 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch2Motion: Training-Free Object-Level Motion Control via Attention-Consensus Search
Mar 17, 2026We present Search2Motion, a training-free framework for object-level motion editing in image-to-video generation. Unlike prior methods requiring trajectories, bounding boxes, masks, or motion fields, Search2Motion adopts target-frame-based control, leveraging first-last-frame motion priors to realize object relocation while preserving scene stability without fine-tuning. Reliable target-frame construction is achieved through semantic-guided object insertion and robust background inpainting. We further show that early-step self-attention maps predict object and camera dynamics, offering interpretable user feedback and motivating ACE-Seed (Attention Consensus for Early-step Seed selection), a lightweight search strategy that improves motion fidelity without look-ahead sampling or external evaluators. Noting that existing benchmarks conflate object and camera motion, we introduce S2M-DAVIS and S2M-OMB for stable-camera, object-only evaluation, alongside FLF2V-obj metrics that isolate object artifacts without requiring ground-truth trajectories. Search2Motion consistently outperforms baselines on FLF2V-obj and VBench.
Toward Scalable Video Narration: A Training-free Approach Using Multimodal Large Language Models
Jul 22, 2025In this paper, we introduce VideoNarrator, a novel training-free pipeline designed to generate dense video captions that offer a structured snapshot of video content. These captions offer detailed narrations with precise timestamps, capturing the nuances present in each segment of the video. Despite advancements in multimodal large language models (MLLMs) for video comprehension, these models often struggle with temporally aligned narrations and tend to hallucinate, particularly in unfamiliar scenarios. VideoNarrator addresses these challenges by leveraging a flexible pipeline where off-the-shelf MLLMs and visual-language models (VLMs) can function as caption generators, context providers, or caption verifiers. Our experimental results demonstrate that the synergistic interaction of these components significantly enhances the quality and accuracy of video narrations, effectively reducing hallucinations and improving temporal alignment. This structured approach not only enhances video understanding but also facilitates downstream tasks such as video summarization and video question answering, and can be potentially extended for advertising and marketing applications.
EASG-Bench: Video Q&A Benchmark with Egocentric Action Scene Graphs
Jun 06, 2025We introduce EASG-Bench, a question-answering benchmark for egocentric videos where the question-answering pairs are created from spatio-temporally grounded dynamic scene graphs capturing intricate relationships among actors, actions, and objects. We propose a systematic evaluation framework and evaluate several language-only and video large language models (video-LLMs) on this benchmark. We observe a performance gap in language-only and video-LLMs, especially on questions focusing on temporal ordering, thus identifying a research gap in the area of long-context video understanding. To promote the reproducibility of our findings and facilitate further research, the benchmark and accompanying code are available at the following GitHub page: https://github.com/fpv-iplab/EASG-bench.
Ego-VPA: Egocentric Video Understanding with Parameter-efficient Adaptation
Jul 28, 2024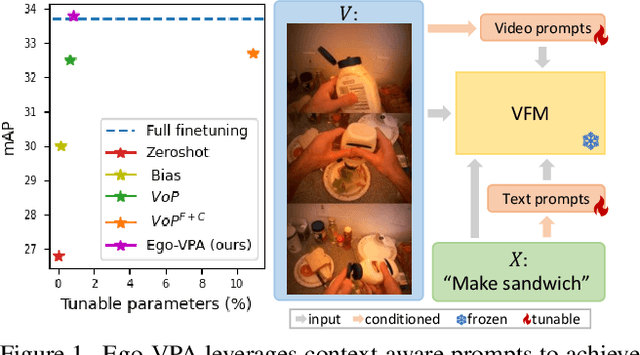
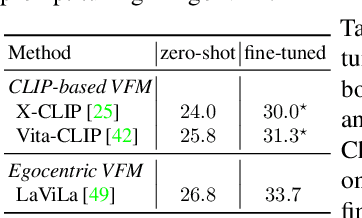
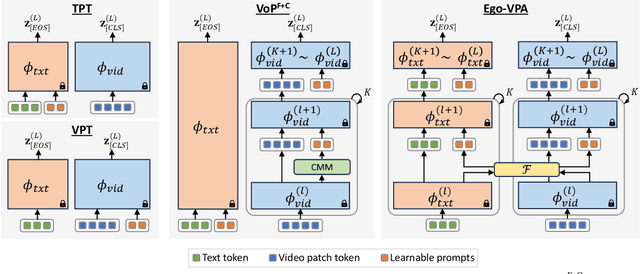
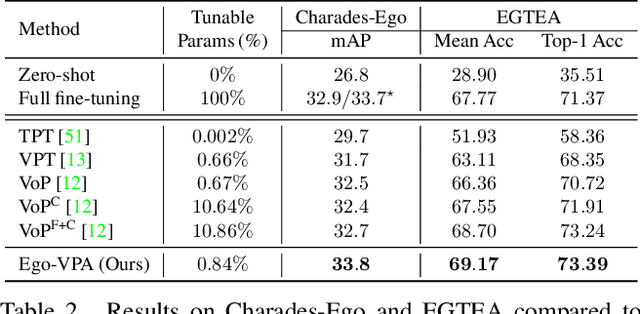
Video understanding typically requires fine-tuning the large backbone when adapting to new domains. In this paper, we leverage the egocentric video foundation models (Ego-VFMs) based on video-language pre-training and propose a parameter-efficient adaptation for egocentric video tasks, namely Ego-VPA. It employs a local sparse approximation for each video frame/text feature using the basis prompts, and the selected basis prompts are used to synthesize video/text prompts. Since the basis prompts are shared across frames and modalities, it models context fusion and cross-modal transfer in an efficient fashion. Experiments show that Ego-VPA excels in lightweight adaptation (with only 0.84% learnable parameters), largely improving over baselines and reaching the performance of full fine-tuning.
Single-Stage Visual Relationship Learning using Conditional Queries
Jun 09, 2023Research in scene graph generation (SGG) usually considers two-stage models, that is, detecting a set of entities, followed by combining them and labeling all possible relationships. While showing promising results, the pipeline structure induces large parameter and computation overhead, and typically hinders end-to-end optimizations. To address this, recent research attempts to train single-stage models that are computationally efficient. With the advent of DETR, a set based detection model, one-stage models attempt to predict a set of subject-predicate-object triplets directly in a single shot. However, SGG is inherently a multi-task learning problem that requires modeling entity and predicate distributions simultaneously. In this paper, we propose Transformers with conditional queries for SGG, namely, TraCQ with a new formulation for SGG that avoids the multi-task learning problem and the combinatorial entity pair distribution. We employ a DETR-based encoder-decoder design and leverage conditional queries to significantly reduce the entity label space as well, which leads to 20% fewer parameters compared to state-of-the-art single-stage models. Experimental results show that TraCQ not only outperforms existing single-stage scene graph generation methods, it also beats many state-of-the-art two-stage methods on the Visual Genome dataset, yet is capable of end-to-end training and faster inference.
ProTeCt: Prompt Tuning for Hierarchical Consistency
Jun 04, 2023Large visual-language models, like CLIP, learn generalized representations and have shown promising zero-shot performance. Few-shot adaptation methods, based on prompt tuning, have also been shown to further improve performance on downstream datasets. However, these models are not hierarchically consistent. Frequently, they infer incorrect labels at coarser taxonomic class levels, even when the inference at the leaf level (original class labels) is correct. This is problematic, given their support for open set classification and, in particular, open-grained classification, where practitioners define label sets at various levels of granularity. To address this problem, we propose a prompt tuning technique to calibrate the hierarchical consistency of model predictions. A set of metrics of hierarchical consistency, the Hierarchical Consistent Accuracy (HCA) and the Mean Treecut Accuracy (MTA), are first proposed to benchmark model performance in the open-granularity setting. A prompt tuning technique, denoted as Prompt Tuning for Hierarchical Consistency (ProTeCt), is then proposed to calibrate classification across all possible label set granularities. Results show that ProTeCt can be combined with existing prompt tuning methods to significantly improve open-granularity classification performance without degradation of the original classification performance at the leaf level.
Class-Incremental Learning with Strong Pre-trained Models
Apr 07, 2022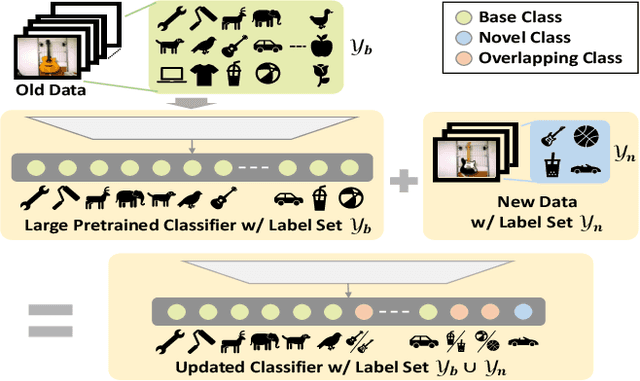
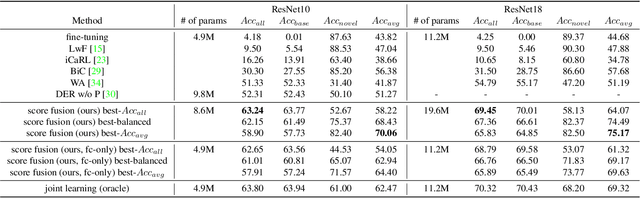
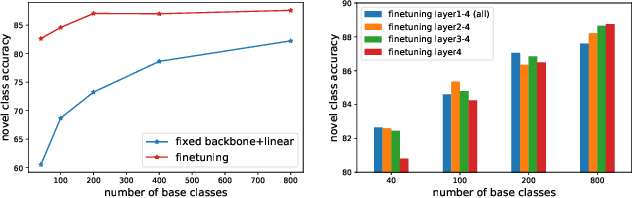
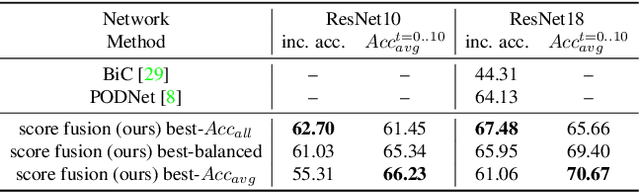
Class-incremental learning (CIL) has been widely studied under the setting of starting from a small number of classes (base classes). Instead, we explore an understudied real-world setting of CIL that starts with a strong model pre-trained on a large number of base classes. We hypothesize that a strong base model can provide a good representation for novel classes and incremental learning can be done with small adaptations. We propose a 2-stage training scheme, i) feature augmentation -- cloning part of the backbone and fine-tuning it on the novel data, and ii) fusion -- combining the base and novel classifiers into a unified classifier. Experiments show that the proposed method significantly outperforms state-of-the-art CIL methods on the large-scale ImageNet dataset (e.g. +10% overall accuracy than the best). We also propose and analyze understudied practical CIL scenarios, such as base-novel overlap with distribution shift. Our proposed method is robust and generalizes to all analyzed CIL settings.
Learning of Visual Relations: The Devil is in the Tails
Aug 22, 2021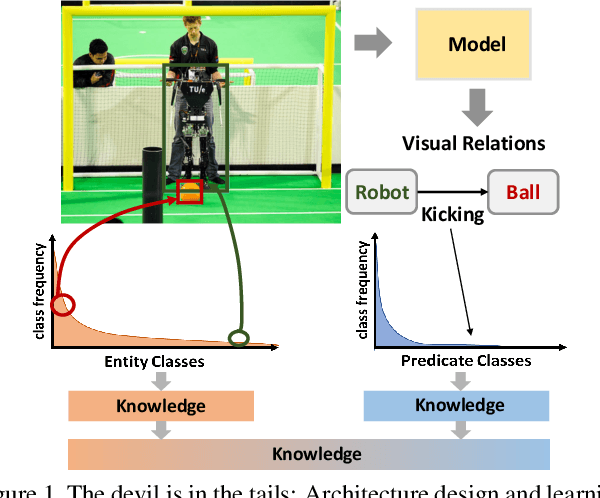
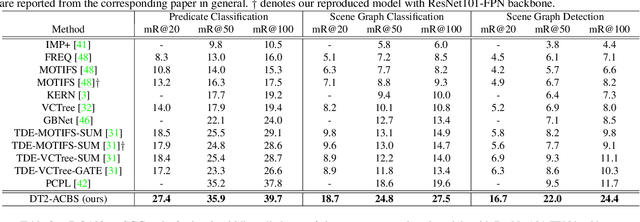
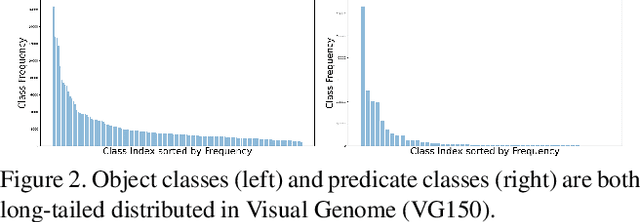

Significant effort has been recently devoted to modeling visual relations. This has mostly addressed the design of architectures, typically by adding parameters and increasing model complexity. However, visual relation learning is a long-tailed problem, due to the combinatorial nature of joint reasoning about groups of objects. Increasing model complexity is, in general, ill-suited for long-tailed problems due to their tendency to overfit. In this paper, we explore an alternative hypothesis, denoted the Devil is in the Tails. Under this hypothesis, better performance is achieved by keeping the model simple but improving its ability to cope with long-tailed distributions. To test this hypothesis, we devise a new approach for training visual relationships models, which is inspired by state-of-the-art long-tailed recognition literature. This is based on an iterative decoupled training scheme, denoted Decoupled Training for Devil in the Tails (DT2). DT2 employs a novel sampling approach, Alternating Class-Balanced Sampling (ACBS), to capture the interplay between the long-tailed entity and predicate distributions of visual relations. Results show that, with an extremely simple architecture, DT2-ACBS significantly outperforms much more complex state-of-the-art methods on scene graph generation tasks. This suggests that the development of sophisticated models must be considered in tandem with the long-tailed nature of the problem.
Solving Long-tailed Recognition with Deep Realistic Taxonomic Classifier
Jul 20, 2020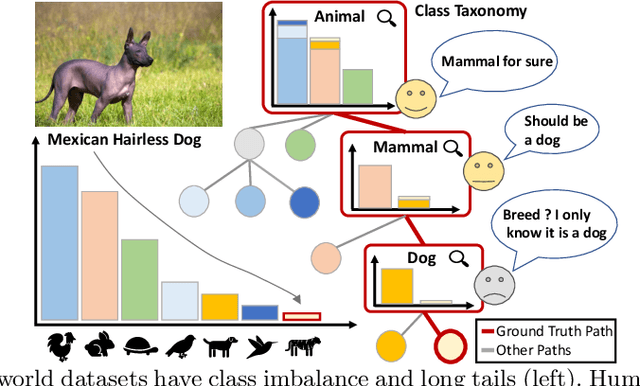
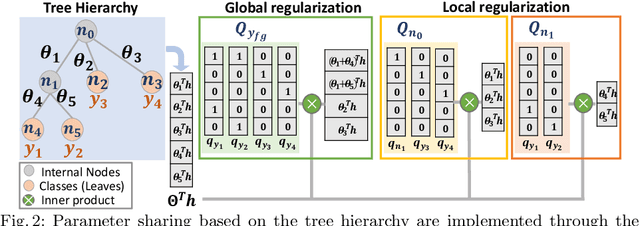
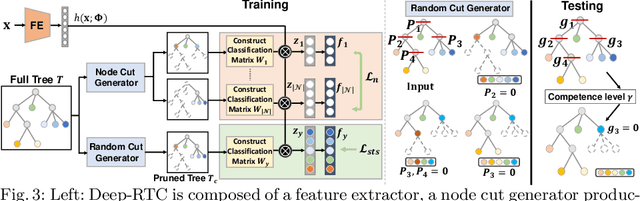
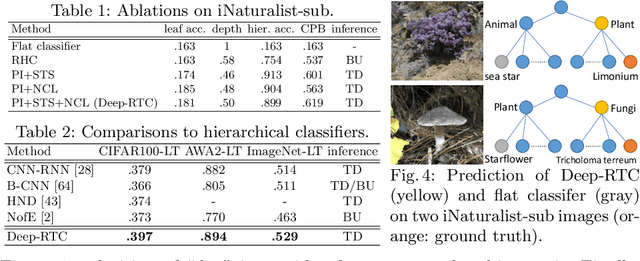
Long-tail recognition tackles the natural non-uniformly distributed data in real-world scenarios. While modern classifiers perform well on populated classes, its performance degrades significantly on tail classes. Humans, however, are less affected by this since, when confronted with uncertain examples, they simply opt to provide coarser predictions. Motivated by this, a deep realistic taxonomic classifier (Deep-RTC) is proposed as a new solution to the long-tail problem, combining realism with hierarchical predictions. The model has the option to reject classifying samples at different levels of the taxonomy, once it cannot guarantee the desired performance. Deep-RTC is implemented with a stochastic tree sampling during training to simulate all possible classification conditions at finer or coarser levels and a rejection mechanism at inference time. Experiments on the long-tailed version of four datasets, CIFAR100, AWA2, Imagenet, and iNaturalist, demonstrate that the proposed approach preserves more information on all classes with different popularity levels. Deep-RTC also outperforms the state-of-the-art methods in longtailed recognition, hierarchical classification, and learning with rejection literature using the proposed correctly predicted bits (CPB) metric.
Exploit Clues from Views: Self-Supervised and Regularized Learning for Multiview Object Recognition
Mar 28, 2020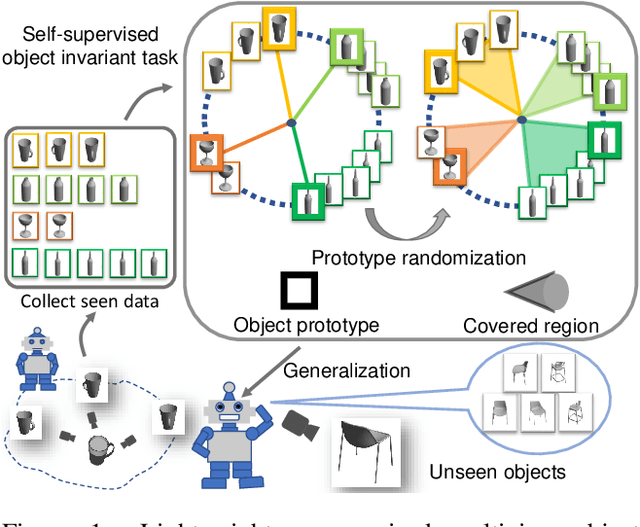
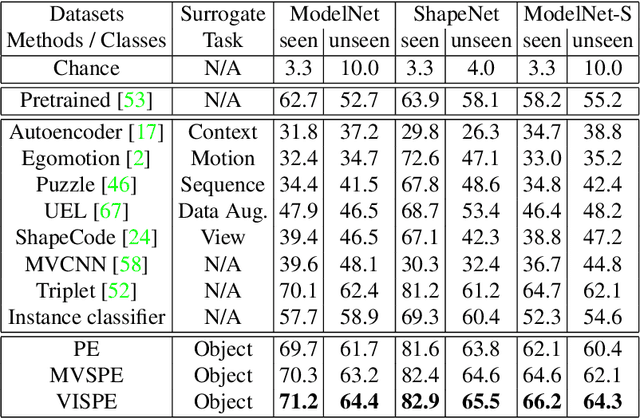
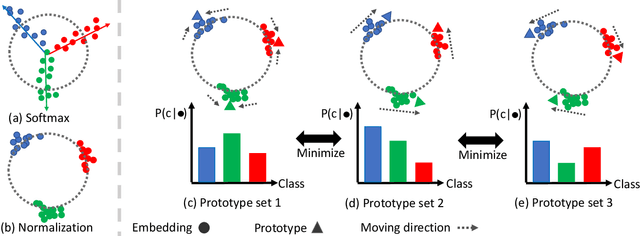
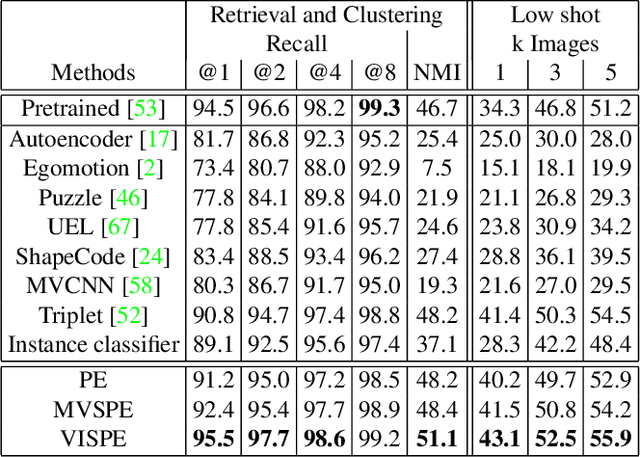
Multiview recognition has been well studied in the literature and achieves decent performance in object recognition and retrieval task. However, most previous works rely on supervised learning and some impractical underlying assumptions, such as the availability of all views in training and inference time. In this work, the problem of multiview self-supervised learning (MV-SSL) is investigated, where only image to object association is given. Given this setup, a novel surrogate task for self-supervised learning is proposed by pursuing "object invariant" representation. This is solved by randomly selecting an image feature of an object as object prototype, accompanied with multiview consistency regularization, which results in view invariant stochastic prototype embedding (VISPE). Experiments shows that the recognition and retrieval results using VISPE outperform that of other self-supervised learning methods on seen and unseen data. VISPE can also be applied to semi-supervised scenario and demonstrates robust performance with limited data available. Code is available at https://github.com/chihhuiho/VISPE