 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking the Potential of Weakly Labeled Data: A Co-Evolutionary Learning Framework for Abnormality Detection and Report Generation
Dec 18, 2024



Anatomical abnormality detection and report generation of chest X-ray (CXR) are two essential tasks in clinical practice. The former aims at localizing and characterizing cardiopulmonary radiological findings in CXRs, while the latter summarizes the findings in a detailed report for further diagnosis and treatment. Existing methods often focused on either task separately, ignoring their correlation. This work proposes a co-evolutionary abnormality detection and report generation (CoE-DG) framework. The framework utilizes both fully labeled (with bounding box annotations and clinical reports) and weakly labeled (with reports only) data to achieve mutual promotion between the abnormality detection and report generation tasks. Specifically, we introduce a bi-directional information interaction strategy with generator-guided information propagation (GIP) and detector-guided information propagation (DIP). For semi-supervised abnormality detection, GIP takes the informative feature extracted by the generator as an auxiliary input to the detector and uses the generator's prediction to refine the detector's pseudo labels. We further propose an intra-image-modal self-adaptive non-maximum suppression module (SA-NMS). This module dynamically rectifies pseudo detection labels generated by the teacher detection model with high-confidence predictions by the student.Inversely, for report generation, DIP takes the abnormalities' categories and locations predicted by the detector as input and guidance for the generator to improve the generated reports.
Federated Modality-specific Encoders and Multimodal Anchors for Personalized Brain Tumor Segmentation
Mar 18, 2024



Most existing federated learning (FL) methods for medical image analysis only considered intramodal heterogeneity, limiting their applicability to multimodal imaging applications. In practice, it is not uncommon that some FL participants only possess a subset of the complete imaging modalities, posing inter-modal heterogeneity as a challenge to effectively training a global model on all participants' data. In addition, each participant would expect to obtain a personalized model tailored for its local data characteristics from the FL in such a scenario. In this work, we propose a new FL framework with federated modality-specific encoders and multimodal anchors (FedMEMA) to simultaneously address the two concurrent issues. Above all, FedMEMA employs an exclusive encoder for each modality to account for the inter-modal heterogeneity in the first place. In the meantime, while the encoders are shared by the participants, the decoders are personalized to meet individual needs. Specifically, a server with full-modal data employs a fusion decoder to aggregate and fuse representations from all modality-specific encoders, thus bridging the modalities to optimize the encoders via backpropagation reversely. Meanwhile, multiple anchors are extracted from the fused multimodal representations and distributed to the clients in addition to the encoder parameters. On the other end, the clients with incomplete modalities calibrate their missing-modal representations toward the global full-modal anchors via scaled dot-product cross-attention, making up the information loss due to absent modalities while adapting the representations of present ones. FedMEMA is validated on the BraTS 2020 benchmark for multimodal brain tumor segmentation. Results show that it outperforms various up-to-date methods for multimodal and personalized FL and that its novel designs are effective. Our code is available.
You've Got Two Teachers: Co-evolutionary Image and Report Distillation for Semi-supervised Anatomical Abnormality Detection in Chest X-ray
Jul 18, 2023Chest X-ray (CXR) anatomical abnormality detection aims at localizing and characterising cardiopulmonary radiological findings in the radiographs, which can expedite clinical workflow and reduce observational oversights. Most existing methods attempted this task in either fully supervised settings which demanded costly mass per-abnormality annotations, or weakly supervised settings which still lagged badly behind fully supervised methods in performance. In this work, we propose a co-evolutionary image and report distillation (CEIRD) framework, which approaches semi-supervised abnormality detection in CXR by grounding the visual detection results with text-classified abnormalities from paired radiology reports, and vice versa. Concretely, based on the classical teacher-student pseudo label distillation (TSD) paradigm, we additionally introduce an auxiliary report classification model, whose prediction is used for report-guided pseudo detection label refinement (RPDLR) in the primary vision detection task. Inversely, we also use the prediction of the vision detection model for abnormality-guided pseudo classification label refinement (APCLR) in the auxiliary report classification task, and propose a co-evolution strategy where the vision and report models mutually promote each other with RPDLR and APCLR performed alternatively. To this end, we effectively incorporate the weak supervision by reports into the semi-supervised TSD pipeline. Besides the cross-modal pseudo label refinement, we further propose an intra-image-modal self-adaptive non-maximum suppression, where the pseudo detection labels generated by the teacher vision model are dynamically rectified by high-confidence predictions by the student. Experimental results on the public MIMIC-CXR benchmark demonstrate CEIRD's superior performance to several up-to-date weakly and semi-supervised methods.
M3AE: Multimodal Representation Learning for Brain Tumor Segmentation with Missing Modalities
Mar 09, 2023



Multimodal magnetic resonance imaging (MRI) provides complementary information for sub-region analysis of brain tumors. Plenty of methods have been proposed for automatic brain tumor segmentation using four common MRI modalities and achieved remarkable performance. In practice, however, it is common to have one or more modalities missing due to image corruption, artifacts, acquisition protocols, allergy to contrast agents, or simply cost. In this work, we propose a novel two-stage framework for brain tumor segmentation with missing modalities. In the first stage, a multimodal masked autoencoder (M3AE) is proposed, where both random modalities (i.e., modality dropout) and random patches of the remaining modalities are masked for a reconstruction task, for self-supervised learning of robust multimodal representations against missing modalities. To this end, we name our framework M3AE. Meanwhile, we employ model inversion to optimize a representative full-modal image at marginal extra cost, which will be used to substitute for the missing modalities and boost performance during inference. Then in the second stage, a memory-efficient self distillation is proposed to distill knowledge between heterogenous missing-modal situations while fine-tuning the model for supervised segmentation. Our M3AE belongs to the 'catch-all' genre where a single model can be applied to all possible subsets of modalities, thus is economic for both training and deployment. Extensive experiments on BraTS 2018 and 2020 datasets demonstrate its superior performance to existing state-of-the-art methods with missing modalities, as well as the efficacy of its components. Our code is available at: https://github.com/ccarliu/m3ae.
An interpretable imbalanced semi-supervised deep learning framework for improving differential diagnosis of skin diseases
Nov 20, 2022



Dermatological diseases are among the most common disorders worldwide. This paper presents the first study of the interpretability and imbalanced semi-supervised learning of the multiclass intelligent skin diagnosis framework (ISDL) using 58,457 skin images with 10,857 unlabeled samples. Pseudo-labelled samples from minority classes have a higher probability at each iteration of class-rebalancing self-training, thereby promoting the utilization of unlabeled samples to solve the class imbalance problem. Our ISDL achieved a promising performance with an accuracy of 0.979, sensitivity of 0.975, specificity of 0.973, macro-F1 score of 0.974 and area under the receiver operating characteristic curve (AUC) of 0.999 for multi-label skin disease classification. The Shapley Additive explanation (SHAP) method is combined with our ISDL to explain how the deep learning model makes predictions. This finding is consistent with the clinical diagnosis. We also proposed a sampling distribution optimisation strategy to select pseudo-labelled samples in a more effective manner using ISDLplus. Furthermore, it has the potential to relieve the pressure placed on professional doctors, as well as help with practical issues associated with a shortage of such doctors in rural areas.
Lesion Guided Explainable Few Weak-shot Medical Report Generation
Nov 17, 2022Medical images are widely used in clinical practice for diagnosis. Automatically generating interpretable medical reports can reduce radiologists' burden and facilitate timely care. However, most existing approaches to automatic report generation require sufficient labeled data for training. In addition, the learned model can only generate reports for the training classes, lacking the ability to adapt to previously unseen novel diseases. To this end, we propose a lesion guided explainable few weak-shot medical report generation framework that learns correlation between seen and novel classes through visual and semantic feature alignment, aiming to generate medical reports for diseases not observed in training. It integrates a lesion-centric feature extractor and a Transformer-based report generation module. Concretely, the lesion-centric feature extractor detects the abnormal regions and learns correlations between seen and novel classes with multi-view (visual and lexical) embeddings. Then, features of the detected regions and corresponding embeddings are concatenated as multi-view input to the report generation module for explainable report generation, including text descriptions and corresponding abnormal regions detected in the images. We conduct experiments on FFA-IR, a dataset providing explainable annotations, showing that our framework outperforms others on report generation for novel diseases.
Unsupervised Representation Learning Meets Pseudo-Label Supervised Self-Distillation: A New Approach to Rare Disease Classification
Oct 09, 2021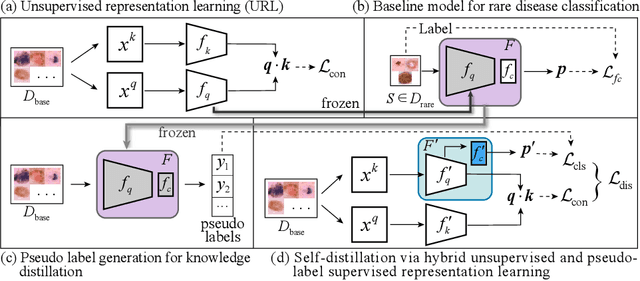
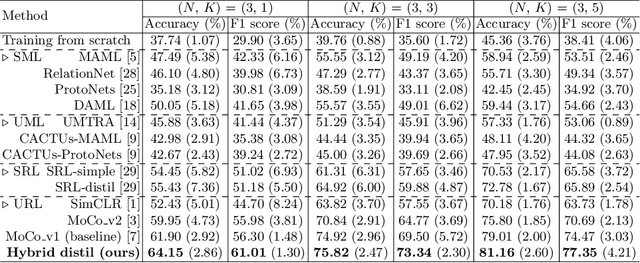

Rare diseases are characterized by low prevalence and are often chronically debilitating or life-threatening. Imaging-based classification of rare diseases is challenging due to the severe shortage in training examples. Few-shot learning (FSL) methods tackle this challenge by extracting generalizable prior knowledge from a large base dataset of common diseases and normal controls, and transferring the knowledge to rare diseases. Yet, most existing methods require the base dataset to be labeled and do not make full use of the precious examples of the rare diseases. To this end, we propose in this work a novel hybrid approach to rare disease classification, featuring two key novelties targeted at the above drawbacks. First, we adopt the unsupervised representation learning (URL) based on self-supervising contrastive loss, whereby to eliminate the overhead in labeling the base dataset. Second, we integrate the URL with pseudo-label supervised classification for effective self-distillation of the knowledge about the rare diseases, composing a hybrid approach taking advantages of both unsupervised and (pseudo-) supervised learning on the base dataset. Experimental results on classification of rare skin lesions show that our hybrid approach substantially outperforms existing FSL methods (including those using fully supervised base dataset) for rare disease classification via effective integration of the URL and pseudo-label driven self-distillation, thus establishing a new state of the art.