 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAW-INT4: System-Aware 4-Bit KV-Cache Quantization for Real-World LLM Serving
Apr 21, 2026KV-cache memory is a major bottleneck in real-world LLM serving, where systems must simultaneously support latency-sensitive small-batch requests and high-throughput concurrent workloads. Although many KV-cache compression methods improve offline accuracy or compression ratio, they often violate practical serving constraints such as paged memory layouts, regular memory access, and fused attention execution, limiting their effectiveness in deployment. In this work, we identify the minimal set of 4-bit KV-cache quantization methods that remain viable under these constraints. Our central finding is that a simple design--token-wise INT4 quantization with block-diagonal Hadamard rotation--consistently achieves the best accuracy-efficiency trade-off. Across multiple models and benchmarks, this approach recovers nearly all of the accuracy lost by naive INT4, while more complex methods such as vector quantization and Hessian-aware quantization provide only marginal additional gains once serving compatibility is taken into account. To make this practical, we implement a fused rotation-quantization kernel that integrates directly into paged KV-cache layouts and introduces zero measurable end-to-end overhead, matching plain INT4 throughput across concurrency levels. Our results show that effective KV-cache compression is fundamentally a systems co-design problem: under real serving constraints, lightweight block-diagonal Hadamard rotation is a viable method that delivers near-lossless accuracy without sacrificing serving efficiency.
Rethinking Channel Dimensions to Isolate Outliers for Low-bit Weight Quantization of Large Language Models
Sep 27, 2023Large Language Models (LLMs) have recently demonstrated a remarkable success across various tasks. However, efficiently serving LLMs has been a challenge due to its large memory bottleneck, specifically in small batch inference settings (e.g. mobile devices). Weight-only quantization can be a promising approach, but sub-4 bit quantization remains a challenge due to large-magnitude activation outliers. To mitigate the undesirable outlier effect, we first propose per-IC quantization, a simple yet effective method that creates quantization groups within each input channel (IC) rather than the conventional per-output channel (OC). Our method is motivated by the observation that activation outliers affect the input dimension of the weight matrix, so similarly grouping the weights in the IC direction can isolate outliers to be within a group. We also find that activation outliers do not dictate quantization difficulty, and inherent weight sensitivities also exist. With per-IC quantization as a new outlier-friendly scheme, we then propose Adaptive Dimensions (AdaDim), a versatile quantization framework that can adapt to various weight sensitivity patterns. We demonstrate the effectiveness of AdaDim by augmenting prior methods such as Round-To-Nearest and GPTQ, showing significant improvements across various language modeling benchmarks for both base (up to +4.7% on MMLU) and instruction-tuned (up to +10% on HumanEval) LLMs.
SNT: Sharpness-Minimizing Network Transformation for Fast Compression-friendly Pretraining
May 08, 2023Model compression has become the de-facto approach for optimizing the efficiency of vision models. Recently, the focus of most compression efforts has shifted to post-training scenarios due to the very high cost of large-scale pretraining. This has created the need to build compressible models from scratch, which can effectively be compressed after training. In this work, we present a sharpness-minimizing network transformation (SNT) method applied during pretraining that can create models with desirable compressibility and generalizability features. We compare our approach to a well-known sharpness-minimizing optimizer to validate its efficacy in creating a flat loss landscape. To the best of our knowledge, SNT is the first pretraining method that uses an architectural transformation to generate compression-friendly networks. We find that SNT generalizes across different compression tasks and network backbones, delivering consistent improvements over the ADAM baseline with up to 2% accuracy improvement on weight pruning and 5.4% accuracy improvement on quantization. Code to reproduce our results will be made publicly available.
A Fast Training-Free Compression Framework for Vision Transformers
Mar 04, 2023Token pruning has emerged as an effective solution to speed up the inference of large Transformer models. However, prior work on accelerating Vision Transformer (ViT) models requires training from scratch or fine-tuning with additional parameters, which prevents a simple plug-and-play. To avoid high training costs during the deployment stage, we present a fast training-free compression framework enabled by (i) a dense feature extractor in the initial layers; (ii) a sharpness-minimized model which is more compressible; and (iii) a local-global token merger that can exploit spatial relationships at various contexts. We applied our framework to various ViT and DeiT models and achieved up to 2x reduction in FLOPS and 1.8x speedup in inference throughput with <1% accuracy loss, while saving two orders of magnitude shorter training times than existing approaches. Code will be available at https://github.com/johnheo/fast-compress-vit
Sparse Periodic Systolic Dataflow for Lowering Latency and Power Dissipation of Convolutional Neural Network Accelerators
Jun 30, 2022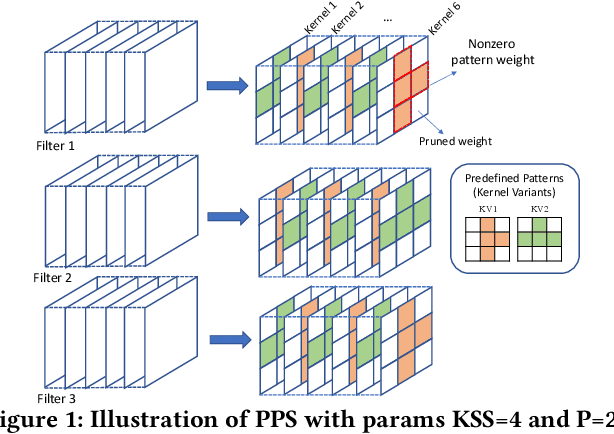
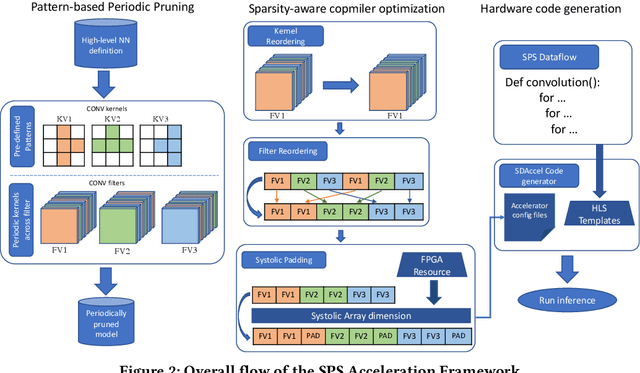
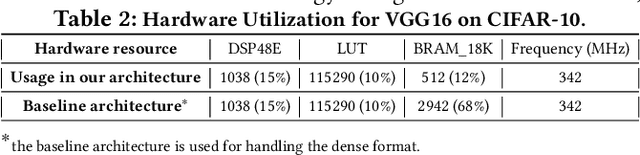
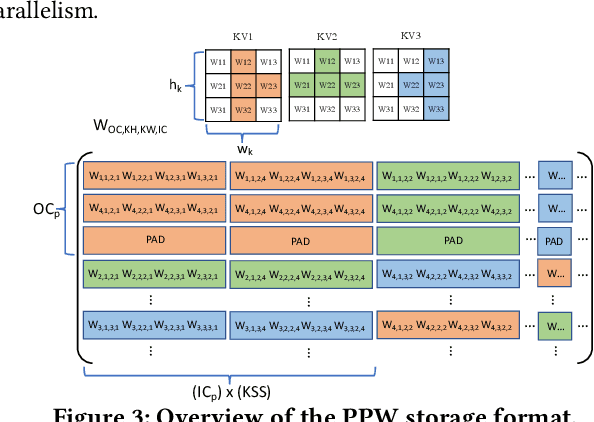
This paper introduces the sparse periodic systolic (SPS) dataflow, which advances the state-of-the-art hardware accelerator for supporting lightweight neural networks. Specifically, the SPS dataflow enables a novel hardware design approach unlocked by an emergent pruning scheme, periodic pattern-based sparsity (PPS). By exploiting the regularity of PPS, our sparsity-aware compiler optimally reorders the weights and uses a simple indexing unit in hardware to create matches between the weights and activations. Through the compiler-hardware codesign, SPS dataflow enjoys higher degrees of parallelism while being free of the high indexing overhead and without model accuracy loss. Evaluated on popular benchmarks such as VGG and ResNet, the SPS dataflow and accompanying neural network compiler outperform prior work in convolutional neural network (CNN) accelerator designs targeting FPGA devices. Against other sparsity-supporting weight storage formats, SPS results in 4.49x energy efficiency gain while lowering storage requirements by 3.67x for total weight storage (non-pruned weights plus indexing) and 22,044x for indexing memory.