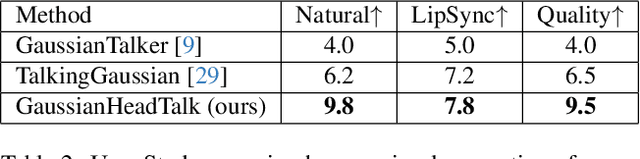

Speech-driven talking heads have recently emerged and enable interactive avatars. However, real-world applications are limited, as current methods achieve high visual fidelity but slow or fast yet temporally unstable. Diffusion methods provide realistic image generation, yet struggle with oneshot settings. Gaussian Splatting approaches are real-time, yet inaccuracies in facial tracking, or inconsistent Gaussian mappings, lead to unstable outputs and video artifacts that are detrimental to realistic use cases. We address this problem by mapping Gaussian Splatting using 3D Morphable Models to generate person-specific avatars. We introduce transformer-based prediction of model parameters, directly from audio, to drive temporal consistency. From monocular video and independent audio speech inputs, our method enables generation of real-time talking head videos where we report competitive quantitative and qualitative performance.
SWiFT: Soft-Mask Weight Fine-tuning for Bias Mitigation
Aug 26, 2025Recent studies have shown that Machine Learning (ML) models can exhibit bias in real-world scenarios, posing significant challenges in ethically sensitive domains such as healthcare. Such bias can negatively affect model fairness, model generalization abilities and further risks amplifying social discrimination. There is a need to remove biases from trained models. Existing debiasing approaches often necessitate access to original training data and need extensive model retraining; they also typically exhibit trade-offs between model fairness and discriminative performance. To address these challenges, we propose Soft-Mask Weight Fine-Tuning (SWiFT), a debiasing framework that efficiently improves fairness while preserving discriminative performance with much less debiasing costs. Notably, SWiFT requires only a small external dataset and only a few epochs of model fine-tuning. The idea behind SWiFT is to first find the relative, and yet distinct, contributions of model parameters to both bias and predictive performance. Then, a two-step fine-tuning process updates each parameter with different gradient flows defined by its contribution. Extensive experiments with three bias sensitive attributes (gender, skin tone, and age) across four dermatological and two chest X-ray datasets demonstrate that SWiFT can consistently reduce model bias while achieving competitive or even superior diagnostic accuracy under common fairness and accuracy metrics, compared to the state-of-the-art. Specifically, we demonstrate improved model generalization ability as evidenced by superior performance on several out-of-distribution (OOD) datasets.
* Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://melba-journal.org/2025:015
No time to train! Training-Free Reference-Based Instance Segmentation
Jul 03, 2025The performance of image segmentation models has historically been constrained by the high cost of collecting large-scale annotated data. The Segment Anything Model (SAM) alleviates this original problem through a promptable, semantics-agnostic, segmentation paradigm and yet still requires manual visual-prompts or complex domain-dependent prompt-generation rules to process a new image. Towards reducing this new burden, our work investigates the task of object segmentation when provided with, alternatively, only a small set of reference images. Our key insight is to leverage strong semantic priors, as learned by foundation models, to identify corresponding regions between a reference and a target image. We find that correspondences enable automatic generation of instance-level segmentation masks for downstream tasks and instantiate our ideas via a multi-stage, training-free method incorporating (1) memory bank construction; (2) representation aggregation and (3) semantic-aware feature matching. Our experiments show significant improvements on segmentation metrics, leading to state-of-the-art performance on COCO FSOD (36.8% nAP), PASCAL VOC Few-Shot (71.2% nAP50) and outperforming existing training-free approaches on the Cross-Domain FSOD benchmark (22.4% nAP).
CheXGenBench: A Unified Benchmark For Fidelity, Privacy and Utility of Synthetic Chest Radiographs
May 15, 2025We introduce CheXGenBench, a rigorous and multifaceted evaluation framework for synthetic chest radiograph generation that simultaneously assesses fidelity, privacy risks, and clinical utility across state-of-the-art text-to-image generative models. Despite rapid advancements in generative AI for real-world imagery, medical domain evaluations have been hindered by methodological inconsistencies, outdated architectural comparisons, and disconnected assessment criteria that rarely address the practical clinical value of synthetic samples. CheXGenBench overcomes these limitations through standardised data partitioning and a unified evaluation protocol comprising over 20 quantitative metrics that systematically analyse generation quality, potential privacy vulnerabilities, and downstream clinical applicability across 11 leading text-to-image architectures. Our results reveal critical inefficiencies in the existing evaluation protocols, particularly in assessing generative fidelity, leading to inconsistent and uninformative comparisons. Our framework establishes a standardised benchmark for the medical AI community, enabling objective and reproducible comparisons while facilitating seamless integration of both existing and future generative models. Additionally, we release a high-quality, synthetic dataset, SynthCheX-75K, comprising 75K radiographs generated by the top-performing model (Sana 0.6B) in our benchmark to support further research in this critical domain. Through CheXGenBench, we establish a new state-of-the-art and release our framework, models, and SynthCheX-75K dataset at https://raman1121.github.io/CheXGenBench/
Exploiting Mixture-of-Experts Redundancy Unlocks Multimodal Generative Abilities
Apr 01, 2025In this work, we undertake the challenge of augmenting the existing generative capabilities of pre-trained text-only large language models (LLMs) with multi-modal generation capability while satisfying two core constraints: C1 preserving the preservation of original language generative capabilities with negligible performance degradation, and C2 adhering to a small parameter budget to learn the new modality, ensuring scalability and efficiency. In contrast to current approaches that add dedicated modules, thereby significantly increasing the parameter count, we propose a method that leverages the underutilized capacity inherent in deep models. Specifically, we exploit the parameter redundancy within Mixture-of-Experts (MoEs) as a source of additional capacity for learning a new modality, enabling better parameter efficiency (C1). Moreover, we preserve the original language generation capabilities by applying low-rank adaptation exclusively to the tokens of the new modality (C2). Furthermore, we introduce a novel parameter initialization scheme based on the Gromov-Wasserstein distance to improve convergence and training stability. Through an extensive analysis of the routing mechanism, we uncover the emergence of modality-specific pathways and decreased redundancy within the experts that can efficiently unlock multi-modal generative capabilities. Overall, our method can be seamlessly applied to a wide range of contemporary LLMs, providing a new pathway for transitioning from uni-modal to multi-modal architectures.