 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Object Detection via Local-global Contrastive Learning
Oct 07, 2024
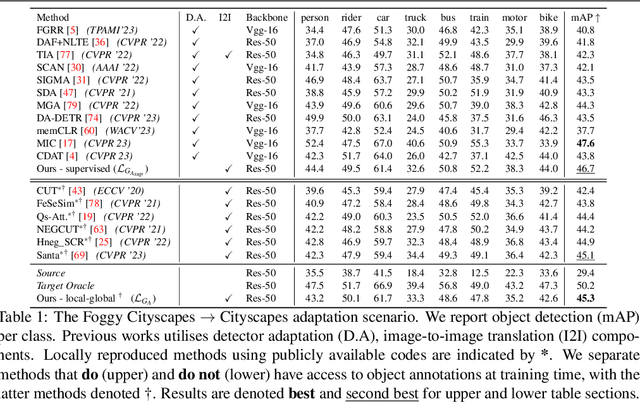
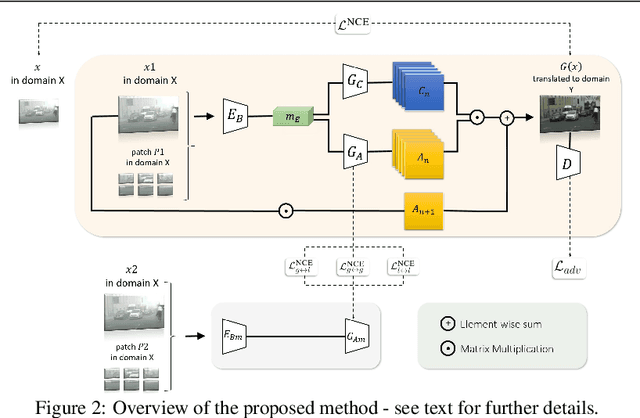
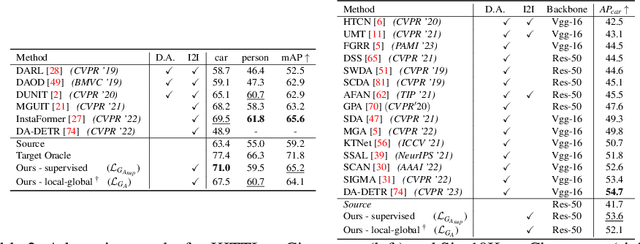
Visual domain gaps often impact object detection performance. Image-to-image translation can mitigate this effect, where contrastive approaches enable learning of the image-to-image mapping under unsupervised regimes. However, existing methods often fail to handle content-rich scenes with multiple object instances, which manifests in unsatisfactory detection performance. Sensitivity to such instance-level content is typically only gained through object annotations, which can be expensive to obtain. Towards addressing this issue, we present a novel image-to-image translation method that specifically targets cross-domain object detection. We formulate our approach as a contrastive learning framework with an inductive prior that optimises the appearance of object instances through spatial attention masks, implicitly delineating the scene into foreground regions associated with the target object instances and background non-object regions. Instead of relying on object annotations to explicitly account for object instances during translation, our approach learns to represent objects by contrasting local-global information. This affords investigation of an under-explored challenge: obtaining performant detection, under domain shifts, without relying on object annotations nor detector model fine-tuning. We experiment with multiple cross-domain object detection settings across three challenging benchmarks and report state-of-the-art performance. Project page: https://local-global-detection.github.io