 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHOSEN: Compilation to Hardware Optimization Stack for Efficient Vision Transformer Inference
Jul 17, 2024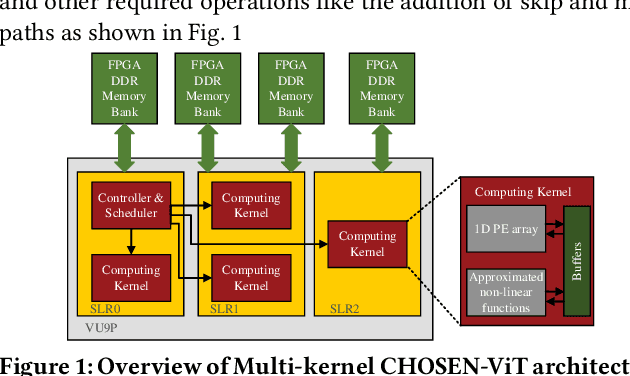
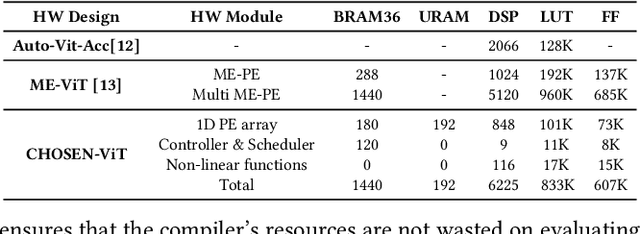
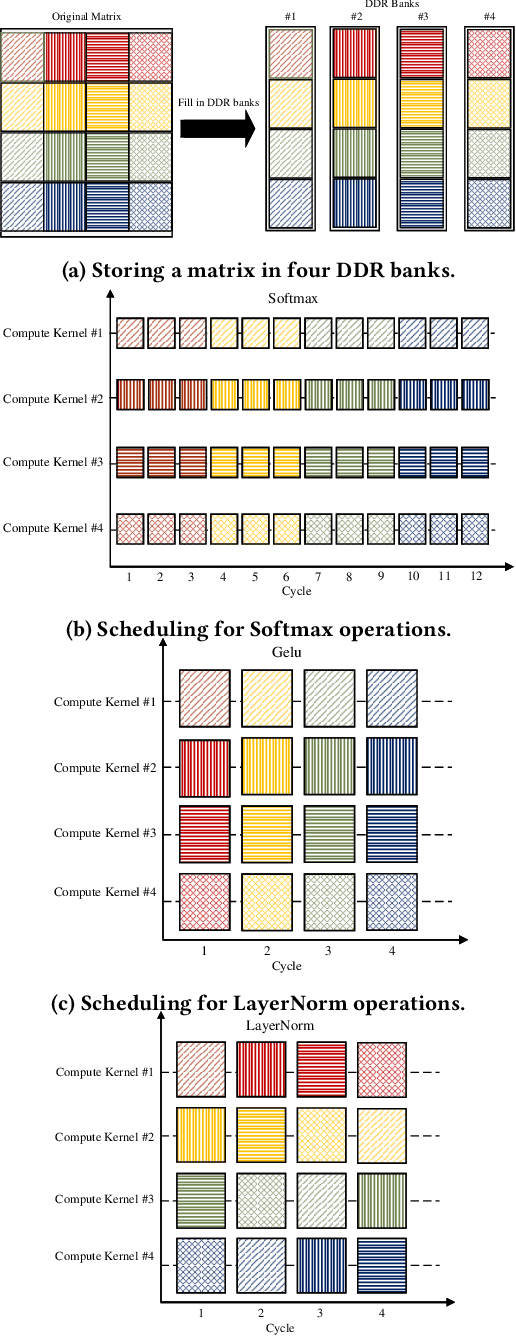
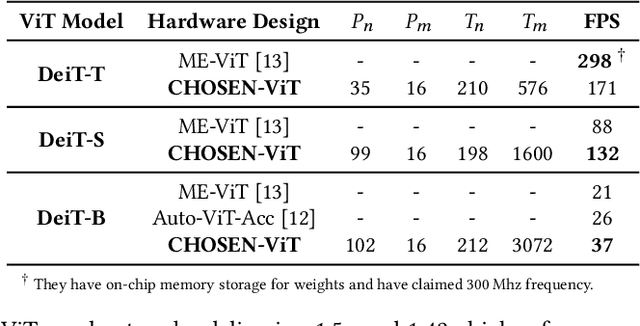
Vision Transformers (ViTs) represent a groundbreaking shift in machine learning approaches to computer vision. Unlike traditional approaches, ViTs employ the self-attention mechanism, which has been widely used in natural language processing, to analyze image patches. Despite their advantages in modeling visual tasks, deploying ViTs on hardware platforms, notably Field-Programmable Gate Arrays (FPGAs), introduces considerable challenges. These challenges stem primarily from the non-linear calculations and high computational and memory demands of ViTs. This paper introduces CHOSEN, a software-hardware co-design framework to address these challenges and offer an automated framework for ViT deployment on the FPGAs in order to maximize performance. Our framework is built upon three fundamental contributions: multi-kernel design to maximize the bandwidth, mainly targeting benefits of multi DDR memory banks, approximate non-linear functions that exhibit minimal accuracy degradation, and efficient use of available logic blocks on the FPGA, and efficient compiler to maximize the performance and memory-efficiency of the computing kernels by presenting a novel algorithm for design space exploration to find optimal hardware configuration that achieves optimal throughput and latency. Compared to the state-of-the-art ViT accelerators, CHOSEN achieves a 1.5x and 1.42x improvement in the throughput on the DeiT-S and DeiT-B models.
PEANO-ViT: Power-Efficient Approximations of Non-Linearities in Vision Transformers
Jun 21, 2024The deployment of Vision Transformers (ViTs) on hardware platforms, specially Field-Programmable Gate Arrays (FPGAs), presents many challenges, which are mainly due to the substantial computational and power requirements of their non-linear functions, notably layer normalization, softmax, and Gaussian Error Linear Unit (GELU). These critical functions pose significant obstacles to efficient hardware implementation due to their complex mathematical operations and the inherent resource count and architectural limitations of FPGAs. PEANO-ViT offers a novel approach to streamlining the implementation of the layer normalization layer by introducing a division-free technique that simultaneously approximates the division and square root function. Additionally, PEANO-ViT provides a multi-scale division strategy to eliminate division operations in the softmax layer, aided by a Pade-based approximation for the exponential function. Finally, PEANO-ViT introduces a piece-wise linear approximation for the GELU function, carefully designed to bypass the computationally intensive operations associated with GELU. In our comprehensive evaluations, PEANO-ViT exhibits minimal accuracy degradation (<= 0.5% for DeiT-B) while significantly enhancing power efficiency, achieving improvements of 1.91x, 1.39x, 8.01x for layer normalization, softmax, and GELU, respectively. This improvement is achieved through substantial reductions in DSP, LUT, and register counts for these non-linear operations. Consequently, PEANO-ViT enables efficient deployment of Vision Transformers on resource- and power-constrained FPGA platforms.
Scalable Superconductor Neuron with Ternary Synaptic Connections for Ultra-Fast SNN Hardware
Feb 27, 2024



A novel high-fan-in differential superconductor neuron structure designed for ultra-high-performance Spiking Neural Network (SNN) accelerators is presented. Utilizing a high-fan-in neuron structure allows us to design SNN accelerators with more synaptic connections, enhancing the overall network capabilities. The proposed neuron design is based on superconductor electronics fabric, incorporating multiple superconducting loops, each with two Josephson Junctions. This arrangement enables each input data branch to have positive and negative inductive coupling, supporting excitatory and inhibitory synaptic data. Compatibility with synaptic devices and thresholding operation is achieved using a single flux quantum (SFQ) pulse-based logic style. The neuron design, along with ternary synaptic connections, forms the foundation for a superconductor-based SNN inference. To demonstrate the capabilities of our design, we train the SNN using snnTorch, augmenting the PyTorch framework. After pruning, the demonstrated SNN inference achieves an impressive 96.1% accuracy on MNIST images. Notably, the network exhibits a remarkable throughput of 8.92 GHz while consuming only 1.5 nJ per inference, including the energy consumption associated with cooling to 4K. These results underscore the potential of superconductor electronics in developing high-performance and ultra-energy-efficient neural network accelerator architectures.
Sensitivity-Aware Mixed-Precision Quantization and Width Optimization of Deep Neural Networks Through Cluster-Based Tree-Structured Parzen Estimation
Aug 16, 2023As the complexity and computational demands of deep learning models rise, the need for effective optimization methods for neural network designs becomes paramount. This work introduces an innovative search mechanism for automatically selecting the best bit-width and layer-width for individual neural network layers. This leads to a marked enhancement in deep neural network efficiency. The search domain is strategically reduced by leveraging Hessian-based pruning, ensuring the removal of non-crucial parameters. Subsequently, we detail the development of surrogate models for favorable and unfavorable outcomes by employing a cluster-based tree-structured Parzen estimator. This strategy allows for a streamlined exploration of architectural possibilities and swift pinpointing of top-performing designs. Through rigorous testing on well-known datasets, our method proves its distinct advantage over existing methods. Compared to leading compression strategies, our approach records an impressive 20% decrease in model size without compromising accuracy. Additionally, our method boasts a 12x reduction in search time relative to the best search-focused strategies currently available. As a result, our proposed method represents a leap forward in neural network design optimization, paving the way for quick model design and implementation in settings with limited resources, thereby propelling the potential of scalable deep learning solutions.
SNT: Sharpness-Minimizing Network Transformation for Fast Compression-friendly Pretraining
May 08, 2023Model compression has become the de-facto approach for optimizing the efficiency of vision models. Recently, the focus of most compression efforts has shifted to post-training scenarios due to the very high cost of large-scale pretraining. This has created the need to build compressible models from scratch, which can effectively be compressed after training. In this work, we present a sharpness-minimizing network transformation (SNT) method applied during pretraining that can create models with desirable compressibility and generalizability features. We compare our approach to a well-known sharpness-minimizing optimizer to validate its efficacy in creating a flat loss landscape. To the best of our knowledge, SNT is the first pretraining method that uses an architectural transformation to generate compression-friendly networks. We find that SNT generalizes across different compression tasks and network backbones, delivering consistent improvements over the ADAM baseline with up to 2% accuracy improvement on weight pruning and 5.4% accuracy improvement on quantization. Code to reproduce our results will be made publicly available.
A Fast Training-Free Compression Framework for Vision Transformers
Mar 04, 2023Token pruning has emerged as an effective solution to speed up the inference of large Transformer models. However, prior work on accelerating Vision Transformer (ViT) models requires training from scratch or fine-tuning with additional parameters, which prevents a simple plug-and-play. To avoid high training costs during the deployment stage, we present a fast training-free compression framework enabled by (i) a dense feature extractor in the initial layers; (ii) a sharpness-minimized model which is more compressible; and (iii) a local-global token merger that can exploit spatial relationships at various contexts. We applied our framework to various ViT and DeiT models and achieved up to 2x reduction in FLOPS and 1.8x speedup in inference throughput with <1% accuracy loss, while saving two orders of magnitude shorter training times than existing approaches. Code will be available at https://github.com/johnheo/fast-compress-vit
Efficient Compilation and Mapping of Fixed Function Combinational Logic onto Digital Signal Processors Targeting Neural Network Inference and Utilizing High-level Synthesis
Jul 30, 2022
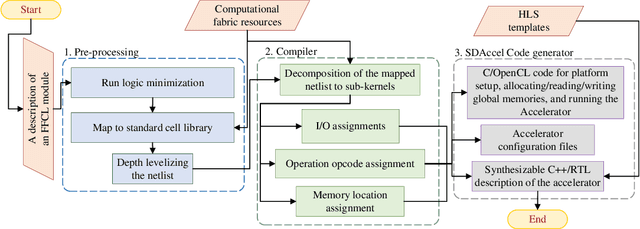
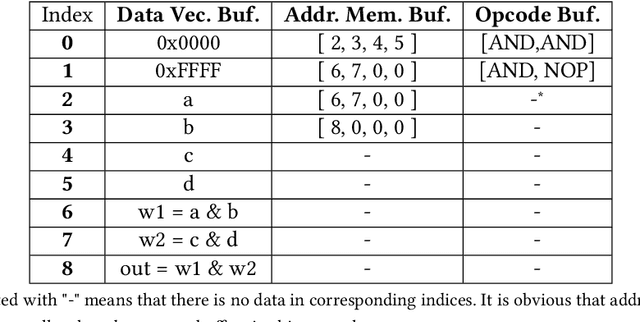
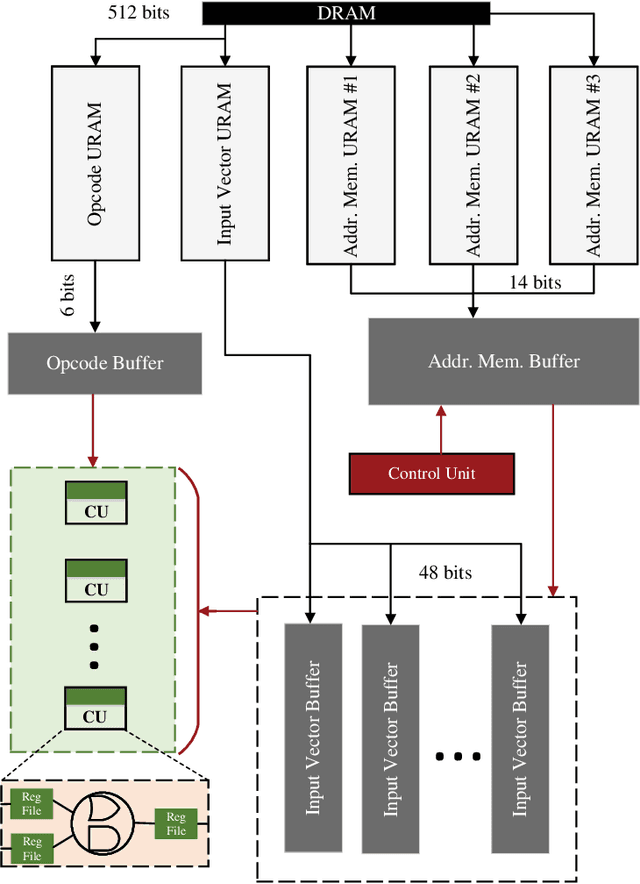
Recent efforts for improving the performance of neural network (NN) accelerators that meet today's application requirements have given rise to a new trend of logic-based NN inference relying on fixed function combinational logic. Mapping such large Boolean functions with many input variables and product terms to digital signal processors (DSPs) on Field-programmable gate arrays (FPGAs) needs a novel framework considering the structure and the reconfigurability of DSP blocks during this process. The proposed methodology in this paper maps the fixed function combinational logic blocks to a set of Boolean functions where Boolean operations corresponding to each function are mapped to DSP devices rather than look-up tables (LUTs) on the FPGAs to take advantage of the high performance, low latency, and parallelism of DSP blocks. % This paper also presents an innovative design and optimization methodology for compilation and mapping of NNs, utilizing fixed function combinational logic to DSPs on FPGAs employing high-level synthesis flow. % Our experimental evaluations across several \REVone{datasets} and selected NNs demonstrate the comparable performance of our framework in terms of the inference latency and output accuracy compared to prior art FPGA-based NN accelerators employing DSPs.
Sparse Periodic Systolic Dataflow for Lowering Latency and Power Dissipation of Convolutional Neural Network Accelerators
Jun 30, 2022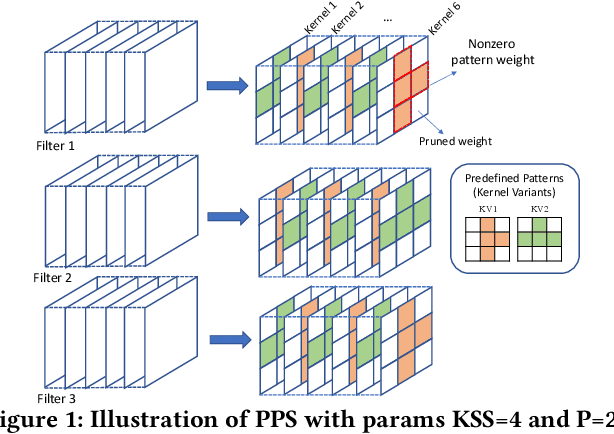
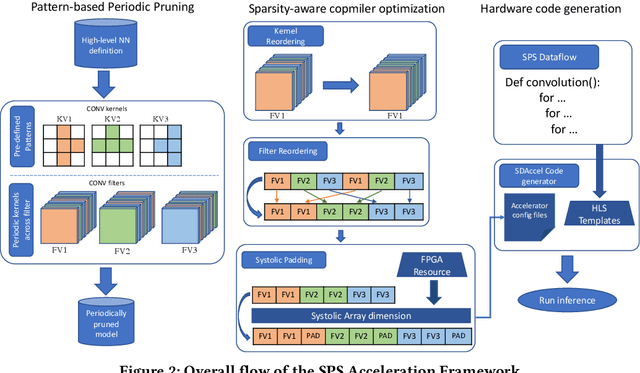
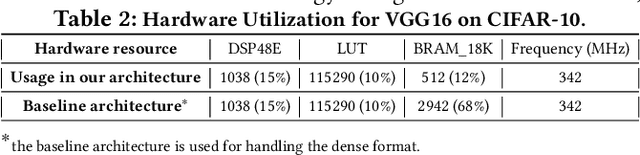
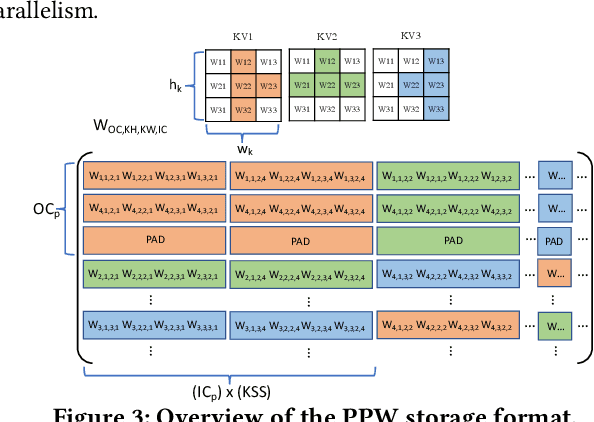
This paper introduces the sparse periodic systolic (SPS) dataflow, which advances the state-of-the-art hardware accelerator for supporting lightweight neural networks. Specifically, the SPS dataflow enables a novel hardware design approach unlocked by an emergent pruning scheme, periodic pattern-based sparsity (PPS). By exploiting the regularity of PPS, our sparsity-aware compiler optimally reorders the weights and uses a simple indexing unit in hardware to create matches between the weights and activations. Through the compiler-hardware codesign, SPS dataflow enjoys higher degrees of parallelism while being free of the high indexing overhead and without model accuracy loss. Evaluated on popular benchmarks such as VGG and ResNet, the SPS dataflow and accompanying neural network compiler outperform prior work in convolutional neural network (CNN) accelerator designs targeting FPGA devices. Against other sparsity-supporting weight storage formats, SPS results in 4.49x energy efficiency gain while lowering storage requirements by 3.67x for total weight storage (non-pruned weights plus indexing) and 22,044x for indexing memory.
NullaNet Tiny: Ultra-low-latency DNN Inference Through Fixed-function Combinational Logic
Apr 07, 2021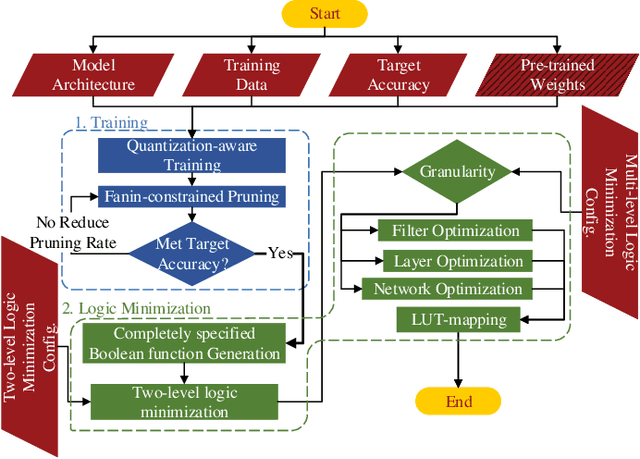
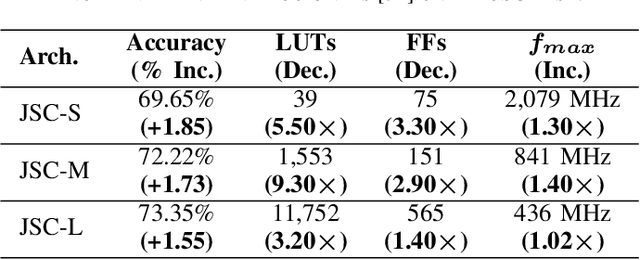
While there is a large body of research on efficient processing of deep neural networks (DNNs), ultra-low-latency realization of these models for applications with stringent, sub-microsecond latency requirements continues to be an unresolved, challenging problem. Field-programmable gate array (FPGA)-based DNN accelerators are gaining traction as a serious contender to replace graphics processing unit/central processing unit-based platforms considering their performance, flexibility, and energy efficiency. This paper presents NullaNet Tiny, an across-the-stack design and optimization framework for constructing resource and energy-efficient, ultra-low-latency FPGA-based neural network accelerators. The key idea is to replace expensive operations required to compute various filter/neuron functions in a DNN with Boolean logic expressions that are mapped to the native look-up tables (LUTs) of the FPGA device (examples of such operations are multiply-and-accumulate and batch normalization). At about the same level of classification accuracy, compared to Xilinx's LogicNets, our design achieves 2.36$\times$ lower latency and 24.42$\times$ lower LUT utilization.
SynergicLearning: Neural Network-Based Feature Extraction for Highly-Accurate Hyperdimensional Learning
Aug 04, 2020
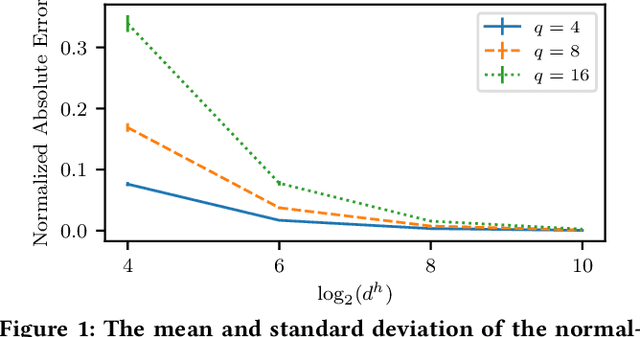
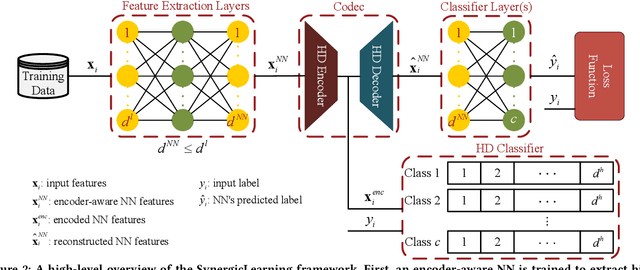

Machine learning models differ in terms of accuracy, computational/memory complexity, training time, and adaptability among other characteristics. For example, neural networks (NNs) are well-known for their high accuracy due to the quality of their automatic feature extraction while brain-inspired hyperdimensional (HD) learning models are famous for their quick training, computational efficiency, and adaptability. This work presents a hybrid, synergic machine learning model that excels at all the said characteristics and is suitable for incremental, on-line learning on a chip. The proposed model comprises an NN and a classifier. The NN acts as a feature extractor and is specifically trained to work well with the classifier that employs the HD computing framework. This work also presents a parameterized hardware implementation of the said feature extraction and classification components while introducing a compiler that maps any arbitrary NN and/or classifier to the aforementioned hardware. The proposed hybrid machine learning model has the same level of accuracy (i.e. $\pm$1%) as NNs while achieving at least 10% improvement in accuracy compared to HD learning models. Additionally, the end-to-end hardware realization of the hybrid model improves power efficiency by 1.60x compared to state-of-the-art, high-performance HD learning implementations while improving latency by 2.13x. These results have profound implications for the application of such synergic models in challenging cognitive tasks.