 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Attribute-Based Measure of Video Complexity
May 30, 2026A new framework for the estimation of the complexity posed by video-question pairs to video-LLMs, Video Attribute-Based Complexity (VideoABC), is proposed. Video complexity is defined as the probability of failure of a video-LLM for a given video-question pair. VideoABC is a non-parametric complexity measure, using a reference video dataset and a pre-defined vocabulary of video attributes informative of complexity, \eg the scene complexity or the speed of the video event informative of the question. In a training phase, reference videos are projected into the space of these attributes, which is then quantized. The expected ABC of each quantization cell is then computed. Given a new video and its projection into the attribute space, complexity is estimated by the expected ABC of the associated quantization cell. To enable the use of VideoABC with small reference video datasets, two quantizers are combined: a k-means quantizer that enables accurate complexity estimates for samples in the distribution of the reference dataset and a universal lattice quantizer that guarantees generalization to out-of-distribution samples. A synthetic video generation procedure, inspired by target-distractor manipulations of psychophysics studies, is proposed to populate the cells of the lattice quantizer during training, enabling the computation of their expected ABCs. Experimental results show that VideoABCis effective even with very low-dimensional attribute representations, substantially outperforming approaches like `video-LLM as judge' with much less complexity. Finally, the explainable nature of the VideoABC score, in terms of well-defined attributes, is shown to provide insights on how the attribute composition of benchmarks affects their complexity.
A Very Big Video Reasoning Suite
Feb 24, 2026Rapid progress in video models has largely focused on visual quality, leaving their reasoning capabilities underexplored. Video reasoning grounds intelligence in spatiotemporally consistent visual environments that go beyond what text can naturally capture, enabling intuitive reasoning over spatiotemporal structure such as continuity, interaction, and causality. However, systematically studying video reasoning and its scaling behavior is hindered by the lack of large-scale training data. To address this gap, we introduce the Very Big Video Reasoning (VBVR) Dataset, an unprecedentedly large-scale resource spanning 200 curated reasoning tasks following a principled taxonomy and over one million video clips, approximately three orders of magnitude larger than existing datasets. We further present VBVR-Bench, a verifiable evaluation framework that moves beyond model-based judging by incorporating rule-based, human-aligned scorers, enabling reproducible and interpretable diagnosis of video reasoning capabilities. Leveraging the VBVR suite, we conduct one of the first large-scale scaling studies of video reasoning and observe early signs of emergent generalization to unseen reasoning tasks. Together, VBVR lays a foundation for the next stage of research in generalizable video reasoning. The data, benchmark toolkit, and models are publicly available at https://video-reason.com/ .
Leveraging Data to Say No: Memory Augmented Plug-and-Play Selective Prediction
Jan 30, 2026Selective prediction aims to endow predictors with a reject option, to avoid low confidence predictions. However, existing literature has primarily focused on closed-set tasks, such as visual question answering with predefined options or fixed-category classification. This paper considers selective prediction for visual language foundation models, addressing a taxonomy of tasks ranging from closed to open set and from finite to unbounded vocabularies, as in image captioning. We seek training-free approaches of low-complexity, applicable to any foundation model and consider methods based on external vision-language model embeddings, like CLIP. This is denoted as Plug-and-Play Selective Prediction (PaPSP). We identify two key challenges: (1) instability of the visual-language representations, leading to high variance in image-text embeddings, and (2) poor calibration of similarity scores. To address these issues, we propose a memory augmented PaPSP (MA-PaPSP) model, which augments PaPSP with a retrieval dataset of image-text pairs. This is leveraged to reduce embedding variance by averaging retrieved nearest-neighbor pairs and is complemented by the use of contrastive normalization to improve score calibration. Through extensive experiments on multiple datasets, we show that MA-PaPSP outperforms PaPSP and other selective prediction baselines for selective captioning, image-text matching, and fine-grained classification. Code is publicly available at https://github.com/kingston-aditya/MA-PaPSP.
EgoPrivacy: What Your First-Person Camera Says About You?
Jun 13, 2025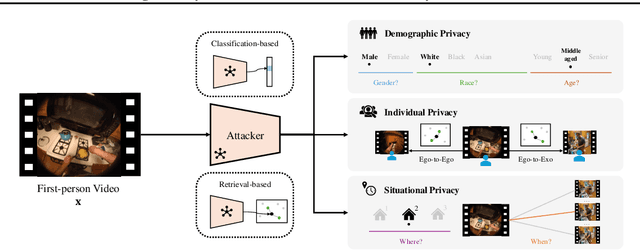
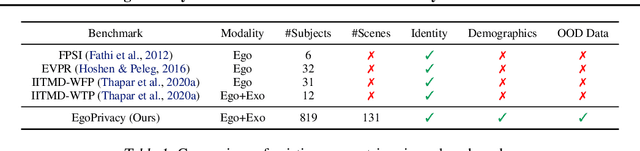
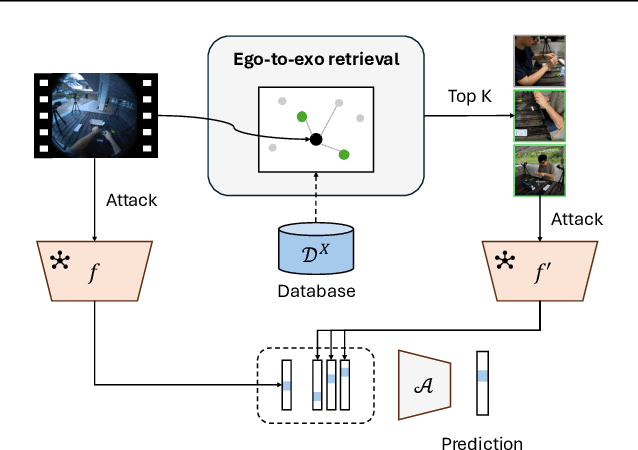
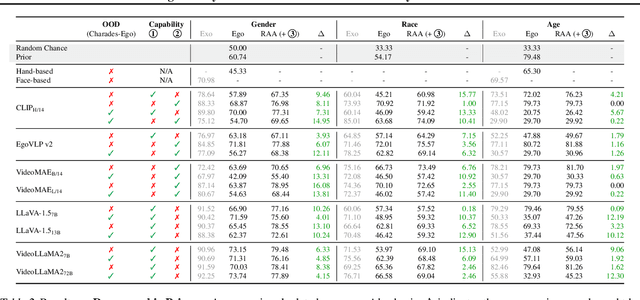
While the rapid proliferation of wearable cameras has raised significant concerns about egocentric video privacy, prior work has largely overlooked the unique privacy threats posed to the camera wearer. This work investigates the core question: How much privacy information about the camera wearer can be inferred from their first-person view videos? We introduce EgoPrivacy, the first large-scale benchmark for the comprehensive evaluation of privacy risks in egocentric vision. EgoPrivacy covers three types of privacy (demographic, individual, and situational), defining seven tasks that aim to recover private information ranging from fine-grained (e.g., wearer's identity) to coarse-grained (e.g., age group). To further emphasize the privacy threats inherent to egocentric vision, we propose Retrieval-Augmented Attack, a novel attack strategy that leverages ego-to-exo retrieval from an external pool of exocentric videos to boost the effectiveness of demographic privacy attacks. An extensive comparison of the different attacks possible under all threat models is presented, showing that private information of the wearer is highly susceptible to leakage. For instance, our findings indicate that foundation models can effectively compromise wearer privacy even in zero-shot settings by recovering attributes such as identity, scene, gender, and race with 70-80% accuracy. Our code and data are available at https://github.com/williamium3000/ego-privacy.
EditAR: Unified Conditional Generation with Autoregressive Models
Jan 08, 2025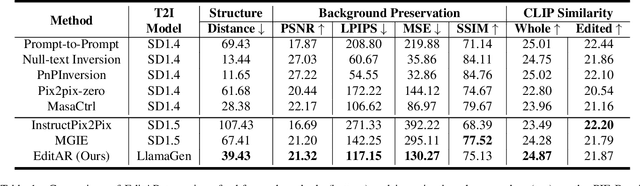
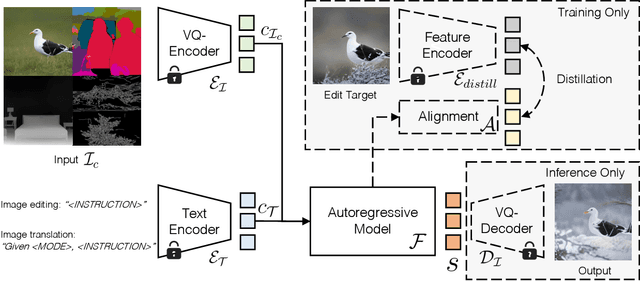
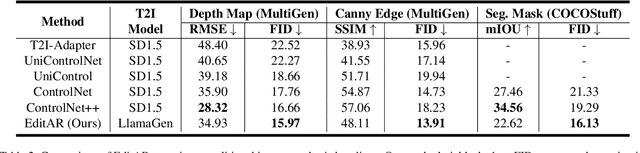

Recent progress in controllable image generation and editing is largely driven by diffusion-based methods. Although diffusion models perform exceptionally well in specific tasks with tailored designs, establishing a unified model is still challenging. In contrast, autoregressive models inherently feature a unified tokenized representation, which simplifies the creation of a single foundational model for various tasks. In this work, we propose EditAR, a single unified autoregressive framework for a variety of conditional image generation tasks, e.g., image editing, depth-to-image, edge-to-image, segmentation-to-image. The model takes both images and instructions as inputs, and predicts the edited images tokens in a vanilla next-token paradigm. To enhance the text-to-image alignment, we further propose to distill the knowledge from foundation models into the autoregressive modeling process. We evaluate its effectiveness across diverse tasks on established benchmarks, showing competitive performance to various state-of-the-art task-specific methods. Project page: https://jitengmu.github.io/EditAR/
IntroStyle: Training-Free Introspective Style Attribution using Diffusion Features
Dec 19, 2024



Text-to-image (T2I) models have gained widespread adoption among content creators and the general public. However, this has sparked significant concerns regarding data privacy and copyright infringement among artists. Consequently, there is an increasing demand for T2I models to incorporate mechanisms that prevent the generation of specific artistic styles, thereby safeguarding intellectual property rights. Existing methods for style extraction typically necessitate the collection of custom datasets and the training of specialized models. This, however, is resource-intensive, time-consuming, and often impractical for real-time applications. Moreover, it may not adequately address the dynamic nature of artistic styles and the rapidly evolving landscape of digital art. We present a novel, training-free framework to solve the style attribution problem, using the features produced by a diffusion model alone, without any external modules or retraining. This is denoted as introspective style attribution (IntroStyle) and demonstrates superior performance to state-of-the-art models for style retrieval. We also introduce a synthetic dataset of Style Hacks (SHacks) to isolate artistic style and evaluate fine-grained style attribution performance.
Improving image synthesis with diffusion-negative sampling
Nov 08, 2024



For image generation with diffusion models (DMs), a negative prompt n can be used to complement the text prompt p, helping define properties not desired in the synthesized image. While this improves prompt adherence and image quality, finding good negative prompts is challenging. We argue that this is due to a semantic gap between humans and DMs, which makes good negative prompts for DMs appear unintuitive to humans. To bridge this gap, we propose a new diffusion-negative prompting (DNP) strategy. DNP is based on a new procedure to sample images that are least compliant with p under the distribution of the DM, denoted as diffusion-negative sampling (DNS). Given p, one such image is sampled, which is then translated into natural language by the user or a captioning model, to produce the negative prompt n*. The pair (p, n*) is finally used to prompt the DM. DNS is straightforward to implement and requires no training. Experiments and human evaluations show that DNP performs well both quantitatively and qualitatively and can be easily combined with several DM variants.
Pseudo-Probability Unlearning: Towards Efficient and Privacy-Preserving Machine Unlearning
Nov 04, 2024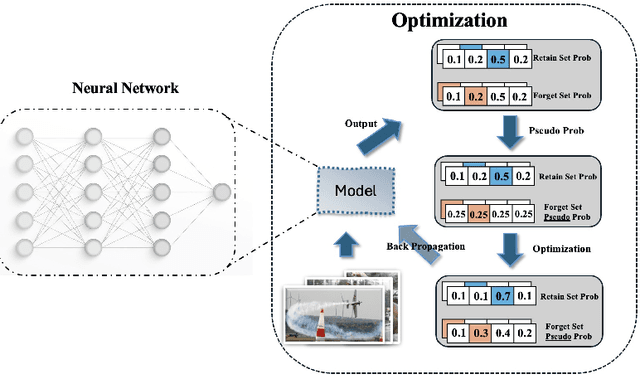
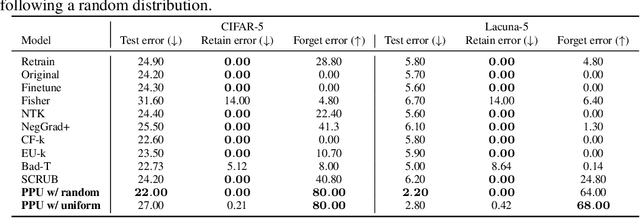
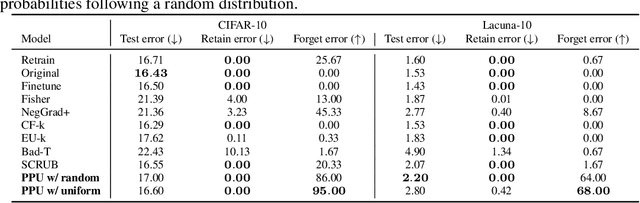
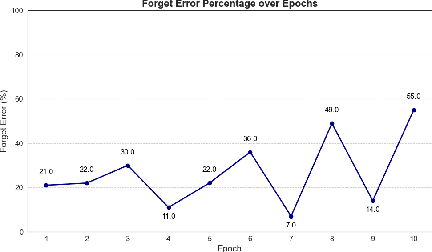
Machine unlearning--enabling a trained model to forget specific data--is crucial for addressing biased data and adhering to privacy regulations like the General Data Protection Regulation (GDPR)'s "right to be forgotten". Recent works have paid little attention to privacy concerns, leaving the data intended for forgetting vulnerable to membership inference attacks. Moreover, they often come with high computational overhead. In this work, we propose Pseudo-Probability Unlearning (PPU), a novel method that enables models to forget data efficiently and in a privacy-preserving manner. Our method replaces the final-layer output probabilities of the neural network with pseudo-probabilities for the data to be forgotten. These pseudo-probabilities follow either a uniform distribution or align with the model's overall distribution, enhancing privacy and reducing risk of membership inference attacks. Our optimization strategy further refines the predictive probability distributions and updates the model's weights accordingly, ensuring effective forgetting with minimal impact on the model's overall performance. Through comprehensive experiments on multiple benchmarks, our method achieves over 20% improvements in forgetting error compared to the state-of-the-art. Additionally, our method enhances privacy by preventing the forgotten set from being inferred to around random guesses.
Adapting Diffusion Models for Improved Prompt Compliance and Controllable Image Synthesis
Oct 29, 2024Recent advances in generative modeling with diffusion processes (DPs) enabled breakthroughs in image synthesis. Despite impressive image quality, these models have various prompt compliance problems, including low recall in generating multiple objects, difficulty in generating text in images, and meeting constraints like object locations and pose. For fine-grained editing and manipulation, they also require fine-grained semantic or instance maps that are tedious to produce manually. While prompt compliance can be enhanced by addition of loss functions at inference, this is time consuming and does not scale to complex scenes. To overcome these limitations, this work introduces a new family of \textit{Factor Graph Diffusion Models} (FG-DMs) that models the joint distribution of images and conditioning variables, such as semantic, sketch, depth or normal maps via a factor graph decomposition. This joint structure has several advantages, including support for efficient sampling based prompt compliance schemes, which produce images of high object recall, semi-automated fine-grained editing, text-based editing of conditions with noise inversion, explainability at intermediate levels, ability to produce labeled datasets for the training of downstream models such as segmentation or depth, training with missing data, and continual learning where new conditioning variables can be added with minimal or no modifications to the existing structure. We propose an implementation of FG-DMs by adapting a pre-trained Stable Diffusion (SD) model to implement all FG-DM factors, using only COCO dataset, and show that it is effective in generating images with 15\% higher recall than SD while retaining its generalization ability. We introduce an attention distillation loss that encourages consistency among the attention maps of all factors, improving the fidelity of the generated conditions and image.
Prompt Sliders for Fine-Grained Control, Editing and Erasing of Concepts in Diffusion Models
Sep 25, 2024


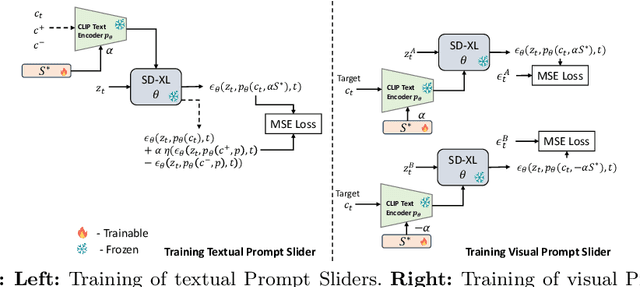
Diffusion models have recently surpassed GANs in image synthesis and editing, offering superior image quality and diversity. However, achieving precise control over attributes in generated images remains a challenge. Concept Sliders introduced a method for fine-grained image control and editing by learning concepts (attributes/objects). However, this approach adds parameters and increases inference time due to the loading and unloading of Low-Rank Adapters (LoRAs) used for learning concepts. These adapters are model-specific and require retraining for different architectures, such as Stable Diffusion (SD) v1.5 and SD-XL. In this paper, we propose a straightforward textual inversion method to learn concepts through text embeddings, which are generalizable across models that share the same text encoder, including different versions of the SD model. We refer to our method as Prompt Sliders. Besides learning new concepts, we also show that Prompt Sliders can be used to erase undesirable concepts such as artistic styles or mature content. Our method is 30% faster than using LoRAs because it eliminates the need to load and unload adapters and introduces no additional parameters aside from the target concept text embedding. Each concept embedding only requires 3KB of storage compared to the 8922KB or more required for each LoRA adapter, making our approach more computationally efficient. Project Page: https://deepaksridhar.github.io/promptsliders.github.io/