 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOFT: Counterfactual-Conformal Decoding for Fair Chain-of-Thought Reasoning in Large Language Models
May 28, 2026Large language models (LLMs) can reveal and amplify societal biases during chain-of-thought (CoT) generation. We present COFT (Chain of Fair Thought), a training-free decoding method that applies token-level fairness control at decode time, with distribution-free marginal validity guarantees (under exchangeability) for any frozen causal language model. COFT operates in three stages. First, it creates a masked counterfactual prompt by replacing sensitive spans with neutral tokens. Second, it compares the factual and masked logit distributions through lightweight logit fusion to attenuate attribute-driven biases. Third, it uses dual-branch split-conformal calibration to certify per-step candidate token sets at a user-chosen risk level. We evaluate COFT across six models and multiple bias benchmarks. Our method reduces standard bias metrics by 30-55% (median 38%) while preserving task utility and language quality. Reasoning accuracies remain unchanged within run-to-run noise margins. The computational overhead is modest, equivalent to one additional cached forward pass (<=11%). COFT offers a clear, auditable path to safer CoT generation with significant bias reduction, negligible utility loss, and no requirement for retraining, auxiliary classifiers, or weight access.
TimingLLM: A Two-Stage Retrieval-Augmented Framework for Pre-Synthesis Timing Prediction from Verilog
Apr 26, 2026Early, tool-free prediction of post-synthesis timing remains a key obstacle to rapid RTL iteration. We introduce TimingLLM, a two-stage retrieval-augmented LLM pipeline that estimates worst negative slack (WNS) and total negative slack (TNS) directly from Verilog. Stage 1 is a fine-tuned LLM that acts as a compact post-synthesis timing oracle, producing path-level arrivals/required times that are summarized into lightweight structural-timing cues (e.g., bag-of-gates counts, critical-path depth, gate-type patterns). Stage 2 is an LLM-based regressor that predicts WNS/TNS and applies a learned diagonal steering vector at the last transformer block, computed from the k nearest timing-labeled modules in a disjoint retrieval bank. On VerilogEval, TimingLLM attains R_WNS = 0.91 (MAPE 12%) and R_TNS=0.97 (MAPE 16%) while running 1.3-1.6 times faster than prior methods. Training uses a new 60k-module Verilog corpus with synthesis reports, which we will release. After training once, TimingLLM can be adapted to new technology libraries and PVT corners by refitting only a small regression head on 1000 labeled modules per setting, consistently outperforming state-of-the-art baselines.
One Token Away from Collapse: The Fragility of Instruction-Tuned Helpfulness
Apr 14, 2026Instruction-tuned large language models produce helpful, structured responses, but how robust is this helpfulness when trivially constrained? We show that simple lexical constraints (banning a single punctuation character or common word) cause instruction-tuned LLMs to collapse their responses, losing 14--48% of comprehensiveness in pairwise evaluation across three open-weight model families and one closed-weight model (GPT-4o-mini). The baseline response is preferred in 77--100% of 1,920 pairwise comparisons judged by GPT-4o-mini and GPT-4o. Notably, GPT-4o-mini suffers 31% comprehensiveness loss (99% baseline win rate), demonstrating that the fragility extends to commercially deployed closed-weight models, contrary to prior findings on format-level constraints. Through mechanistic analysis, we identify this as a planning failure: two-pass generation (free generation followed by constrained rewriting) recovers 59--96% of response length, and linear probes on prompt representations predict response length with $R^2 = 0.51$--$0.93$ before generation begins, with $R^2$ tracking collapse severity across models. The same probes yield negative $R^2$ on base models, confirming that instruction tuning creates the representational structure encoding the collapse decision. Crucially, base models show no systematic collapse under identical constraints, with effects that are small, noisy, and bidirectional, demonstrating that instruction tuning creates this fragility by coupling task competence to narrow surface-form templates. The effect replicates on MT-Bench across all eight task categories. We further show that standard independent LLM-as-judge evaluation detects only a 3.5% average quality drop where pairwise evaluation reveals 23%, exposing a methodological blind spot in how constrained generation is assessed.
Sense Less, Infer More: Agentic Multimodal Transformers for Edge Medical Intelligence
Apr 12, 2026Edge-based multimodal medical monitoring requires models that balance diagnostic accuracy with severe energy constraints. Continuous acquisition of ECG, PPG, EMG, and IMU streams rapidly drains wearable batteries, often limiting operation to under 10 hours, while existing systems overlook the high temporal redundancy present in physiological signals. We introduce Adaptive Multimodal Intelligence (AMI), an end-to-end framework that jointly learns when to sense and how to infer. AMI integrates three components: (1) a lightweight Agentic Modality Controller that uses differentiable Gumbel-Sigmoid gating to dynamically select active sensors based on model confidence and task relevance; (2) a Learned Sigma-Delta Sensing module that applies patch-wise Delta-Sigma operations with learnable thresholds to skip temporally redundant samples; and (3) a Foundation-backed Multimodal Prediction Model built on unimodal foundation encoders and a cross-modal transformer with temporal context, enabling robust fusion even under gated or missing inputs. These components are trained jointly via a multi-objective loss combining classification accuracy, sparsity regularization, cross-modal alignment, and predictive coding. AMI is hardware-aware, supporting dynamic computation graphs and masked operations, leading to real energy and latency savings. Across MHEALTH, HMC Sleep, and WESAD datasets, it reduces sensor usage by 48.8% while improving state-of-the-art accuracy by 1.9% on average.
Power-SMC: Low-Latency Sequence-Level Power Sampling for Training-Free LLM Reasoning
Feb 10, 2026Many recent reasoning gains in large language models can be explained as distribution sharpening: biasing generation toward high-likelihood trajectories already supported by the pretrained model, rather than modifying its weights. A natural formalization is the sequence-level power distribution $π_α(y\mid x)\propto p_θ(y\mid x)^α$ ($α>1$), which concentrates mass on whole sequences instead of adjusting token-level temperature. Prior work shows that Metropolis--Hastings (MH) sampling from this distribution recovers strong reasoning performance, but at order-of-magnitude inference slowdowns. We introduce Power-SMC, a training-free Sequential Monte Carlo scheme that targets the same objective while remaining close to standard decoding latency. Power-SMC advances a small particle set in parallel, corrects importance weights token-by-token, and resamples when necessary, all within a single GPU-friendly batched decode. We prove that temperature $τ=1/α$ is the unique prefix-only proposal minimizing incremental weight variance, interpret residual instability via prefix-conditioned Rényi entropies, and introduce an exponent-bridging schedule that improves particle stability without altering the target. On MATH500, Power-SMC matches or exceeds MH power sampling while reducing latency from $16$--$28\times$ to $1.4$--$3.3\times$ over baseline decoding.
SkipKV: Selective Skipping of KV Generation and Storage for Efficient Inference with Large Reasoning Models
Dec 08, 2025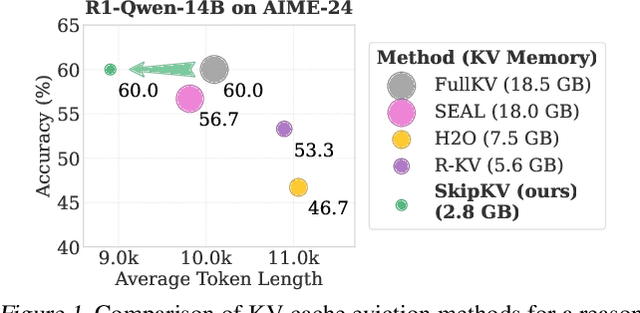
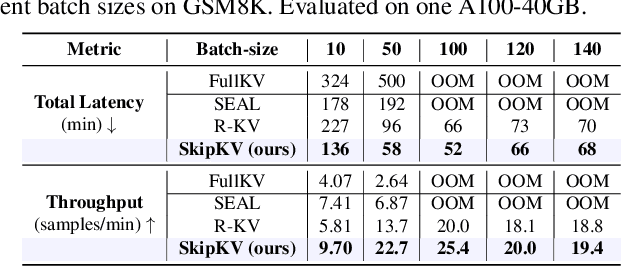
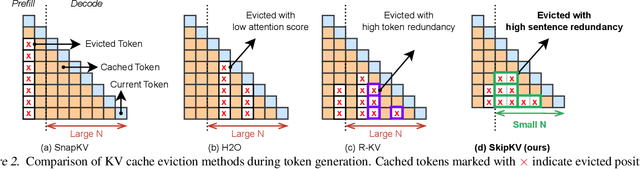
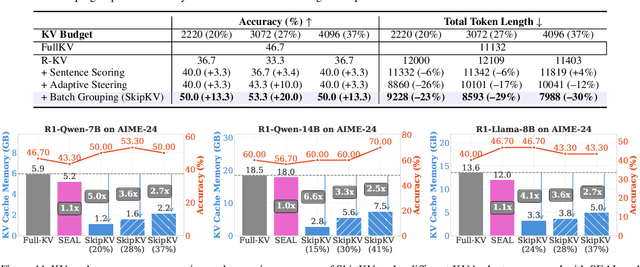
Large reasoning models (LRMs) often cost significant key-value (KV) cache overhead, due to their linear growth with the verbose chain-of-thought (CoT) reasoning process. This costs both memory and throughput bottleneck limiting their efficient deployment. Towards reducing KV cache size during inference, we first investigate the effectiveness of existing KV cache eviction methods for CoT reasoning. Interestingly, we find that due to unstable token-wise scoring and the reduced effective KV budget caused by padding tokens, state-of-the-art (SoTA) eviction methods fail to maintain accuracy in the multi-batch setting. Additionally, these methods often generate longer sequences than the original model, as semantic-unaware token-wise eviction leads to repeated revalidation during reasoning. To address these issues, we present \textbf{SkipKV}, a \textbf{\textit{training-free}} KV compression method for selective \textit{eviction} and \textit{generation} operating at a coarse-grained sentence-level sequence removal for efficient CoT reasoning. In specific, it introduces a \textit{sentence-scoring metric} to identify and remove highly similar sentences while maintaining semantic coherence. To suppress redundant generation, SkipKV dynamically adjusts a steering vector to update the hidden activation states during inference enforcing the LRM to generate concise response. Extensive evaluations on multiple reasoning benchmarks demonstrate the effectiveness of SkipKV in maintaining up to $\mathbf{26.7}\%$ improved accuracy compared to the alternatives, at a similar compression budget. Additionally, compared to SoTA, SkipKV yields up to $\mathbf{1.6}\times$ fewer generation length while improving throughput up to $\mathbf{1.7}\times$.
ASAP-FE: Energy-Efficient Feature Extraction Enabling Multi-Channel Keyword Spotting on Edge Processors
Jun 17, 2025Multi-channel keyword spotting (KWS) has become crucial for voice-based applications in edge environments. However, its substantial computational and energy requirements pose significant challenges. We introduce ASAP-FE (Agile Sparsity-Aware Parallelized-Feature Extractor), a hardware-oriented front-end designed to address these challenges. Our framework incorporates three key innovations: (1) Half-overlapped Infinite Impulse Response (IIR) Framing: This reduces redundant data by approximately 25% while maintaining essential phoneme transition cues. (2) Sparsity-aware Data Reduction: We exploit frame-level sparsity to achieve an additional 50% data reduction by combining frame skipping with stride-based filtering. (3) Dynamic Parallel Processing: We introduce a parameterizable filter cluster and a priority-based scheduling algorithm that allows parallel execution of IIR filtering tasks, reducing latency and optimizing energy efficiency. ASAP-FE is implemented with various filter cluster sizes on edge processors, with functionality verified on FPGA prototypes and designs synthesized at 45 nm. Experimental results using TC-ResNet8, DS-CNN, and KWT-1 demonstrate that ASAP-FE reduces the average workload by 62.73% while supporting real-time processing for up to 32 channels. Compared to a conventional fully overlapped baseline, ASAP-FE achieves less than a 1% accuracy drop (e.g., 96.22% vs. 97.13% for DS-CNN), which is well within acceptable limits for edge AI. By adjusting the number of filter modules, our design optimizes the trade-off between performance and energy, with 15 parallel filters providing optimal performance for up to 25 channels. Overall, ASAP-FE offers a practical and efficient solution for multi-channel KWS on energy-constrained edge devices.
MARCO: Hardware-Aware Neural Architecture Search for Edge Devices with Multi-Agent Reinforcement Learning and Conformal Prediction Filtering
Jun 16, 2025This paper introduces MARCO (Multi-Agent Reinforcement learning with Conformal Optimization), a novel hardware-aware framework for efficient neural architecture search (NAS) targeting resource-constrained edge devices. By significantly reducing search time and maintaining accuracy under strict hardware constraints, MARCO bridges the gap between automated DNN design and CAD for edge AI deployment. MARCO's core technical contribution lies in its unique combination of multi-agent reinforcement learning (MARL) with Conformal Prediction (CP) to accelerate the hardware/software co-design process for deploying deep neural networks. Unlike conventional once-for-all (OFA) supernet approaches that require extensive pretraining, MARCO decomposes the NAS task into a hardware configuration agent (HCA) and a Quantization Agent (QA). The HCA optimizes high-level design parameters, while the QA determines per-layer bit-widths under strict memory and latency budgets using a shared reward signal within a centralized-critic, decentralized-execution (CTDE) paradigm. A key innovation is the integration of a calibrated CP surrogate model that provides statistical guarantees (with a user-defined miscoverage rate) to prune unpromising candidate architectures before incurring the high costs of partial training or hardware simulation. This early filtering drastically reduces the search space while ensuring that high-quality designs are retained with a high probability. Extensive experiments on MNIST, CIFAR-10, and CIFAR-100 demonstrate that MARCO achieves a 3-4x reduction in total search time compared to an OFA baseline while maintaining near-baseline accuracy (within 0.3%). Furthermore, MARCO also reduces inference latency. Validation on a MAX78000 evaluation board confirms that simulator trends hold in practice, with simulator estimates deviating from measured values by less than 5%.
FAIR-SIGHT: Fairness Assurance in Image Recognition via Simultaneous Conformal Thresholding and Dynamic Output Repair
Apr 10, 2025



We introduce FAIR-SIGHT, an innovative post-hoc framework designed to ensure fairness in computer vision systems by combining conformal prediction with a dynamic output repair mechanism. Our approach calculates a fairness-aware non-conformity score that simultaneously assesses prediction errors and fairness violations. Using conformal prediction, we establish an adaptive threshold that provides rigorous finite-sample, distribution-free guarantees. When the non-conformity score for a new image exceeds the calibrated threshold, FAIR-SIGHT implements targeted corrective adjustments, such as logit shifts for classification and confidence recalibration for detection, to reduce both group and individual fairness disparities, all without the need for retraining or having access to internal model parameters. Comprehensive theoretical analysis validates our method's error control and convergence properties. At the same time, extensive empirical evaluations on benchmark datasets show that FAIR-SIGHT significantly reduces fairness disparities while preserving high predictive performance.
RocketPPA: Ultra-Fast LLM-Based PPA Estimator at Code-Level Abstraction
Mar 27, 2025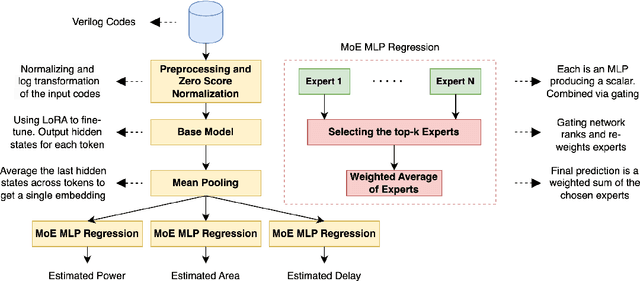
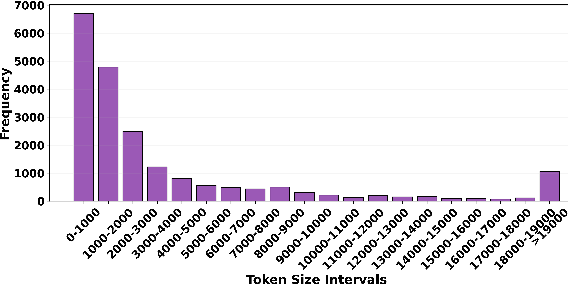
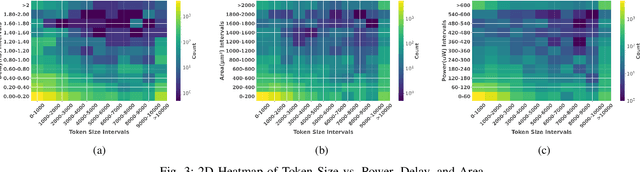
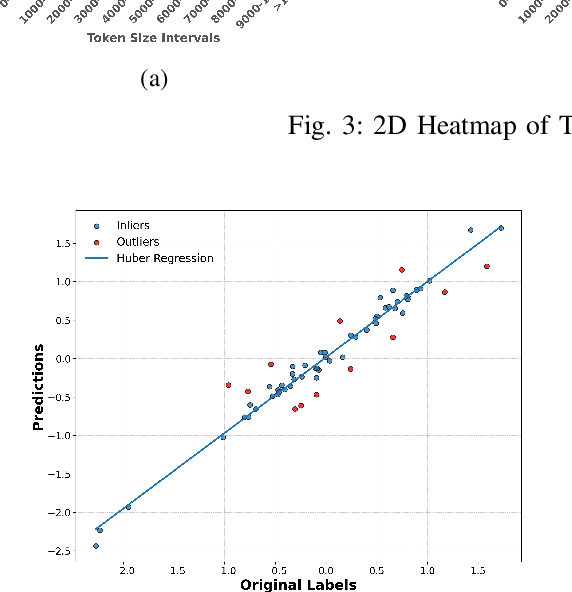
Large language models have recently transformed hardware design, yet bridging the gap between code synthesis and PPA (power, performance, and area) estimation remains a challenge. In this work, we introduce a novel framework that leverages a 21k dataset of thoroughly cleaned and synthesizable Verilog modules, each annotated with detailed power, delay, and area metrics. By employing chain-of-thought techniques, we automatically debug and curate this dataset to ensure high fidelity in downstream applications. We then fine-tune CodeLlama using LoRA-based parameter-efficient methods, framing the task as a regression problem to accurately predict PPA metrics from Verilog code. Furthermore, we augment our approach with a mixture-of-experts architecture-integrating both LoRA and an additional MLP expert layer-to further refine predictions. Experimental results demonstrate significant improvements: power estimation accuracy is enhanced by 5.9% at a 20% error threshold and by 7.2% at a 10% threshold, delay estimation improves by 5.1% and 3.9%, and area estimation sees gains of 4% and 7.9% for the 20% and 10% thresholds, respectively. Notably, the incorporation of the mixture-of-experts module contributes an additional 3--4% improvement across these tasks. Our results establish a new benchmark for PPA-aware Verilog generation, highlighting the effectiveness of our integrated dataset and modeling strategies for next-generation EDA workflows.