 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Mixture-of-Experts Redundancy Unlocks Multimodal Generative Abilities
Apr 01, 2025In this work, we undertake the challenge of augmenting the existing generative capabilities of pre-trained text-only large language models (LLMs) with multi-modal generation capability while satisfying two core constraints: C1 preserving the preservation of original language generative capabilities with negligible performance degradation, and C2 adhering to a small parameter budget to learn the new modality, ensuring scalability and efficiency. In contrast to current approaches that add dedicated modules, thereby significantly increasing the parameter count, we propose a method that leverages the underutilized capacity inherent in deep models. Specifically, we exploit the parameter redundancy within Mixture-of-Experts (MoEs) as a source of additional capacity for learning a new modality, enabling better parameter efficiency (C1). Moreover, we preserve the original language generation capabilities by applying low-rank adaptation exclusively to the tokens of the new modality (C2). Furthermore, we introduce a novel parameter initialization scheme based on the Gromov-Wasserstein distance to improve convergence and training stability. Through an extensive analysis of the routing mechanism, we uncover the emergence of modality-specific pathways and decreased redundancy within the experts that can efficiently unlock multi-modal generative capabilities. Overall, our method can be seamlessly applied to a wide range of contemporary LLMs, providing a new pathway for transitioning from uni-modal to multi-modal architectures.
Generating Compositional Scenes via Text-to-image RGBA Instance Generation
Nov 16, 2024



Text-to-image diffusion generative models can generate high quality images at the cost of tedious prompt engineering. Controllability can be improved by introducing layout conditioning, however existing methods lack layout editing ability and fine-grained control over object attributes. The concept of multi-layer generation holds great potential to address these limitations, however generating image instances concurrently to scene composition limits control over fine-grained object attributes, relative positioning in 3D space and scene manipulation abilities. In this work, we propose a novel multi-stage generation paradigm that is designed for fine-grained control, flexibility and interactivity. To ensure control over instance attributes, we devise a novel training paradigm to adapt a diffusion model to generate isolated scene components as RGBA images with transparency information. To build complex images, we employ these pre-generated instances and introduce a multi-layer composite generation process that smoothly assembles components in realistic scenes. Our experiments show that our RGBA diffusion model is capable of generating diverse and high quality instances with precise control over object attributes. Through multi-layer composition, we demonstrate that our approach allows to build and manipulate images from highly complex prompts with fine-grained control over object appearance and location, granting a higher degree of control than competing methods.
Improving Object Detection via Local-global Contrastive Learning
Oct 07, 2024
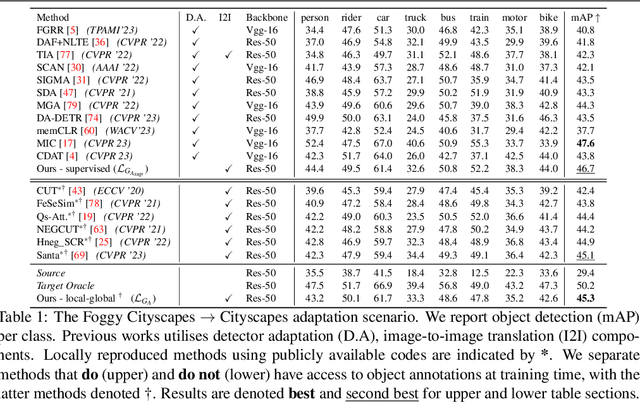
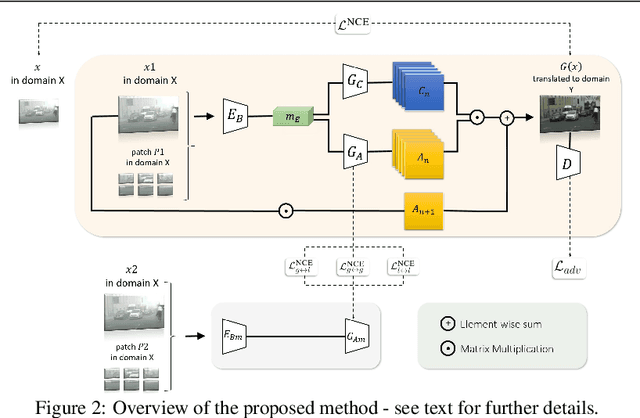
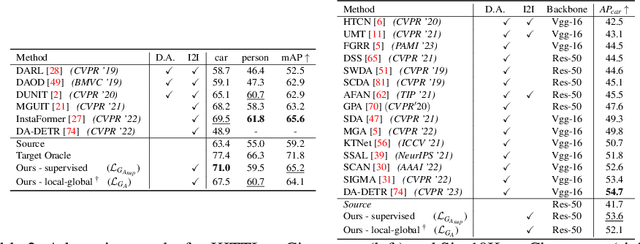
Visual domain gaps often impact object detection performance. Image-to-image translation can mitigate this effect, where contrastive approaches enable learning of the image-to-image mapping under unsupervised regimes. However, existing methods often fail to handle content-rich scenes with multiple object instances, which manifests in unsatisfactory detection performance. Sensitivity to such instance-level content is typically only gained through object annotations, which can be expensive to obtain. Towards addressing this issue, we present a novel image-to-image translation method that specifically targets cross-domain object detection. We formulate our approach as a contrastive learning framework with an inductive prior that optimises the appearance of object instances through spatial attention masks, implicitly delineating the scene into foreground regions associated with the target object instances and background non-object regions. Instead of relying on object annotations to explicitly account for object instances during translation, our approach learns to represent objects by contrasting local-global information. This affords investigation of an under-explored challenge: obtaining performant detection, under domain shifts, without relying on object annotations nor detector model fine-tuning. We experiment with multiple cross-domain object detection settings across three challenging benchmarks and report state-of-the-art performance. Project page: https://local-global-detection.github.io
MULAN: A Multi Layer Annotated Dataset for Controllable Text-to-Image Generation
Apr 03, 2024



Text-to-image generation has achieved astonishing results, yet precise spatial controllability and prompt fidelity remain highly challenging. This limitation is typically addressed through cumbersome prompt engineering, scene layout conditioning, or image editing techniques which often require hand drawn masks. Nonetheless, pre-existing works struggle to take advantage of the natural instance-level compositionality of scenes due to the typically flat nature of rasterized RGB output images. Towards adressing this challenge, we introduce MuLAn: a novel dataset comprising over 44K MUlti-Layer ANnotations of RGB images as multilayer, instance-wise RGBA decompositions, and over 100K instance images. To build MuLAn, we developed a training free pipeline which decomposes a monocular RGB image into a stack of RGBA layers comprising of background and isolated instances. We achieve this through the use of pretrained general-purpose models, and by developing three modules: image decomposition for instance discovery and extraction, instance completion to reconstruct occluded areas, and image re-assembly. We use our pipeline to create MuLAn-COCO and MuLAn-LAION datasets, which contain a variety of image decompositions in terms of style, composition and complexity. With MuLAn, we provide the first photorealistic resource providing instance decomposition and occlusion information for high quality images, opening up new avenues for text-to-image generative AI research. With this, we aim to encourage the development of novel generation and editing technology, in particular layer-wise solutions. MuLAn data resources are available at https://MuLAn-dataset.github.io/.
Optimisation-Based Multi-Modal Semantic Image Editing
Nov 28, 2023



Image editing affords increased control over the aesthetics and content of generated images. Pre-existing works focus predominantly on text-based instructions to achieve desired image modifications, which limit edit precision and accuracy. In this work, we propose an inference-time editing optimisation, designed to extend beyond textual edits to accommodate multiple editing instruction types (e.g. spatial layout-based; pose, scribbles, edge maps). We propose to disentangle the editing task into two competing subtasks: successful local image modifications and global content consistency preservation, where subtasks are guided through two dedicated loss functions. By allowing to adjust the influence of each loss function, we build a flexible editing solution that can be adjusted to user preferences. We evaluate our method using text, pose and scribble edit conditions, and highlight our ability to achieve complex edits, through both qualitative and quantitative experiments.
Learning to Name Classes for Vision and Language Models
Apr 04, 2023Large scale vision and language models can achieve impressive zero-shot recognition performance by mapping class specific text queries to image content. Two distinct challenges that remain however, are high sensitivity to the choice of handcrafted class names that define queries, and the difficulty of adaptation to new, smaller datasets. Towards addressing these problems, we propose to leverage available data to learn, for each class, an optimal word embedding as a function of the visual content. By learning new word embeddings on an otherwise frozen model, we are able to retain zero-shot capabilities for new classes, easily adapt models to new datasets, and adjust potentially erroneous, non-descriptive or ambiguous class names. We show that our solution can easily be integrated in image classification and object detection pipelines, yields significant performance gains in multiple scenarios and provides insights into model biases and labelling errors.
Content-Diverse Comparisons improve IQA
Nov 09, 2022



Image quality assessment (IQA) forms a natural and often straightforward undertaking for humans, yet effective automation of the task remains highly challenging. Recent metrics from the deep learning community commonly compare image pairs during training to improve upon traditional metrics such as PSNR or SSIM. However, current comparisons ignore the fact that image content affects quality assessment as comparisons only occur between images of similar content. This restricts the diversity and number of image pairs that the model is exposed to during training. In this paper, we strive to enrich these comparisons with content diversity. Firstly, we relax comparison constraints, and compare pairs of images with differing content. This increases the variety of available comparisons. Secondly, we introduce listwise comparisons to provide a holistic view to the model. By including differentiable regularizers, derived from correlation coefficients, models can better adjust predicted scores relative to one another. Evaluation on multiple benchmarks, covering a wide range of distortions and image content, shows the effectiveness of our learning scheme for training image quality assessment models.
CLAD: A realistic Continual Learning benchmark for Autonomous Driving
Oct 07, 2022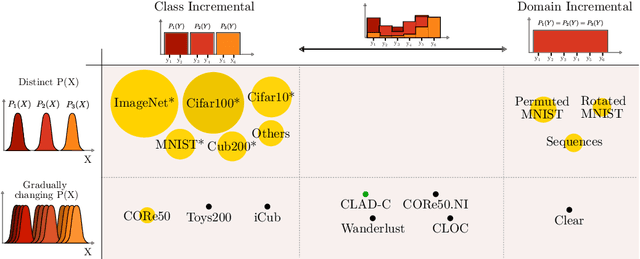

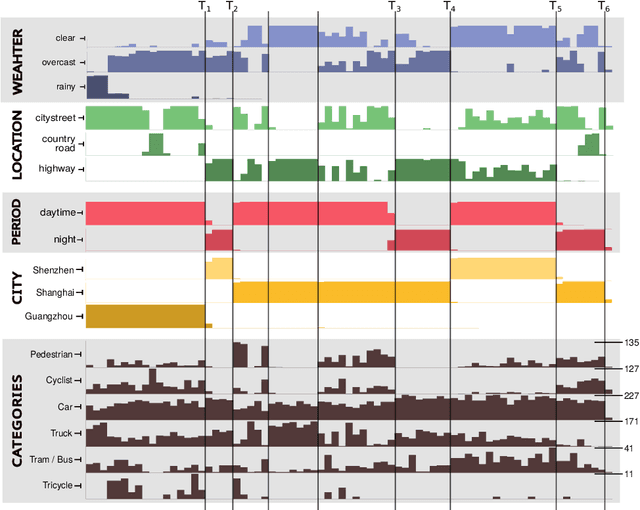
In this paper we describe the design and the ideas motivating a new Continual Learning benchmark for Autonomous Driving (CLAD), that focuses on the problems of object classification and object detection. The benchmark utilises SODA10M, a recently released large-scale dataset that concerns autonomous driving related problems. First, we review and discuss existing continual learning benchmarks, how they are related, and show that most are extreme cases of continual learning. To this end, we survey the benchmarks used in continual learning papers at three highly ranked computer vision conferences. Next, we introduce CLAD-C, an online classification benchmark realised through a chronological data stream that poses both class and domain incremental challenges; and CLAD-D, a domain incremental continual object detection benchmark. We examine the inherent difficulties and challenges posed by the benchmark, through a survey of the techniques and methods used by the top-3 participants in a CLAD-challenge workshop at ICCV 2021. We conclude with possible pathways to improve the current continual learning state of the art, and which directions we deem promising for future research.
Re-examining Distillation For Continual Object Detection
Apr 04, 2022
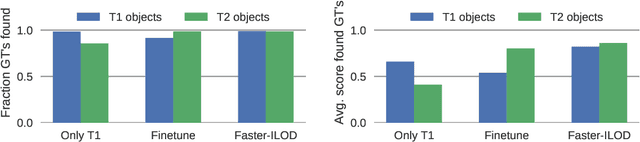


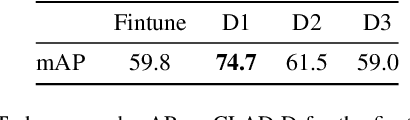
Training models continually to detect and classify objects, from new classes and new domains, remains an open problem. In this work, we conduct a thorough analysis of why and how object detection models forget catastrophically. We focus on distillation-based approaches in two-stage networks; the most-common strategy employed in contemporary continual object detection work.Distillation aims to transfer the knowledge of a model trained on previous tasks -- the teacher -- to a new model -- the student -- while it learns the new task. We show that this works well for the region proposal network, but that wrong, yet overly confident teacher predictions prevent student models from effective learning of the classification head. Our analysis provides a foundation that allows us to propose improvements for existing techniques by detecting incorrect teacher predictions, based on current ground-truth labels, and by employing an adaptive Huber loss as opposed to the mean squared error for the distillation loss in the classification heads. We evidence that our strategy works not only in a class incremental setting, but also in domain incremental settings, which constitute a realistic context, likely to be the setting of representative real-world problems.
Long-tail Recognition via Compositional Knowledge Transfer
Dec 13, 2021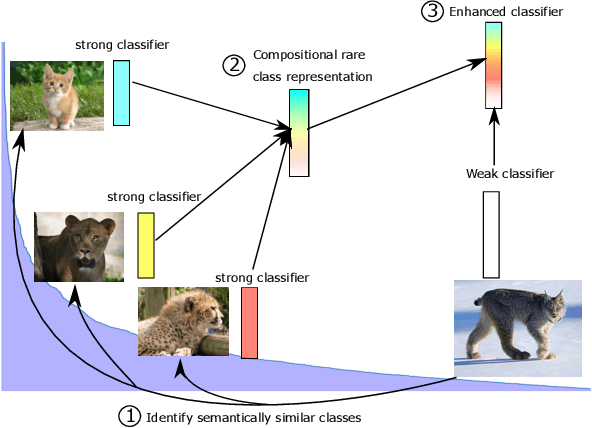
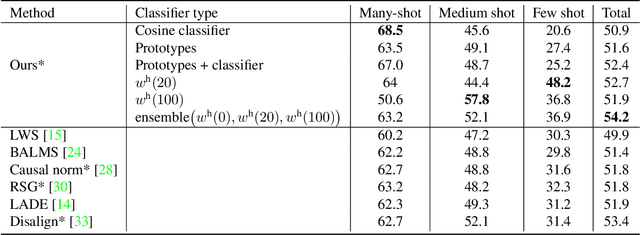
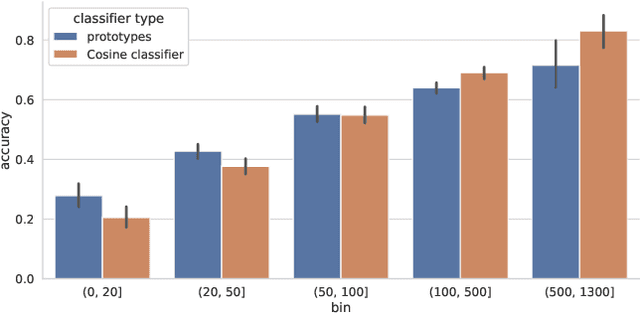
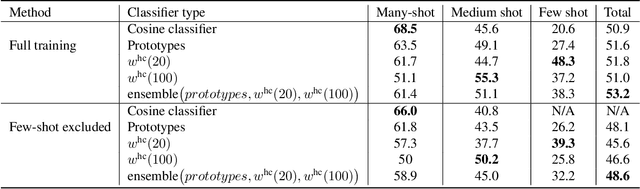
In this work, we introduce a novel strategy for long-tail recognition that addresses the tail classes' few-shot problem via training-free knowledge transfer. Our objective is to transfer knowledge acquired from information-rich common classes to semantically similar, and yet data-hungry, rare classes in order to obtain stronger tail class representations. We leverage the fact that class prototypes and learned cosine classifiers provide two different, complementary representations of class cluster centres in feature space, and use an attention mechanism to select and recompose learned classifier features from common classes to obtain higher quality rare class representations. Our knowledge transfer process is training free, reducing overfitting risks, and can afford continual extension of classifiers to new classes. Experiments show that our approach can achieve significant performance boosts on rare classes while maintaining robust common class performance, outperforming directly comparable state-of-the-art models.