 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISTA: Vision-Language Inference for Training-Free Stock Time-Series Analysis
May 24, 2025Stock price prediction remains a complex and high-stakes task in financial analysis, traditionally addressed using statistical models or, more recently, language models. In this work, we introduce VISTA (Vision-Language Inference for Stock Time-series Analysis), a novel, training-free framework that leverages Vision-Language Models (VLMs) for multi-modal stock forecasting. VISTA prompts a VLM with both textual representations of historical stock prices and their corresponding line charts to predict future price values. By combining numerical and visual modalities in a zero-shot setting and using carefully designed chain-of-thought prompts, VISTA captures complementary patterns that unimodal approaches often miss. We benchmark VISTA against standard baselines, including ARIMA and text-only LLM-based prompting methods. Experimental results show that VISTA outperforms these baselines by up to 89.83%, demonstrating the effectiveness of multi-modal inference for stock time-series analysis and highlighting the potential of VLMs in financial forecasting tasks without requiring task-specific training.
Efficient Noise Mitigation for Enhancing Inference Accuracy in DNNs on Mixed-Signal Accelerators
Sep 27, 2024In this paper, we propose a framework to enhance the robustness of the neural models by mitigating the effects of process-induced and aging-related variations of analog computing components on the accuracy of the analog neural networks. We model these variations as the noise affecting the precision of the activations and introduce a denoising block inserted between selected layers of a pre-trained model. We demonstrate that training the denoising block significantly increases the model's robustness against various noise levels. To minimize the overhead associated with adding these blocks, we present an exploration algorithm to identify optimal insertion points for the denoising blocks. Additionally, we propose a specialized architecture to efficiently execute the denoising blocks, which can be integrated into mixed-signal accelerators. We evaluate the effectiveness of our approach using Deep Neural Network (DNN) models trained on the ImageNet and CIFAR-10 datasets. The results show that on average, by accepting 2.03% parameter count overhead, the accuracy drop due to the variations reduces from 31.7% to 1.15%.
CHOSEN: Compilation to Hardware Optimization Stack for Efficient Vision Transformer Inference
Jul 17, 2024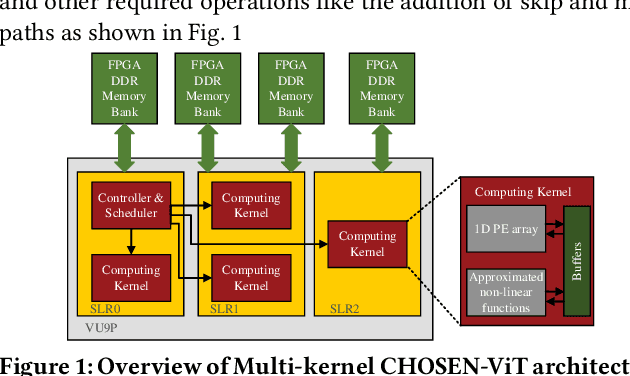
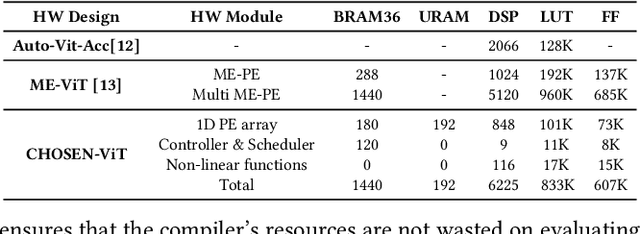
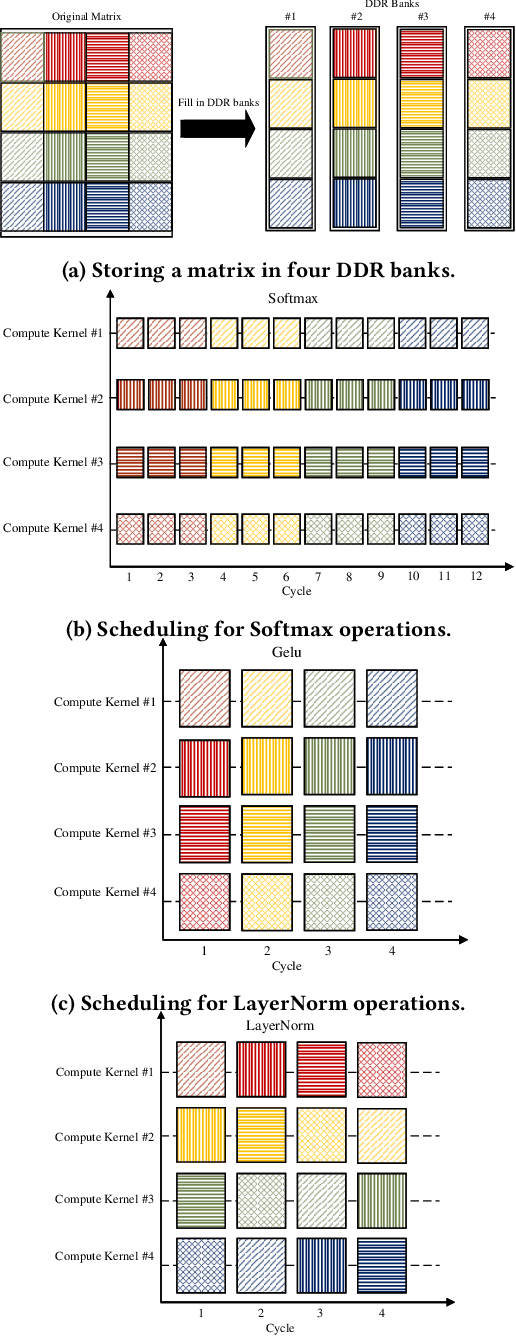
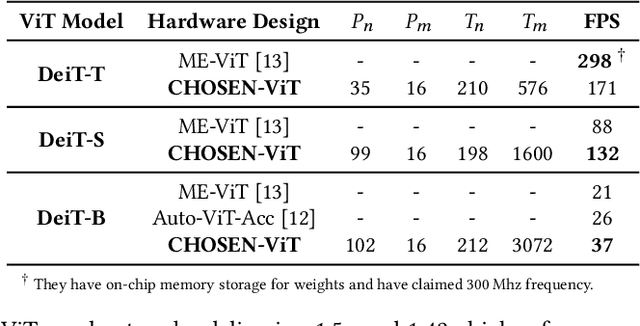
Vision Transformers (ViTs) represent a groundbreaking shift in machine learning approaches to computer vision. Unlike traditional approaches, ViTs employ the self-attention mechanism, which has been widely used in natural language processing, to analyze image patches. Despite their advantages in modeling visual tasks, deploying ViTs on hardware platforms, notably Field-Programmable Gate Arrays (FPGAs), introduces considerable challenges. These challenges stem primarily from the non-linear calculations and high computational and memory demands of ViTs. This paper introduces CHOSEN, a software-hardware co-design framework to address these challenges and offer an automated framework for ViT deployment on the FPGAs in order to maximize performance. Our framework is built upon three fundamental contributions: multi-kernel design to maximize the bandwidth, mainly targeting benefits of multi DDR memory banks, approximate non-linear functions that exhibit minimal accuracy degradation, and efficient use of available logic blocks on the FPGA, and efficient compiler to maximize the performance and memory-efficiency of the computing kernels by presenting a novel algorithm for design space exploration to find optimal hardware configuration that achieves optimal throughput and latency. Compared to the state-of-the-art ViT accelerators, CHOSEN achieves a 1.5x and 1.42x improvement in the throughput on the DeiT-S and DeiT-B models.
PEANO-ViT: Power-Efficient Approximations of Non-Linearities in Vision Transformers
Jun 21, 2024The deployment of Vision Transformers (ViTs) on hardware platforms, specially Field-Programmable Gate Arrays (FPGAs), presents many challenges, which are mainly due to the substantial computational and power requirements of their non-linear functions, notably layer normalization, softmax, and Gaussian Error Linear Unit (GELU). These critical functions pose significant obstacles to efficient hardware implementation due to their complex mathematical operations and the inherent resource count and architectural limitations of FPGAs. PEANO-ViT offers a novel approach to streamlining the implementation of the layer normalization layer by introducing a division-free technique that simultaneously approximates the division and square root function. Additionally, PEANO-ViT provides a multi-scale division strategy to eliminate division operations in the softmax layer, aided by a Pade-based approximation for the exponential function. Finally, PEANO-ViT introduces a piece-wise linear approximation for the GELU function, carefully designed to bypass the computationally intensive operations associated with GELU. In our comprehensive evaluations, PEANO-ViT exhibits minimal accuracy degradation (<= 0.5% for DeiT-B) while significantly enhancing power efficiency, achieving improvements of 1.91x, 1.39x, 8.01x for layer normalization, softmax, and GELU, respectively. This improvement is achieved through substantial reductions in DSP, LUT, and register counts for these non-linear operations. Consequently, PEANO-ViT enables efficient deployment of Vision Transformers on resource- and power-constrained FPGA platforms.