 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent-Diverse Comparisons improve IQA
Nov 09, 2022



Image quality assessment (IQA) forms a natural and often straightforward undertaking for humans, yet effective automation of the task remains highly challenging. Recent metrics from the deep learning community commonly compare image pairs during training to improve upon traditional metrics such as PSNR or SSIM. However, current comparisons ignore the fact that image content affects quality assessment as comparisons only occur between images of similar content. This restricts the diversity and number of image pairs that the model is exposed to during training. In this paper, we strive to enrich these comparisons with content diversity. Firstly, we relax comparison constraints, and compare pairs of images with differing content. This increases the variety of available comparisons. Secondly, we introduce listwise comparisons to provide a holistic view to the model. By including differentiable regularizers, derived from correlation coefficients, models can better adjust predicted scores relative to one another. Evaluation on multiple benchmarks, covering a wide range of distortions and image content, shows the effectiveness of our learning scheme for training image quality assessment models.
NTIRE 2021 Challenge on Perceptual Image Quality Assessment
May 11, 2021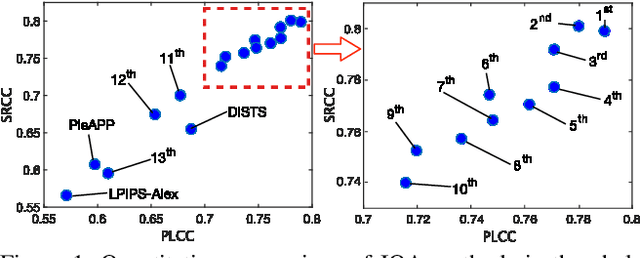
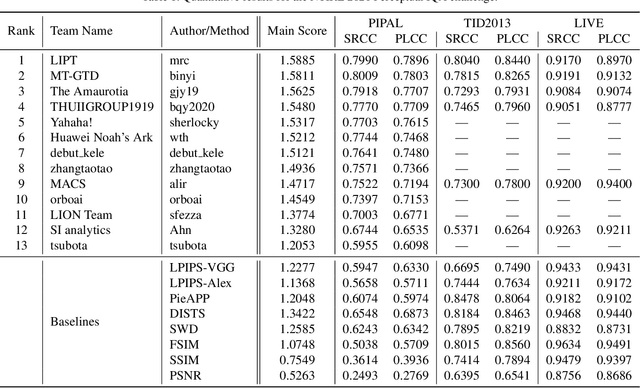

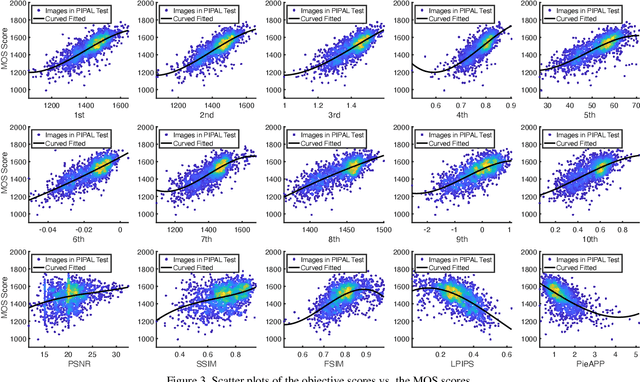
This paper reports on the NTIRE 2021 challenge on perceptual image quality assessment (IQA), held in conjunction with the New Trends in Image Restoration and Enhancement workshop (NTIRE) workshop at CVPR 2021. As a new type of image processing technology, perceptual image processing algorithms based on Generative Adversarial Networks (GAN) have produced images with more realistic textures. These output images have completely different characteristics from traditional distortions, thus pose a new challenge for IQA methods to evaluate their visual quality. In comparison with previous IQA challenges, the training and testing datasets in this challenge include the outputs of perceptual image processing algorithms and the corresponding subjective scores. Thus they can be used to develop and evaluate IQA methods on GAN-based distortions. The challenge has 270 registered participants in total. In the final testing stage, 13 participating teams submitted their models and fact sheets. Almost all of them have achieved much better results than existing IQA methods, while the winning method can demonstrate state-of-the-art performance.
Deep Hashing with Hash-Consistent Large Margin Proxy Embeddings
Jul 27, 2020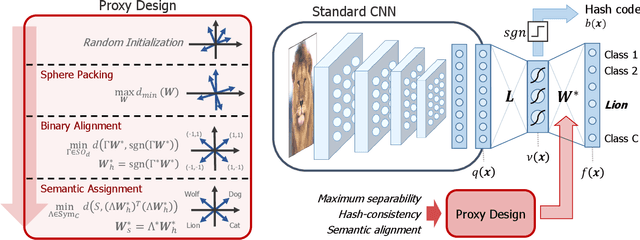
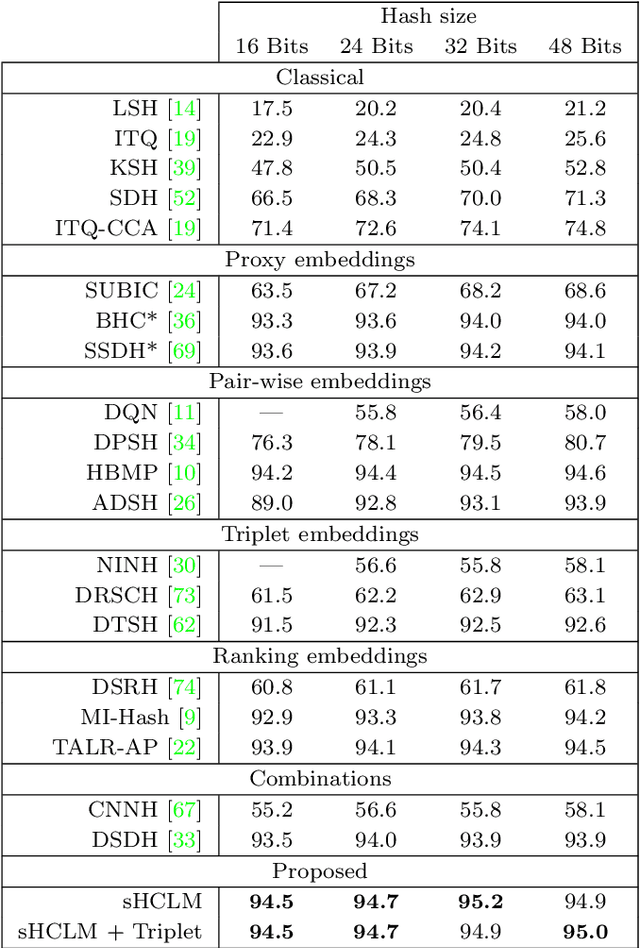
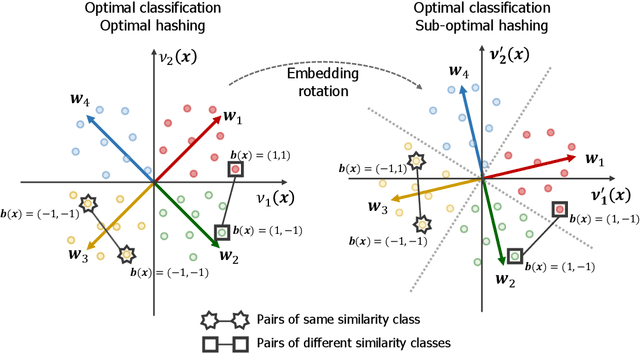
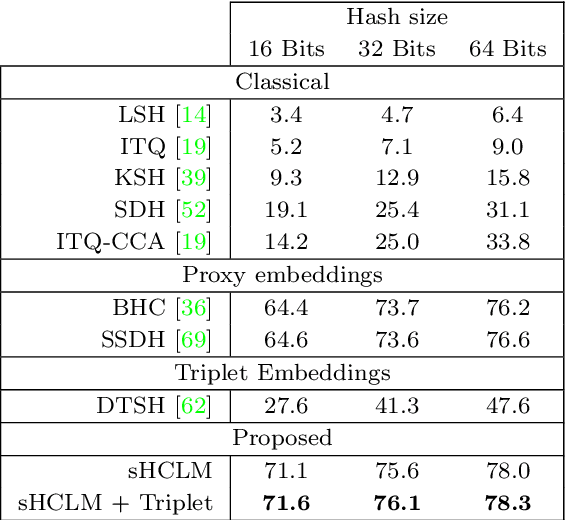
Image hash codes are produced by binarizing the embeddings of convolutional neural networks (CNN) trained for either classification or retrieval. While proxy embeddings achieve good performance on both tasks, they are non-trivial to binarize, due to a rotational ambiguity that encourages non-binary embeddings. The use of a fixed set of proxies (weights of the CNN classification layer) is proposed to eliminate this ambiguity, and a procedure to design proxy sets that are nearly optimal for both classification and hashing is introduced. The resulting hash-consistent large margin (HCLM) proxies are shown to encourage saturation of hashing units, thus guaranteeing a small binarization error, while producing highly discriminative hash-codes. A semantic extension (sHCLM), aimed to improve hashing performance in a transfer scenario, is also proposed. Extensive experiments show that sHCLM embeddings achieve significant improvements over state-of-the-art hashing procedures on several small and large datasets, both within and beyond the set of training classes.