 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaMA-NAS: Efficient Neural Architecture Search for Large Language Models
May 28, 2024The abilities of modern large language models (LLMs) in solving natural language processing, complex reasoning, sentiment analysis and other tasks have been extraordinary which has prompted their extensive adoption. Unfortunately, these abilities come with very high memory and computational costs which precludes the use of LLMs on most hardware platforms. To mitigate this, we propose an effective method of finding Pareto-optimal network architectures based on LLaMA2-7B using one-shot NAS. In particular, we fine-tune LLaMA2-7B only once and then apply genetic algorithm-based search to find smaller, less computationally complex network architectures. We show that, for certain standard benchmark tasks, the pre-trained LLaMA2-7B network is unnecessarily large and complex. More specifically, we demonstrate a 1.5x reduction in model size and 1.3x speedup in throughput for certain tasks with negligible drop in accuracy. In addition to finding smaller, higher-performing network architectures, our method does so more effectively and efficiently than certain pruning or sparsification techniques. Finally, we demonstrate how quantization is complementary to our method and that the size and complexity of the networks we find can be further decreased using quantization. We believe that our work provides a way to automatically create LLMs which can be used on less expensive and more readily available hardware platforms.
SimQ-NAS: Simultaneous Quantization Policy and Neural Architecture Search
Dec 19, 2023Recent one-shot Neural Architecture Search algorithms rely on training a hardware-agnostic super-network tailored to a specific task and then extracting efficient sub-networks for different hardware platforms. Popular approaches separate the training of super-networks from the search for sub-networks, often employing predictors to alleviate the computational overhead associated with search. Additionally, certain methods also incorporate the quantization policy within the search space. However, while the quantization policy search for convolutional neural networks is well studied, the extension of these methods to transformers and especially foundation models remains under-explored. In this paper, we demonstrate that by using multi-objective search algorithms paired with lightly trained predictors, we can efficiently search for both the sub-network architecture and the corresponding quantization policy and outperform their respective baselines across different performance objectives such as accuracy, model size, and latency. Specifically, we demonstrate that our approach performs well across both uni-modal (ViT and BERT) and multi-modal (BEiT-3) transformer-based architectures as well as convolutional architectures (ResNet). For certain networks, we demonstrate an improvement of up to $4.80x$ and $3.44x$ for latency and model size respectively, without degradation in accuracy compared to the fully quantized INT8 baselines.
InstaTune: Instantaneous Neural Architecture Search During Fine-Tuning
Aug 29, 2023



One-Shot Neural Architecture Search (NAS) algorithms often rely on training a hardware agnostic super-network for a domain specific task. Optimal sub-networks are then extracted from the trained super-network for different hardware platforms. However, training super-networks from scratch can be extremely time consuming and compute intensive especially for large models that rely on a two-stage training process of pre-training and fine-tuning. State of the art pre-trained models are available for a wide range of tasks, but their large sizes significantly limits their applicability on various hardware platforms. We propose InstaTune, a method that leverages off-the-shelf pre-trained weights for large models and generates a super-network during the fine-tuning stage. InstaTune has multiple benefits. Firstly, since the process happens during fine-tuning, it minimizes the overall time and compute resources required for NAS. Secondly, the sub-networks extracted are optimized for the target task, unlike prior work that optimizes on the pre-training objective. Finally, InstaTune is easy to "plug and play" in existing frameworks. By using multi-objective evolutionary search algorithms along with lightly trained predictors, we find Pareto-optimal sub-networks that outperform their respective baselines across different performance objectives such as accuracy and MACs. Specifically, we demonstrate that our approach performs well across both unimodal (ViT and BERT) and multi-modal (BEiT-3) transformer based architectures.
Sensi-BERT: Towards Sensitivity Driven Fine-Tuning for Parameter-Efficient BERT
Jul 14, 2023Large pre-trained language models have recently gained significant traction due to their improved performance on various down-stream tasks like text classification and question answering, requiring only few epochs of fine-tuning. However, their large model sizes often prohibit their applications on resource-constrained edge devices. Existing solutions of yielding parameter-efficient BERT models largely rely on compute-exhaustive training and fine-tuning. Moreover, they often rely on additional compute heavy models to mitigate the performance gap. In this paper, we present Sensi-BERT, a sensitivity driven efficient fine-tuning of BERT models that can take an off-the-shelf pre-trained BERT model and yield highly parameter-efficient models for downstream tasks. In particular, we perform sensitivity analysis to rank each individual parameter tensor, that then is used to trim them accordingly during fine-tuning for a given parameter or FLOPs budget. Our experiments show the efficacy of Sensi-BERT across different downstream tasks including MNLI, QQP, QNLI, and SST-2, demonstrating better performance at similar or smaller parameter budget compared to various existing alternatives.
A Hardware-Aware Framework for Accelerating Neural Architecture Search Across Modalities
May 19, 2022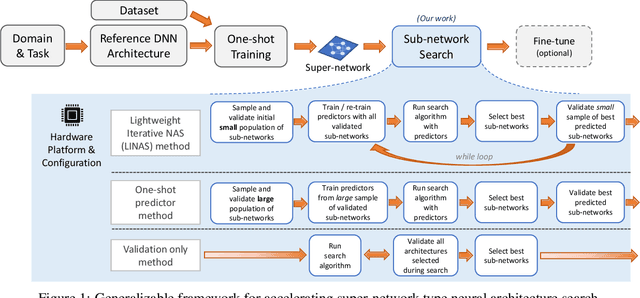
Recent advances in Neural Architecture Search (NAS) such as one-shot NAS offer the ability to extract specialized hardware-aware sub-network configurations from a task-specific super-network. While considerable effort has been employed towards improving the first stage, namely, the training of the super-network, the search for derivative high-performing sub-networks is still under-explored. Popular methods decouple the super-network training from the sub-network search and use performance predictors to reduce the computational burden of searching on different hardware platforms. We propose a flexible search framework that automatically and efficiently finds optimal sub-networks that are optimized for different performance metrics and hardware configurations. Specifically, we show how evolutionary algorithms can be paired with lightly trained objective predictors in an iterative cycle to accelerate architecture search in a multi-objective setting for various modalities including machine translation and image classification.
A Fast and Efficient Conditional Learning for Tunable Trade-Off between Accuracy and Robustness
Mar 28, 2022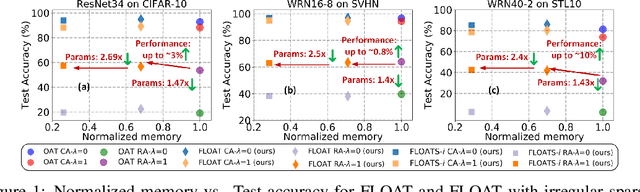

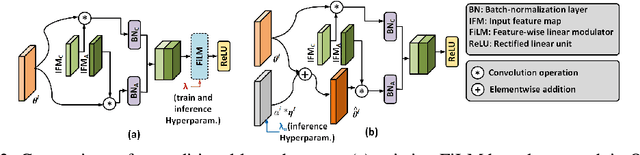
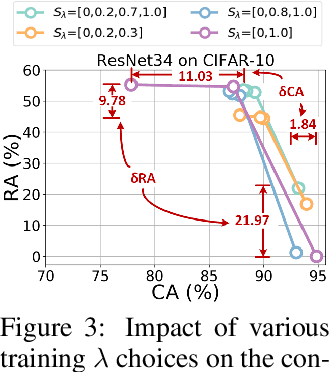
Existing models that achieve state-of-the-art (SOTA) performance on both clean and adversarially-perturbed images rely on convolution operations conditioned with feature-wise linear modulation (FiLM) layers. These layers require many new parameters and are hyperparameter sensitive. They significantly increase training time, memory cost, and potential latency which can prove costly for resource-limited or real-time applications. In this paper, we present a fast learnable once-for-all adversarial training (FLOAT) algorithm, which instead of the existing FiLM-based conditioning, presents a unique weight conditioned learning that requires no additional layer, thereby incurring no significant increase in parameter count, training time, or network latency compared to standard adversarial training. In particular, we add configurable scaled noise to the weight tensors that enables a trade-off between clean and adversarial performance. Extensive experiments show that FLOAT can yield SOTA performance improving both clean and perturbed image classification by up to ~6% and ~10%, respectively. Moreover, real hardware measurement shows that FLOAT can reduce the training time by up to 1.43x with fewer model parameters of up to 1.47x on iso-hyperparameter settings compared to the FiLM-based alternatives. Additionally, to further improve memory efficiency we introduce FLOAT sparse (FLOATS), a form of non-iterative model pruning and provide detailed empirical analysis to provide a three way accuracy-robustness-complexity trade-off for these new class of pruned conditionally trained models.
A Hardware-Aware System for Accelerating Deep Neural Network Optimization
Feb 25, 2022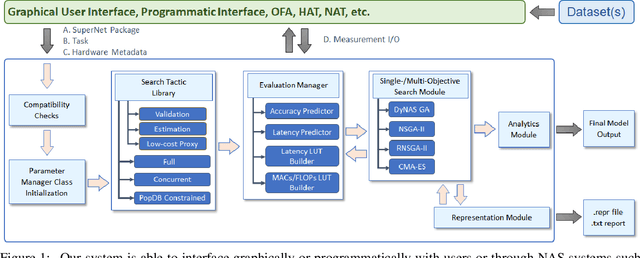
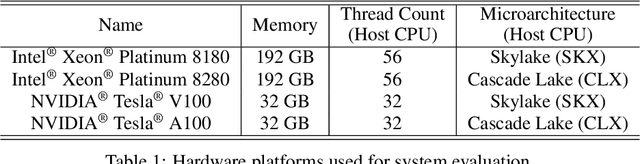
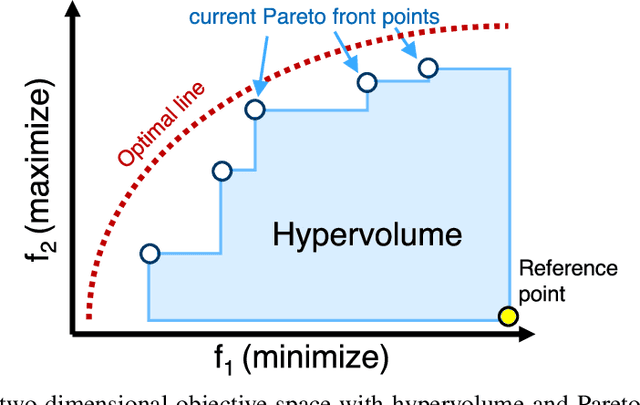
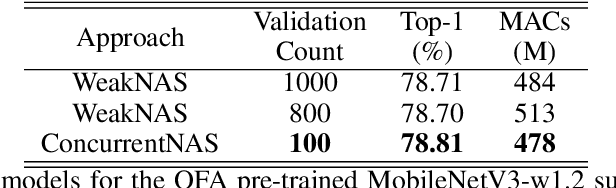
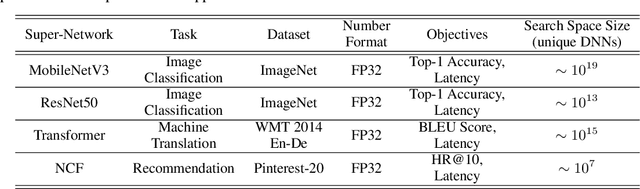
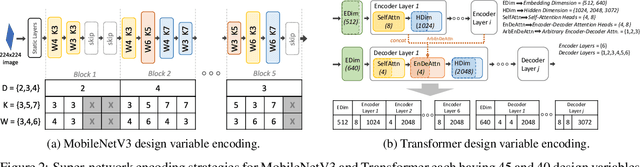
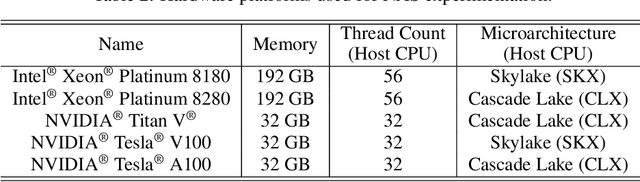
Recent advances in Neural Architecture Search (NAS) which extract specialized hardware-aware configurations (a.k.a. "sub-networks") from a hardware-agnostic "super-network" have become increasingly popular. While considerable effort has been employed towards improving the first stage, namely, the training of the super-network, the search for derivative high-performing sub-networks is still largely under-explored. For example, some recent network morphism techniques allow a super-network to be trained once and then have hardware-specific networks extracted from it as needed. These methods decouple the super-network training from the sub-network search and thus decrease the computational burden of specializing to different hardware platforms. We propose a comprehensive system that automatically and efficiently finds sub-networks from a pre-trained super-network that are optimized to different performance metrics and hardware configurations. By combining novel search tactics and algorithms with intelligent use of predictors, we significantly decrease the time needed to find optimal sub-networks from a given super-network. Further, our approach does not require the super-network to be refined for the target task a priori, thus allowing it to interface with any super-network. We demonstrate through extensive experiments that our system works seamlessly with existing state-of-the-art super-network training methods in multiple domains. Moreover, we show how novel search tactics paired with evolutionary algorithms can accelerate the search process for ResNet50, MobileNetV3 and Transformer while maintaining objective space Pareto front diversity and demonstrate an 8x faster search result than the state-of-the-art Bayesian optimization WeakNAS approach.
TrimBERT: Tailoring BERT for Trade-offs
Feb 24, 2022
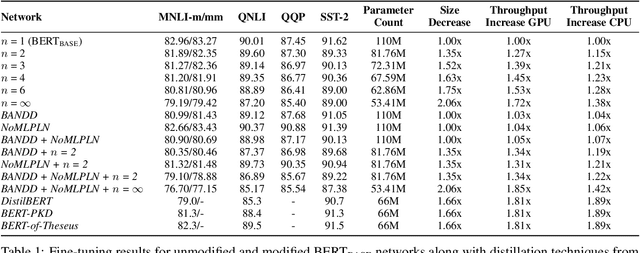


Models based on BERT have been extremely successful in solving a variety of natural language processing (NLP) tasks. Unfortunately, many of these large models require a great deal of computational resources and/or time for pre-training and fine-tuning which limits wider adoptability. While self-attention layers have been well-studied, a strong justification for inclusion of the intermediate layers which follow them remains missing in the literature. In this work, we show that reducing the number of intermediate layers in BERT-Base results in minimal fine-tuning accuracy loss of downstream tasks while significantly decreasing model size and training time. We further mitigate two key bottlenecks, by replacing all softmax operations in the self-attention layers with a computationally simpler alternative and removing half of all layernorm operations. This further decreases the training time while maintaining a high level of fine-tuning accuracy.
AttentionLite: Towards Efficient Self-Attention Models for Vision
Dec 21, 2020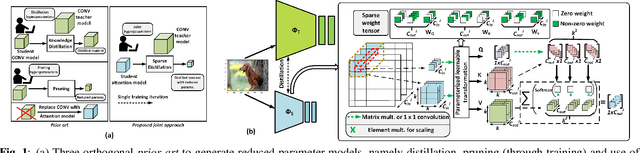
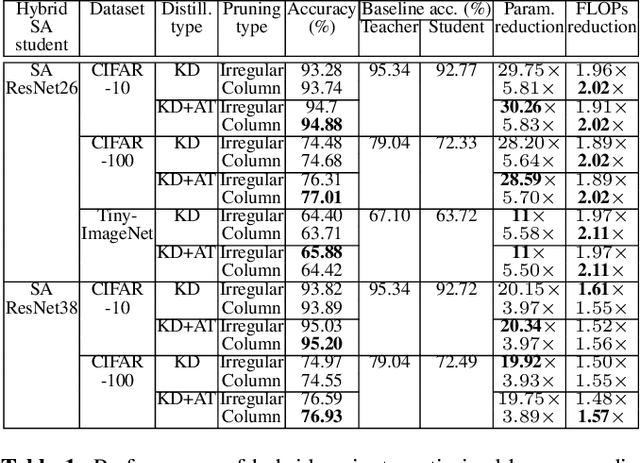
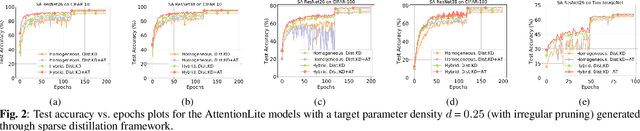
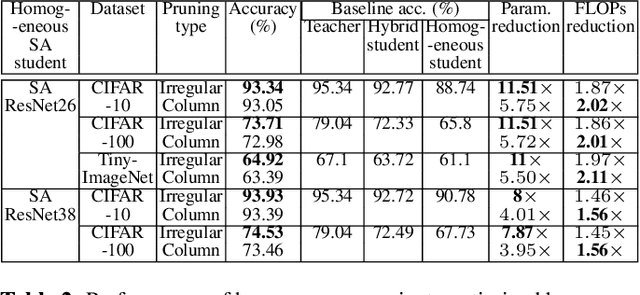
We propose a novel framework for producing a class of parameter and compute efficient models called AttentionLitesuitable for resource-constrained applications. Prior work has primarily focused on optimizing models either via knowledge distillation or pruning. In addition to fusing these two mechanisms, our joint optimization framework also leverages recent advances in self-attention as a substitute for convolutions. We can simultaneously distill knowledge from a compute-heavy teacher while also pruning the student model in a single pass of training thereby reducing training and fine-tuning times considerably. We evaluate the merits of our proposed approach on the CIFAR-10, CIFAR-100, and Tiny-ImageNet datasets. Not only do our AttentionLite models significantly outperform their unoptimized counterparts in accuracy, we find that in some cases, that they perform almost as well as their compute-heavy teachers while consuming only a fraction of the parameters and FLOPs. Concretely, AttentionLite models can achieve upto30x parameter efficiency and 2x computation efficiency with no significant accuracy drop compared to their teacher.
Attention-based Image Upsampling
Dec 17, 2020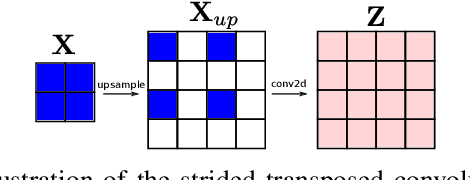
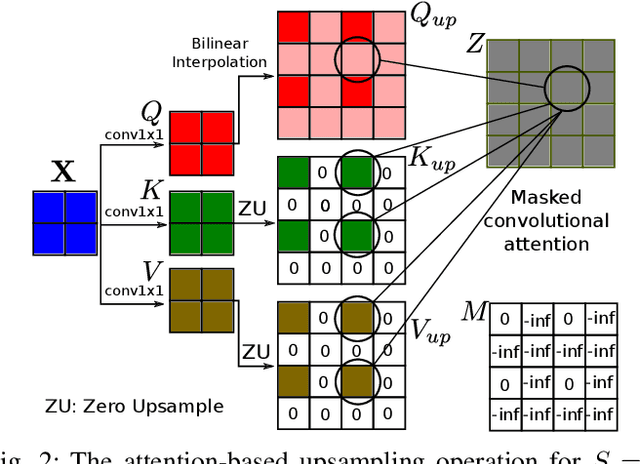
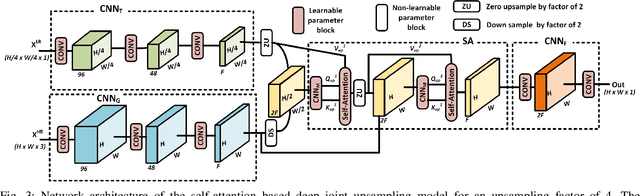

Convolutional layers are an integral part of many deep neural network solutions in computer vision. Recent work shows that replacing the standard convolution operation with mechanisms based on self-attention leads to improved performance on image classification and object detection tasks. In this work, we show how attention mechanisms can be used to replace another canonical operation: strided transposed convolution. We term our novel attention-based operation attention-based upsampling since it increases/upsamples the spatial dimensions of the feature maps. Through experiments on single image super-resolution and joint-image upsampling tasks, we show that attention-based upsampling consistently outperforms traditional upsampling methods based on strided transposed convolution or based on adaptive filters while using fewer parameters. We show that the inherent flexibility of the attention mechanism, which allows it to use separate sources for calculating the attention coefficients and the attention targets, makes attention-based upsampling a natural choice when fusing information from multiple image modalities.