 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Token Away from Collapse: The Fragility of Instruction-Tuned Helpfulness
Apr 14, 2026Instruction-tuned large language models produce helpful, structured responses, but how robust is this helpfulness when trivially constrained? We show that simple lexical constraints (banning a single punctuation character or common word) cause instruction-tuned LLMs to collapse their responses, losing 14--48% of comprehensiveness in pairwise evaluation across three open-weight model families and one closed-weight model (GPT-4o-mini). The baseline response is preferred in 77--100% of 1,920 pairwise comparisons judged by GPT-4o-mini and GPT-4o. Notably, GPT-4o-mini suffers 31% comprehensiveness loss (99% baseline win rate), demonstrating that the fragility extends to commercially deployed closed-weight models, contrary to prior findings on format-level constraints. Through mechanistic analysis, we identify this as a planning failure: two-pass generation (free generation followed by constrained rewriting) recovers 59--96% of response length, and linear probes on prompt representations predict response length with $R^2 = 0.51$--$0.93$ before generation begins, with $R^2$ tracking collapse severity across models. The same probes yield negative $R^2$ on base models, confirming that instruction tuning creates the representational structure encoding the collapse decision. Crucially, base models show no systematic collapse under identical constraints, with effects that are small, noisy, and bidirectional, demonstrating that instruction tuning creates this fragility by coupling task competence to narrow surface-form templates. The effect replicates on MT-Bench across all eight task categories. We further show that standard independent LLM-as-judge evaluation detects only a 3.5% average quality drop where pairwise evaluation reveals 23%, exposing a methodological blind spot in how constrained generation is assessed.
Power-SMC: Low-Latency Sequence-Level Power Sampling for Training-Free LLM Reasoning
Feb 10, 2026Many recent reasoning gains in large language models can be explained as distribution sharpening: biasing generation toward high-likelihood trajectories already supported by the pretrained model, rather than modifying its weights. A natural formalization is the sequence-level power distribution $π_α(y\mid x)\propto p_θ(y\mid x)^α$ ($α>1$), which concentrates mass on whole sequences instead of adjusting token-level temperature. Prior work shows that Metropolis--Hastings (MH) sampling from this distribution recovers strong reasoning performance, but at order-of-magnitude inference slowdowns. We introduce Power-SMC, a training-free Sequential Monte Carlo scheme that targets the same objective while remaining close to standard decoding latency. Power-SMC advances a small particle set in parallel, corrects importance weights token-by-token, and resamples when necessary, all within a single GPU-friendly batched decode. We prove that temperature $τ=1/α$ is the unique prefix-only proposal minimizing incremental weight variance, interpret residual instability via prefix-conditioned Rényi entropies, and introduce an exponent-bridging schedule that improves particle stability without altering the target. On MATH500, Power-SMC matches or exceeds MH power sampling while reducing latency from $16$--$28\times$ to $1.4$--$3.3\times$ over baseline decoding.
SkipKV: Selective Skipping of KV Generation and Storage for Efficient Inference with Large Reasoning Models
Dec 08, 2025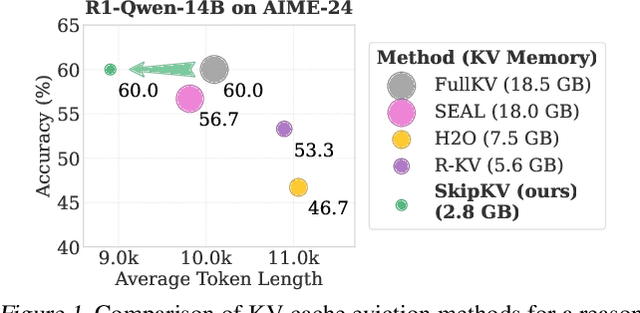
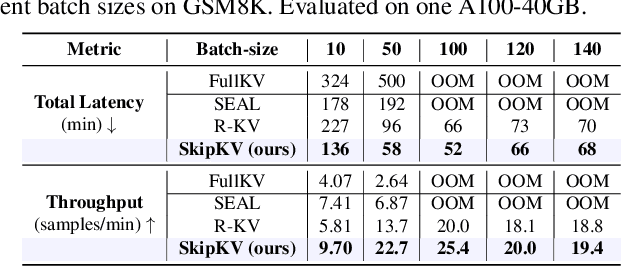
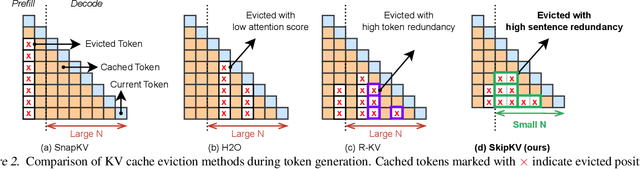
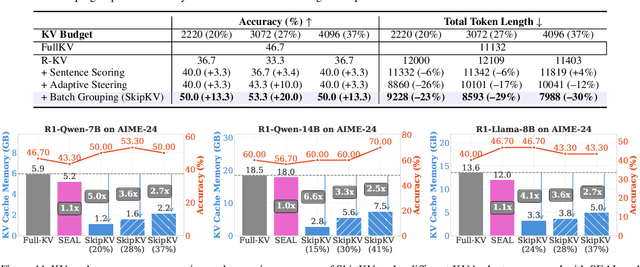
Large reasoning models (LRMs) often cost significant key-value (KV) cache overhead, due to their linear growth with the verbose chain-of-thought (CoT) reasoning process. This costs both memory and throughput bottleneck limiting their efficient deployment. Towards reducing KV cache size during inference, we first investigate the effectiveness of existing KV cache eviction methods for CoT reasoning. Interestingly, we find that due to unstable token-wise scoring and the reduced effective KV budget caused by padding tokens, state-of-the-art (SoTA) eviction methods fail to maintain accuracy in the multi-batch setting. Additionally, these methods often generate longer sequences than the original model, as semantic-unaware token-wise eviction leads to repeated revalidation during reasoning. To address these issues, we present \textbf{SkipKV}, a \textbf{\textit{training-free}} KV compression method for selective \textit{eviction} and \textit{generation} operating at a coarse-grained sentence-level sequence removal for efficient CoT reasoning. In specific, it introduces a \textit{sentence-scoring metric} to identify and remove highly similar sentences while maintaining semantic coherence. To suppress redundant generation, SkipKV dynamically adjusts a steering vector to update the hidden activation states during inference enforcing the LRM to generate concise response. Extensive evaluations on multiple reasoning benchmarks demonstrate the effectiveness of SkipKV in maintaining up to $\mathbf{26.7}\%$ improved accuracy compared to the alternatives, at a similar compression budget. Additionally, compared to SoTA, SkipKV yields up to $\mathbf{1.6}\times$ fewer generation length while improving throughput up to $\mathbf{1.7}\times$.
VISTA: Vision-Language Inference for Training-Free Stock Time-Series Analysis
May 24, 2025Stock price prediction remains a complex and high-stakes task in financial analysis, traditionally addressed using statistical models or, more recently, language models. In this work, we introduce VISTA (Vision-Language Inference for Stock Time-series Analysis), a novel, training-free framework that leverages Vision-Language Models (VLMs) for multi-modal stock forecasting. VISTA prompts a VLM with both textual representations of historical stock prices and their corresponding line charts to predict future price values. By combining numerical and visual modalities in a zero-shot setting and using carefully designed chain-of-thought prompts, VISTA captures complementary patterns that unimodal approaches often miss. We benchmark VISTA against standard baselines, including ARIMA and text-only LLM-based prompting methods. Experimental results show that VISTA outperforms these baselines by up to 89.83%, demonstrating the effectiveness of multi-modal inference for stock time-series analysis and highlighting the potential of VLMs in financial forecasting tasks without requiring task-specific training.
Efficient Noise Mitigation for Enhancing Inference Accuracy in DNNs on Mixed-Signal Accelerators
Sep 27, 2024In this paper, we propose a framework to enhance the robustness of the neural models by mitigating the effects of process-induced and aging-related variations of analog computing components on the accuracy of the analog neural networks. We model these variations as the noise affecting the precision of the activations and introduce a denoising block inserted between selected layers of a pre-trained model. We demonstrate that training the denoising block significantly increases the model's robustness against various noise levels. To minimize the overhead associated with adding these blocks, we present an exploration algorithm to identify optimal insertion points for the denoising blocks. Additionally, we propose a specialized architecture to efficiently execute the denoising blocks, which can be integrated into mixed-signal accelerators. We evaluate the effectiveness of our approach using Deep Neural Network (DNN) models trained on the ImageNet and CIFAR-10 datasets. The results show that on average, by accepting 2.03% parameter count overhead, the accuracy drop due to the variations reduces from 31.7% to 1.15%.
PEANO-ViT: Power-Efficient Approximations of Non-Linearities in Vision Transformers
Jun 21, 2024The deployment of Vision Transformers (ViTs) on hardware platforms, specially Field-Programmable Gate Arrays (FPGAs), presents many challenges, which are mainly due to the substantial computational and power requirements of their non-linear functions, notably layer normalization, softmax, and Gaussian Error Linear Unit (GELU). These critical functions pose significant obstacles to efficient hardware implementation due to their complex mathematical operations and the inherent resource count and architectural limitations of FPGAs. PEANO-ViT offers a novel approach to streamlining the implementation of the layer normalization layer by introducing a division-free technique that simultaneously approximates the division and square root function. Additionally, PEANO-ViT provides a multi-scale division strategy to eliminate division operations in the softmax layer, aided by a Pade-based approximation for the exponential function. Finally, PEANO-ViT introduces a piece-wise linear approximation for the GELU function, carefully designed to bypass the computationally intensive operations associated with GELU. In our comprehensive evaluations, PEANO-ViT exhibits minimal accuracy degradation (<= 0.5% for DeiT-B) while significantly enhancing power efficiency, achieving improvements of 1.91x, 1.39x, 8.01x for layer normalization, softmax, and GELU, respectively. This improvement is achieved through substantial reductions in DSP, LUT, and register counts for these non-linear operations. Consequently, PEANO-ViT enables efficient deployment of Vision Transformers on resource- and power-constrained FPGA platforms.
LaMDA: Large Model Fine-Tuning via Spectrally Decomposed Low-Dimensional Adaptation
Jun 18, 2024Low-rank adaptation (LoRA) has become the default approach to fine-tune large language models (LLMs) due to its significant reduction in trainable parameters. However, trainable parameter demand for LoRA increases with increasing model embedding dimensions, leading to high compute costs. Additionally, its backward updates require storing high-dimensional intermediate activations and optimizer states, demanding high peak GPU memory. In this paper, we introduce large model fine-tuning via spectrally decomposed low-dimensional adaptation (LaMDA), a novel approach to fine-tuning large language models, which leverages low-dimensional adaptation to achieve significant reductions in trainable parameters and peak GPU memory footprint. LaMDA freezes a first projection matrix (PMA) in the adaptation path while introducing a low-dimensional trainable square matrix, resulting in substantial reductions in trainable parameters and peak GPU memory usage. LaMDA gradually freezes a second projection matrix (PMB) during the early fine-tuning stages, reducing the compute cost associated with weight updates to enhance parameter efficiency further. We also present an enhancement, LaMDA++, incorporating a ``lite-weight" adaptive rank allocation for the LoRA path via normalized spectrum analysis of pre-trained model weights. We evaluate LaMDA/LaMDA++ across various tasks, including natural language understanding with the GLUE benchmark, text summarization, natural language generation, and complex reasoning on different LLMs. Results show that LaMDA matches or surpasses the performance of existing alternatives while requiring up to 17.7x fewer parameter updates and up to 1.32x lower peak GPU memory usage during fine-tuning. Code will be publicly available.
Memory-Efficient Vision Transformers: An Activation-Aware Mixed-Rank Compression Strategy
Feb 08, 2024As Vision Transformers (ViTs) increasingly set new benchmarks in computer vision, their practical deployment on inference engines is often hindered by their significant memory bandwidth and (on-chip) memory footprint requirements. This paper addresses this memory limitation by introducing an activation-aware model compression methodology that uses selective low-rank weight tensor approximations of different layers to reduce the parameter count of ViTs. The key idea is to decompose the weight tensors into a sum of two parameter-efficient tensors while minimizing the error between the product of the input activations with the original weight tensor and the product of the input activations with the approximate tensor sum. This approximation is further refined by adopting an efficient layer-wise error compensation technique that uses the gradient of the layer's output loss. The combination of these techniques achieves excellent results while it avoids being trapped in a shallow local minimum early in the optimization process and strikes a good balance between the model compression and output accuracy. Notably, the presented method significantly reduces the parameter count of DeiT-B by 60% with less than 1% accuracy drop on the ImageNet dataset, overcoming the usual accuracy degradation seen in low-rank approximations. In addition to this, the presented compression technique can compress large DeiT/ViT models to have about the same model size as smaller DeiT/ViT variants while yielding up to 1.8% accuracy gain. These results highlight the efficacy of our approach, presenting a viable solution for embedding ViTs in memory-constrained environments without compromising their performance.
Low-Precision Mixed-Computation Models for Inference on Edge
Dec 03, 2023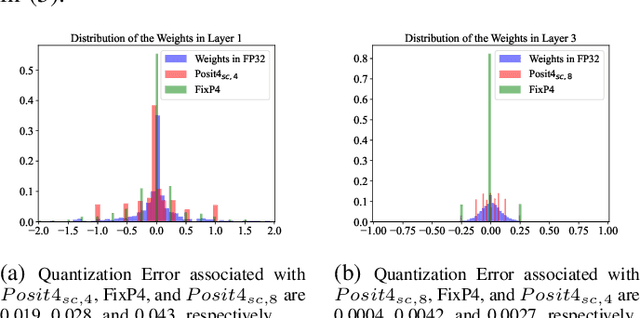
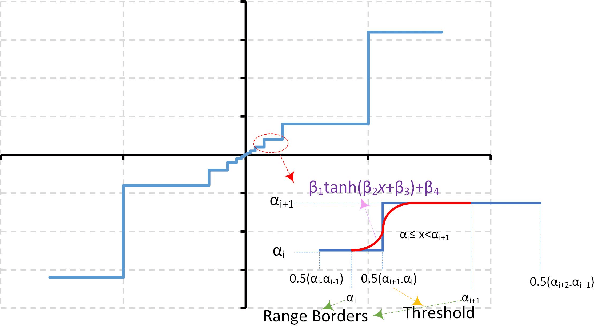
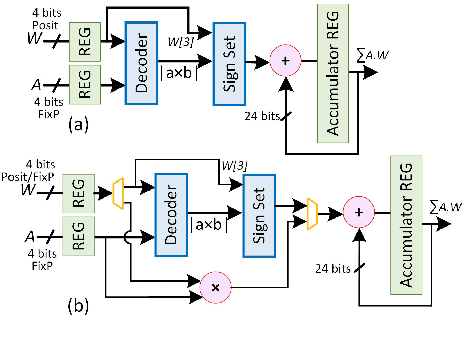
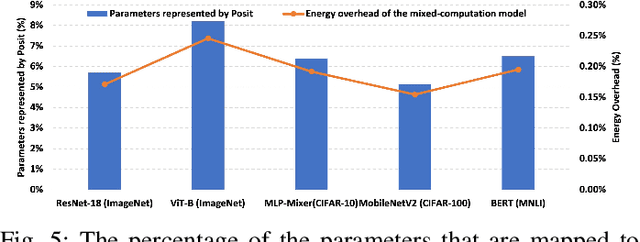
This paper presents a mixed-computation neural network processing approach for edge applications that incorporates low-precision (low-width) Posit and low-precision fixed point (FixP) number systems. This mixed-computation approach employs 4-bit Posit (Posit4), which has higher precision around zero, for representing weights with high sensitivity, while it uses 4-bit FixP (FixP4) for representing other weights. A heuristic for analyzing the importance and the quantization error of the weights is presented to assign the proper number system to different weights. Additionally, a gradient approximation for Posit representation is introduced to improve the quality of weight updates in the backpropagation process. Due to the high energy consumption of the fully Posit-based computations, neural network operations are carried out in FixP or Posit/FixP. An efficient hardware implementation of a MAC operation with a first Posit operand and FixP for a second operand and accumulator is presented. The efficacy of the proposed low-precision mixed-computation approach is extensively assessed on vision and language models. The results show that, on average, the accuracy of the mixed-computation is about 1.5% higher than that of FixP with a cost of 0.19% energy overhead.
Sensitivity-Aware Mixed-Precision Quantization and Width Optimization of Deep Neural Networks Through Cluster-Based Tree-Structured Parzen Estimation
Aug 16, 2023As the complexity and computational demands of deep learning models rise, the need for effective optimization methods for neural network designs becomes paramount. This work introduces an innovative search mechanism for automatically selecting the best bit-width and layer-width for individual neural network layers. This leads to a marked enhancement in deep neural network efficiency. The search domain is strategically reduced by leveraging Hessian-based pruning, ensuring the removal of non-crucial parameters. Subsequently, we detail the development of surrogate models for favorable and unfavorable outcomes by employing a cluster-based tree-structured Parzen estimator. This strategy allows for a streamlined exploration of architectural possibilities and swift pinpointing of top-performing designs. Through rigorous testing on well-known datasets, our method proves its distinct advantage over existing methods. Compared to leading compression strategies, our approach records an impressive 20% decrease in model size without compromising accuracy. Additionally, our method boasts a 12x reduction in search time relative to the best search-focused strategies currently available. As a result, our proposed method represents a leap forward in neural network design optimization, paving the way for quick model design and implementation in settings with limited resources, thereby propelling the potential of scalable deep learning solutions.