 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving image synthesis with diffusion-negative sampling
Nov 08, 2024



For image generation with diffusion models (DMs), a negative prompt n can be used to complement the text prompt p, helping define properties not desired in the synthesized image. While this improves prompt adherence and image quality, finding good negative prompts is challenging. We argue that this is due to a semantic gap between humans and DMs, which makes good negative prompts for DMs appear unintuitive to humans. To bridge this gap, we propose a new diffusion-negative prompting (DNP) strategy. DNP is based on a new procedure to sample images that are least compliant with p under the distribution of the DM, denoted as diffusion-negative sampling (DNS). Given p, one such image is sampled, which is then translated into natural language by the user or a captioning model, to produce the negative prompt n*. The pair (p, n*) is finally used to prompt the DM. DNS is straightforward to implement and requires no training. Experiments and human evaluations show that DNP performs well both quantitatively and qualitatively and can be easily combined with several DM variants.
Single-Stage Visual Relationship Learning using Conditional Queries
Jun 09, 2023Research in scene graph generation (SGG) usually considers two-stage models, that is, detecting a set of entities, followed by combining them and labeling all possible relationships. While showing promising results, the pipeline structure induces large parameter and computation overhead, and typically hinders end-to-end optimizations. To address this, recent research attempts to train single-stage models that are computationally efficient. With the advent of DETR, a set based detection model, one-stage models attempt to predict a set of subject-predicate-object triplets directly in a single shot. However, SGG is inherently a multi-task learning problem that requires modeling entity and predicate distributions simultaneously. In this paper, we propose Transformers with conditional queries for SGG, namely, TraCQ with a new formulation for SGG that avoids the multi-task learning problem and the combinatorial entity pair distribution. We employ a DETR-based encoder-decoder design and leverage conditional queries to significantly reduce the entity label space as well, which leads to 20% fewer parameters compared to state-of-the-art single-stage models. Experimental results show that TraCQ not only outperforms existing single-stage scene graph generation methods, it also beats many state-of-the-art two-stage methods on the Visual Genome dataset, yet is capable of end-to-end training and faster inference.
Learning of Visual Relations: The Devil is in the Tails
Aug 22, 2021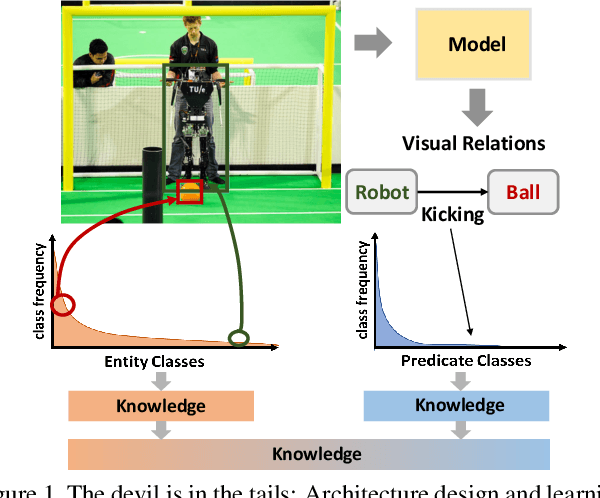
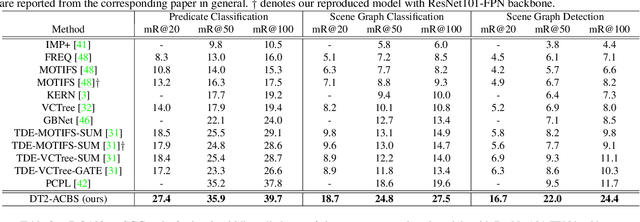
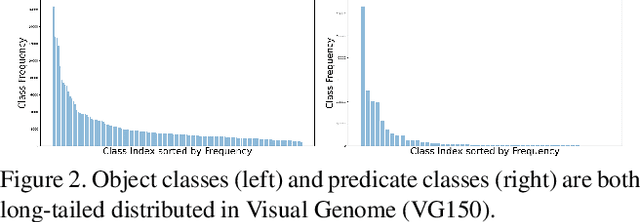

Significant effort has been recently devoted to modeling visual relations. This has mostly addressed the design of architectures, typically by adding parameters and increasing model complexity. However, visual relation learning is a long-tailed problem, due to the combinatorial nature of joint reasoning about groups of objects. Increasing model complexity is, in general, ill-suited for long-tailed problems due to their tendency to overfit. In this paper, we explore an alternative hypothesis, denoted the Devil is in the Tails. Under this hypothesis, better performance is achieved by keeping the model simple but improving its ability to cope with long-tailed distributions. To test this hypothesis, we devise a new approach for training visual relationships models, which is inspired by state-of-the-art long-tailed recognition literature. This is based on an iterative decoupled training scheme, denoted Decoupled Training for Devil in the Tails (DT2). DT2 employs a novel sampling approach, Alternating Class-Balanced Sampling (ACBS), to capture the interplay between the long-tailed entity and predicate distributions of visual relations. Results show that, with an extremely simple architecture, DT2-ACBS significantly outperforms much more complex state-of-the-art methods on scene graph generation tasks. This suggests that the development of sophisticated models must be considered in tandem with the long-tailed nature of the problem.
Image Segmentation Using Hybrid Representations
Apr 15, 2020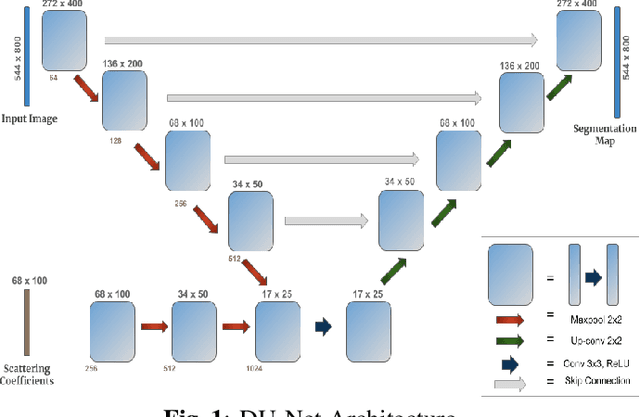
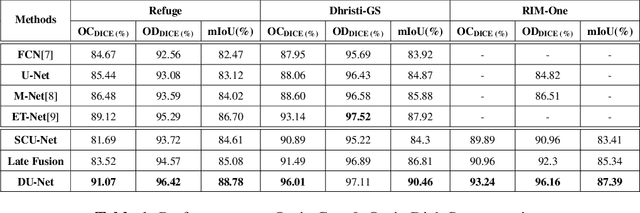
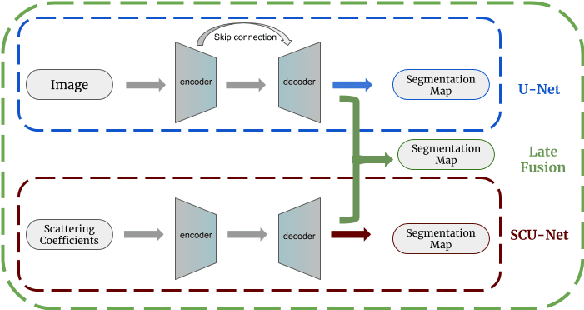
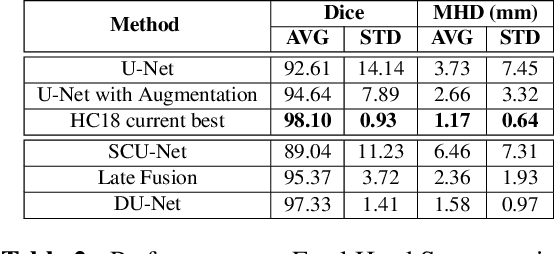
This work explores a hybrid approach to segmentation as an alternative to a purely data-driven approach. We introduce an end-to-end U-Net based network called DU-Net, which uses additional frequency preserving features, namely the Scattering Coefficients (SC), for medical image segmentation. SC are translation invariant and Lipschitz continuous to deformations which help DU-Net outperform other conventional CNN counterparts on four datasets and two segmentation tasks: Optic Disc and Optic Cup in color fundus images and fetal Head in ultrasound images. The proposed method shows remarkable improvement over the basic U-Net with performance competitive to state-of-the-art methods. The results indicate that it is possible to use a lighter network trained with fewer images (without any augmentation) to attain good segmentation results.