 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkipKV: Selective Skipping of KV Generation and Storage for Efficient Inference with Large Reasoning Models
Dec 08, 2025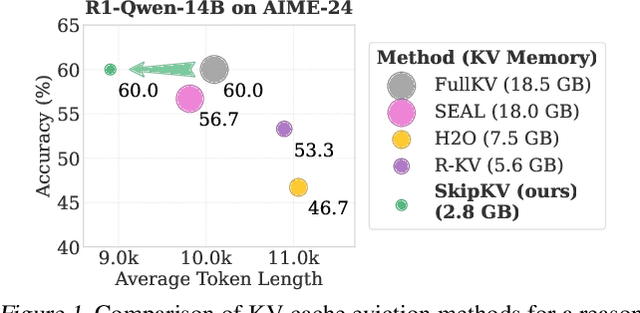
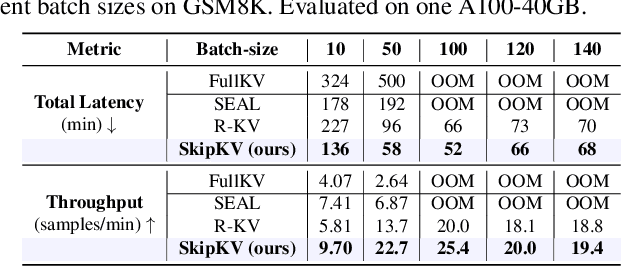
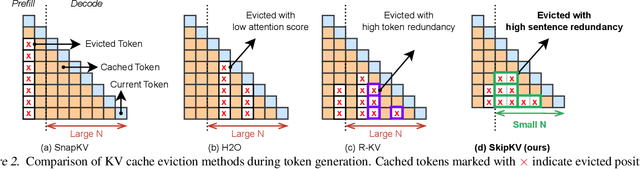
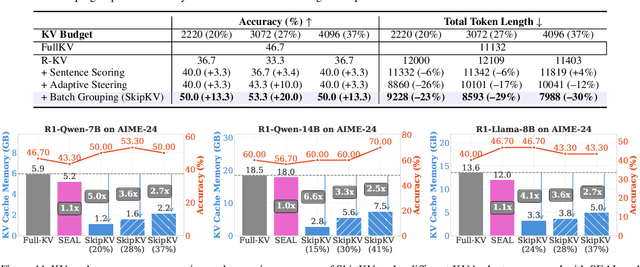
Large reasoning models (LRMs) often cost significant key-value (KV) cache overhead, due to their linear growth with the verbose chain-of-thought (CoT) reasoning process. This costs both memory and throughput bottleneck limiting their efficient deployment. Towards reducing KV cache size during inference, we first investigate the effectiveness of existing KV cache eviction methods for CoT reasoning. Interestingly, we find that due to unstable token-wise scoring and the reduced effective KV budget caused by padding tokens, state-of-the-art (SoTA) eviction methods fail to maintain accuracy in the multi-batch setting. Additionally, these methods often generate longer sequences than the original model, as semantic-unaware token-wise eviction leads to repeated revalidation during reasoning. To address these issues, we present \textbf{SkipKV}, a \textbf{\textit{training-free}} KV compression method for selective \textit{eviction} and \textit{generation} operating at a coarse-grained sentence-level sequence removal for efficient CoT reasoning. In specific, it introduces a \textit{sentence-scoring metric} to identify and remove highly similar sentences while maintaining semantic coherence. To suppress redundant generation, SkipKV dynamically adjusts a steering vector to update the hidden activation states during inference enforcing the LRM to generate concise response. Extensive evaluations on multiple reasoning benchmarks demonstrate the effectiveness of SkipKV in maintaining up to $\mathbf{26.7}\%$ improved accuracy compared to the alternatives, at a similar compression budget. Additionally, compared to SoTA, SkipKV yields up to $\mathbf{1.6}\times$ fewer generation length while improving throughput up to $\mathbf{1.7}\times$.
Toward Scalable Video Narration: A Training-free Approach Using Multimodal Large Language Models
Jul 22, 2025In this paper, we introduce VideoNarrator, a novel training-free pipeline designed to generate dense video captions that offer a structured snapshot of video content. These captions offer detailed narrations with precise timestamps, capturing the nuances present in each segment of the video. Despite advancements in multimodal large language models (MLLMs) for video comprehension, these models often struggle with temporally aligned narrations and tend to hallucinate, particularly in unfamiliar scenarios. VideoNarrator addresses these challenges by leveraging a flexible pipeline where off-the-shelf MLLMs and visual-language models (VLMs) can function as caption generators, context providers, or caption verifiers. Our experimental results demonstrate that the synergistic interaction of these components significantly enhances the quality and accuracy of video narrations, effectively reducing hallucinations and improving temporal alignment. This structured approach not only enhances video understanding but also facilitates downstream tasks such as video summarization and video question answering, and can be potentially extended for advertising and marketing applications.
EASG-Bench: Video Q&A Benchmark with Egocentric Action Scene Graphs
Jun 06, 2025We introduce EASG-Bench, a question-answering benchmark for egocentric videos where the question-answering pairs are created from spatio-temporally grounded dynamic scene graphs capturing intricate relationships among actors, actions, and objects. We propose a systematic evaluation framework and evaluate several language-only and video large language models (video-LLMs) on this benchmark. We observe a performance gap in language-only and video-LLMs, especially on questions focusing on temporal ordering, thus identifying a research gap in the area of long-context video understanding. To promote the reproducibility of our findings and facilitate further research, the benchmark and accompanying code are available at the following GitHub page: https://github.com/fpv-iplab/EASG-bench.
LVLM-Compress-Bench: Benchmarking the Broader Impact of Large Vision-Language Model Compression
Mar 06, 2025Despite recent efforts in understanding the compression impact on large language models (LLMs) in terms of their downstream task performance and trustworthiness on relatively simpler uni-modal benchmarks (for example, question answering, common sense reasoning), their detailed study on multi-modal Large Vision-Language Models (LVLMs) is yet to be unveiled. Towards mitigating this gap, we present LVLM-Compress-Bench, a framework to first thoroughly study the broad impact of compression on the generative performance of LVLMs with multi-modal input driven tasks. In specific, we consider two major classes of compression for autoregressive models, namely KV cache and weight compression, for the dynamically growing intermediate cache and static weights, respectively. We use four LVLM variants of the popular LLaVA framework to present our analysis via integrating various state-of-the-art KV and weight compression methods including uniform, outlier-reduced, and group quantization for the KV cache and weights. With this framework we demonstrate on ten different multi-modal datasets with different capabilities including recognition, knowledge, language generation, spatial awareness, visual reasoning, hallucination and visual illusion identification, toxicity, stereotypes and bias. In specific, our framework demonstrates the compression impact on both general and ethically critical metrics leveraging a combination of real world and synthetic datasets to encompass diverse societal intersectional attributes. Extensive experimental evaluations yield diverse and intriguing observations on the behavior of LVLMs at different quantization budget of KV and weights, in both maintaining and losing performance as compared to the baseline model with FP16 data format. Code will be open-sourced at https://github.com/opengear-project/LVLM-compress-bench.
LLaMA-NAS: Efficient Neural Architecture Search for Large Language Models
May 28, 2024The abilities of modern large language models (LLMs) in solving natural language processing, complex reasoning, sentiment analysis and other tasks have been extraordinary which has prompted their extensive adoption. Unfortunately, these abilities come with very high memory and computational costs which precludes the use of LLMs on most hardware platforms. To mitigate this, we propose an effective method of finding Pareto-optimal network architectures based on LLaMA2-7B using one-shot NAS. In particular, we fine-tune LLaMA2-7B only once and then apply genetic algorithm-based search to find smaller, less computationally complex network architectures. We show that, for certain standard benchmark tasks, the pre-trained LLaMA2-7B network is unnecessarily large and complex. More specifically, we demonstrate a 1.5x reduction in model size and 1.3x speedup in throughput for certain tasks with negligible drop in accuracy. In addition to finding smaller, higher-performing network architectures, our method does so more effectively and efficiently than certain pruning or sparsification techniques. Finally, we demonstrate how quantization is complementary to our method and that the size and complexity of the networks we find can be further decreased using quantization. We believe that our work provides a way to automatically create LLMs which can be used on less expensive and more readily available hardware platforms.
SimQ-NAS: Simultaneous Quantization Policy and Neural Architecture Search
Dec 19, 2023Recent one-shot Neural Architecture Search algorithms rely on training a hardware-agnostic super-network tailored to a specific task and then extracting efficient sub-networks for different hardware platforms. Popular approaches separate the training of super-networks from the search for sub-networks, often employing predictors to alleviate the computational overhead associated with search. Additionally, certain methods also incorporate the quantization policy within the search space. However, while the quantization policy search for convolutional neural networks is well studied, the extension of these methods to transformers and especially foundation models remains under-explored. In this paper, we demonstrate that by using multi-objective search algorithms paired with lightly trained predictors, we can efficiently search for both the sub-network architecture and the corresponding quantization policy and outperform their respective baselines across different performance objectives such as accuracy, model size, and latency. Specifically, we demonstrate that our approach performs well across both uni-modal (ViT and BERT) and multi-modal (BEiT-3) transformer-based architectures as well as convolutional architectures (ResNet). For certain networks, we demonstrate an improvement of up to $4.80x$ and $3.44x$ for latency and model size respectively, without degradation in accuracy compared to the fully quantized INT8 baselines.
InstaTune: Instantaneous Neural Architecture Search During Fine-Tuning
Aug 29, 2023



One-Shot Neural Architecture Search (NAS) algorithms often rely on training a hardware agnostic super-network for a domain specific task. Optimal sub-networks are then extracted from the trained super-network for different hardware platforms. However, training super-networks from scratch can be extremely time consuming and compute intensive especially for large models that rely on a two-stage training process of pre-training and fine-tuning. State of the art pre-trained models are available for a wide range of tasks, but their large sizes significantly limits their applicability on various hardware platforms. We propose InstaTune, a method that leverages off-the-shelf pre-trained weights for large models and generates a super-network during the fine-tuning stage. InstaTune has multiple benefits. Firstly, since the process happens during fine-tuning, it minimizes the overall time and compute resources required for NAS. Secondly, the sub-networks extracted are optimized for the target task, unlike prior work that optimizes on the pre-training objective. Finally, InstaTune is easy to "plug and play" in existing frameworks. By using multi-objective evolutionary search algorithms along with lightly trained predictors, we find Pareto-optimal sub-networks that outperform their respective baselines across different performance objectives such as accuracy and MACs. Specifically, we demonstrate that our approach performs well across both unimodal (ViT and BERT) and multi-modal (BEiT-3) transformer based architectures.
A Hardware-Aware Framework for Accelerating Neural Architecture Search Across Modalities
May 19, 2022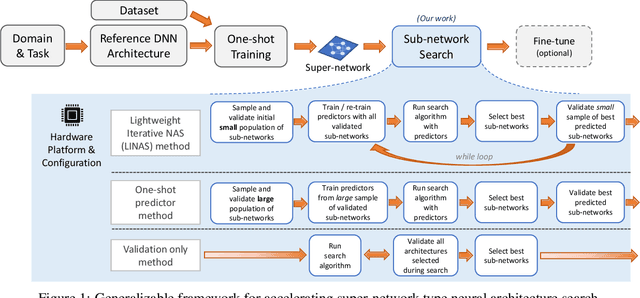
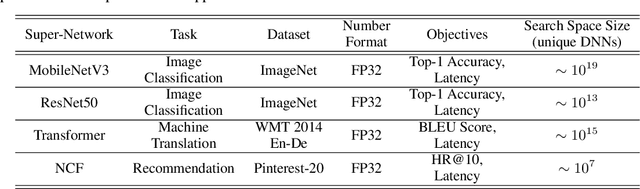
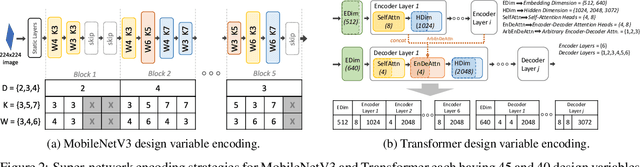
Recent advances in Neural Architecture Search (NAS) such as one-shot NAS offer the ability to extract specialized hardware-aware sub-network configurations from a task-specific super-network. While considerable effort has been employed towards improving the first stage, namely, the training of the super-network, the search for derivative high-performing sub-networks is still under-explored. Popular methods decouple the super-network training from the sub-network search and use performance predictors to reduce the computational burden of searching on different hardware platforms. We propose a flexible search framework that automatically and efficiently finds optimal sub-networks that are optimized for different performance metrics and hardware configurations. Specifically, we show how evolutionary algorithms can be paired with lightly trained objective predictors in an iterative cycle to accelerate architecture search in a multi-objective setting for various modalities including machine translation and image classification.
A Hardware-Aware System for Accelerating Deep Neural Network Optimization
Feb 25, 2022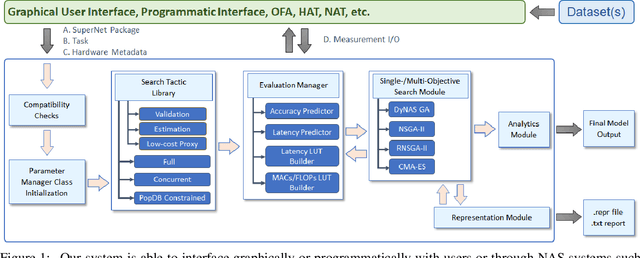
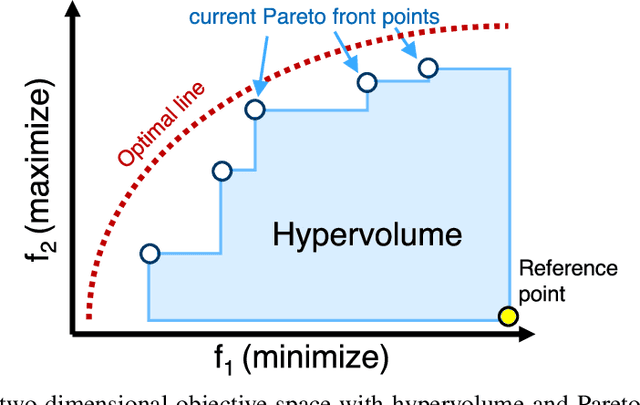
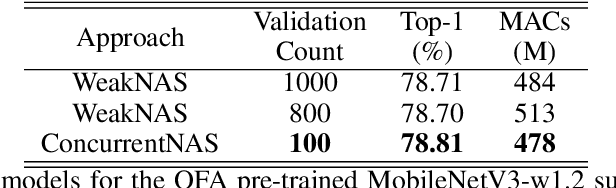
Recent advances in Neural Architecture Search (NAS) which extract specialized hardware-aware configurations (a.k.a. "sub-networks") from a hardware-agnostic "super-network" have become increasingly popular. While considerable effort has been employed towards improving the first stage, namely, the training of the super-network, the search for derivative high-performing sub-networks is still largely under-explored. For example, some recent network morphism techniques allow a super-network to be trained once and then have hardware-specific networks extracted from it as needed. These methods decouple the super-network training from the sub-network search and thus decrease the computational burden of specializing to different hardware platforms. We propose a comprehensive system that automatically and efficiently finds sub-networks from a pre-trained super-network that are optimized to different performance metrics and hardware configurations. By combining novel search tactics and algorithms with intelligent use of predictors, we significantly decrease the time needed to find optimal sub-networks from a given super-network. Further, our approach does not require the super-network to be refined for the target task a priori, thus allowing it to interface with any super-network. We demonstrate through extensive experiments that our system works seamlessly with existing state-of-the-art super-network training methods in multiple domains. Moreover, we show how novel search tactics paired with evolutionary algorithms can accelerate the search process for ResNet50, MobileNetV3 and Transformer while maintaining objective space Pareto front diversity and demonstrate an 8x faster search result than the state-of-the-art Bayesian optimization WeakNAS approach.
Accelerating Neural Architecture Exploration Across Modalities Using Genetic Algorithms
Feb 25, 2022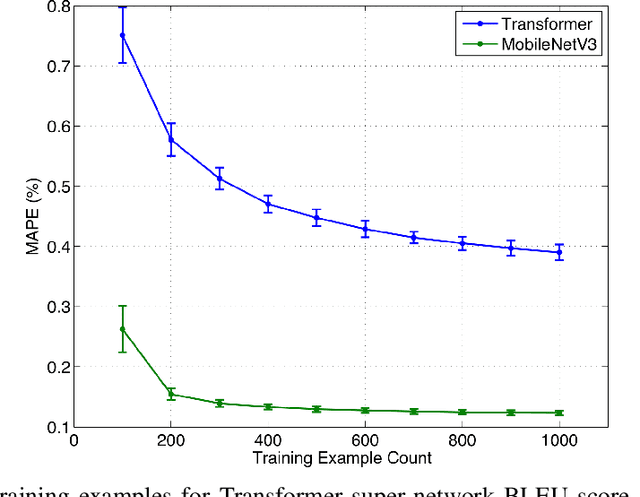
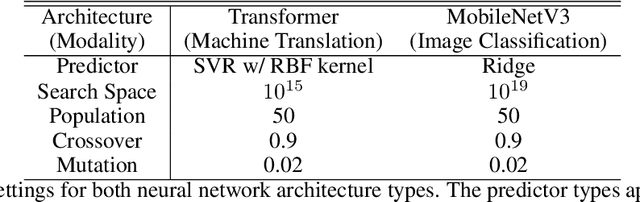
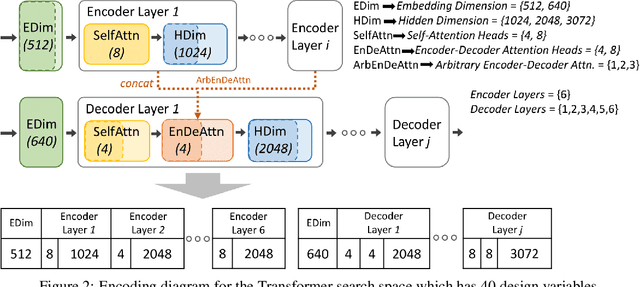
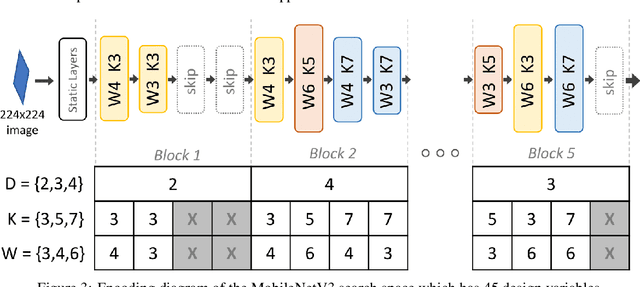
Neural architecture search (NAS), the study of automating the discovery of optimal deep neural network architectures for tasks in domains such as computer vision and natural language processing, has seen rapid growth in the machine learning research community. While there have been many recent advancements in NAS, there is still a significant focus on reducing the computational cost incurred when validating discovered architectures by making search more efficient. Evolutionary algorithms, specifically genetic algorithms, have a history of usage in NAS and continue to gain popularity versus other optimization approaches as a highly efficient way to explore the architecture objective space. Most NAS research efforts have centered around computer vision tasks and only recently have other modalities, such as the rapidly growing field of natural language processing, been investigated in depth. In this work, we show how genetic algorithms can be paired with lightly trained objective predictors in an iterative cycle to accelerate multi-objective architectural exploration in a way that works in the modalities of both machine translation and image classification.