 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrain Tumor Detection using Convolutional Neural Networks with Skip Connections
Jul 14, 2023In this paper, we present different architectures of Convolutional Neural Networks (CNN) to analyze and classify the brain tumors into benign and malignant types using the Magnetic Resonance Imaging (MRI) technique. Different CNN architecture optimization techniques such as widening and deepening of the network and adding skip connections are applied to improve the accuracy of the network. Results show that a subset of these techniques can judiciously be used to outperform a baseline CNN model used for the same purpose.
Sparse Periodic Systolic Dataflow for Lowering Latency and Power Dissipation of Convolutional Neural Network Accelerators
Jun 30, 2022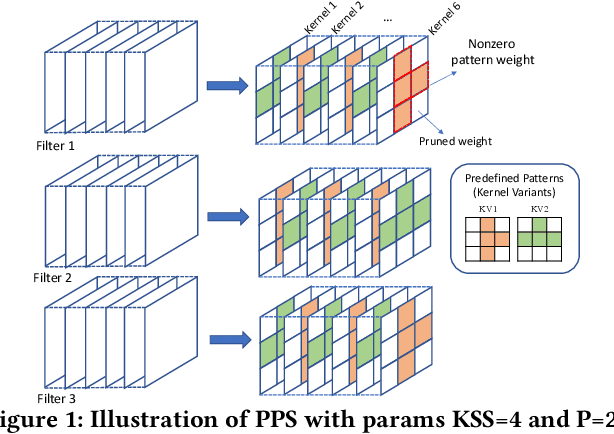
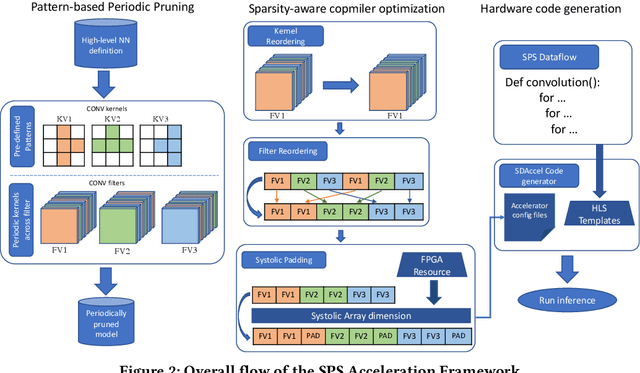
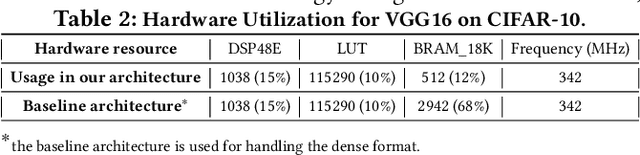
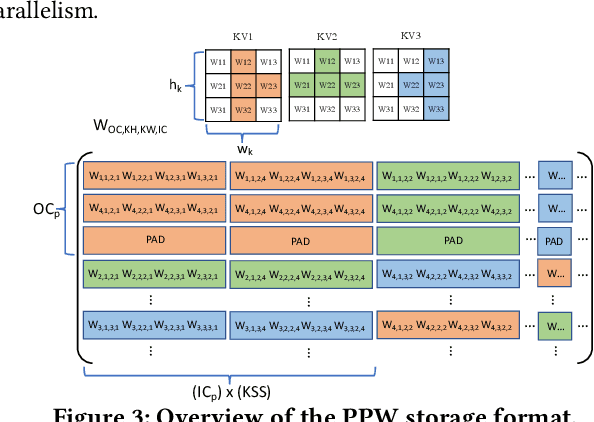
This paper introduces the sparse periodic systolic (SPS) dataflow, which advances the state-of-the-art hardware accelerator for supporting lightweight neural networks. Specifically, the SPS dataflow enables a novel hardware design approach unlocked by an emergent pruning scheme, periodic pattern-based sparsity (PPS). By exploiting the regularity of PPS, our sparsity-aware compiler optimally reorders the weights and uses a simple indexing unit in hardware to create matches between the weights and activations. Through the compiler-hardware codesign, SPS dataflow enjoys higher degrees of parallelism while being free of the high indexing overhead and without model accuracy loss. Evaluated on popular benchmarks such as VGG and ResNet, the SPS dataflow and accompanying neural network compiler outperform prior work in convolutional neural network (CNN) accelerator designs targeting FPGA devices. Against other sparsity-supporting weight storage formats, SPS results in 4.49x energy efficiency gain while lowering storage requirements by 3.67x for total weight storage (non-pruned weights plus indexing) and 22,044x for indexing memory.
NullaNet Tiny: Ultra-low-latency DNN Inference Through Fixed-function Combinational Logic
Apr 07, 2021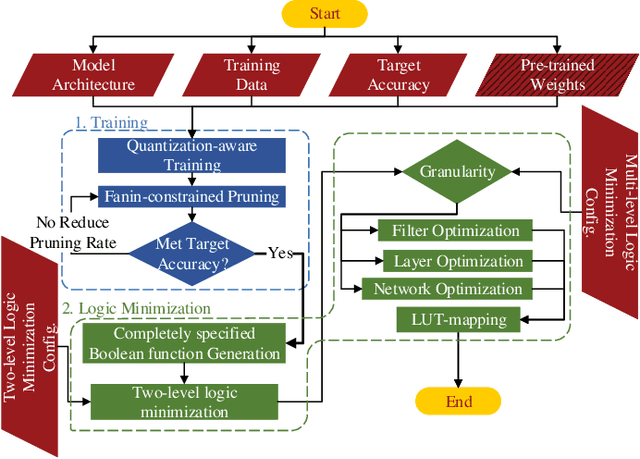
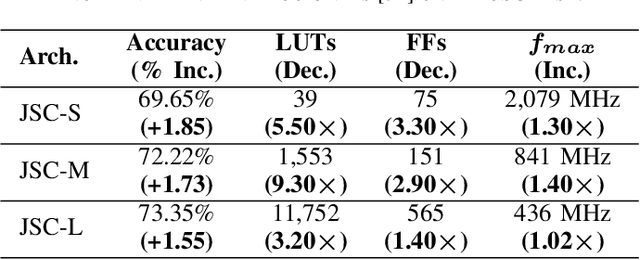
While there is a large body of research on efficient processing of deep neural networks (DNNs), ultra-low-latency realization of these models for applications with stringent, sub-microsecond latency requirements continues to be an unresolved, challenging problem. Field-programmable gate array (FPGA)-based DNN accelerators are gaining traction as a serious contender to replace graphics processing unit/central processing unit-based platforms considering their performance, flexibility, and energy efficiency. This paper presents NullaNet Tiny, an across-the-stack design and optimization framework for constructing resource and energy-efficient, ultra-low-latency FPGA-based neural network accelerators. The key idea is to replace expensive operations required to compute various filter/neuron functions in a DNN with Boolean logic expressions that are mapped to the native look-up tables (LUTs) of the FPGA device (examples of such operations are multiply-and-accumulate and batch normalization). At about the same level of classification accuracy, compared to Xilinx's LogicNets, our design achieves 2.36$\times$ lower latency and 24.42$\times$ lower LUT utilization.
SynergicLearning: Neural Network-Based Feature Extraction for Highly-Accurate Hyperdimensional Learning
Aug 04, 2020
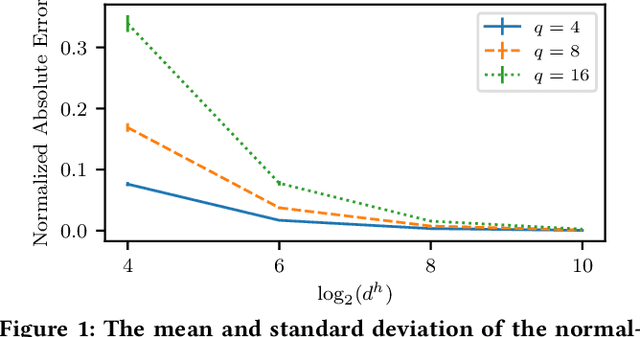
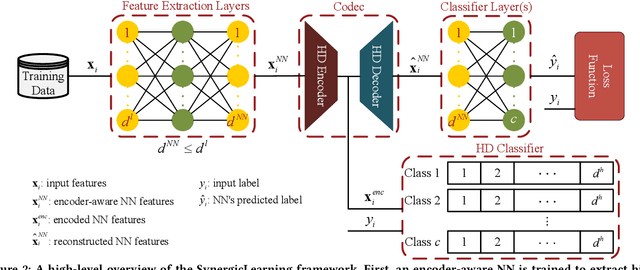

Machine learning models differ in terms of accuracy, computational/memory complexity, training time, and adaptability among other characteristics. For example, neural networks (NNs) are well-known for their high accuracy due to the quality of their automatic feature extraction while brain-inspired hyperdimensional (HD) learning models are famous for their quick training, computational efficiency, and adaptability. This work presents a hybrid, synergic machine learning model that excels at all the said characteristics and is suitable for incremental, on-line learning on a chip. The proposed model comprises an NN and a classifier. The NN acts as a feature extractor and is specifically trained to work well with the classifier that employs the HD computing framework. This work also presents a parameterized hardware implementation of the said feature extraction and classification components while introducing a compiler that maps any arbitrary NN and/or classifier to the aforementioned hardware. The proposed hybrid machine learning model has the same level of accuracy (i.e. $\pm$1%) as NNs while achieving at least 10% improvement in accuracy compared to HD learning models. Additionally, the end-to-end hardware realization of the hybrid model improves power efficiency by 1.60x compared to state-of-the-art, high-performance HD learning implementations while improving latency by 2.13x. These results have profound implications for the application of such synergic models in challenging cognitive tasks.
Energy-aware Scheduling of Jobs in Heterogeneous Cluster Systems Using Deep Reinforcement Learning
Dec 11, 2019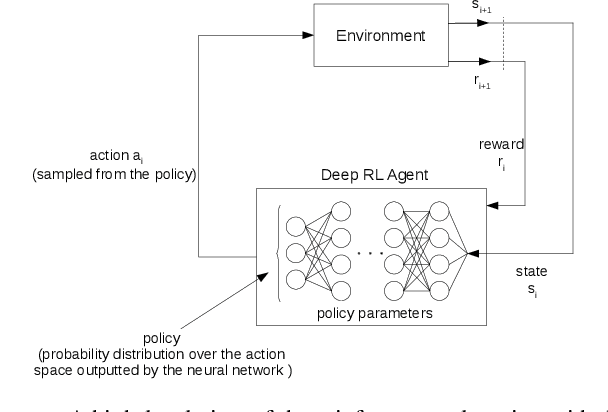
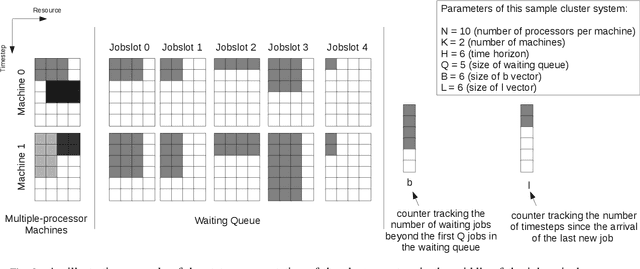
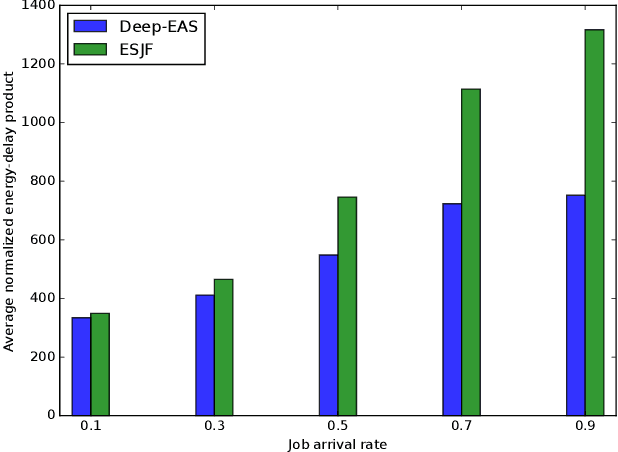
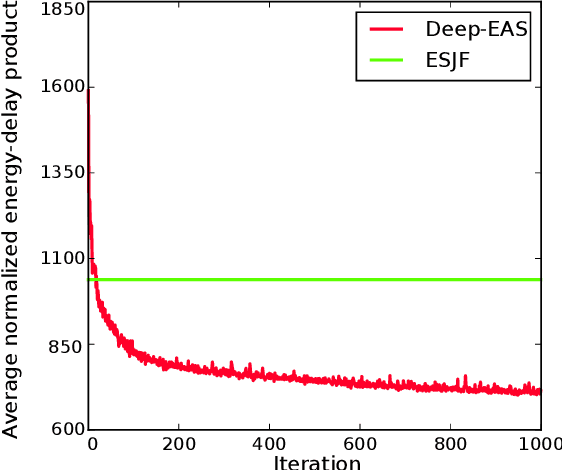
Energy consumption is one of the most critical concerns in designing computing devices, ranging from portable embedded systems to computer cluster systems. Furthermore, in the past decade, cluster systems have increasingly risen as popular platforms to run computing-intensive real-time applications in which the performance is of great importance. However, due to different characteristics of real-time workloads, developing general job scheduling solutions that efficiently address both energy consumption and performance in real-time cluster systems is a challenging problem. In this paper, inspired by recent advances in applying deep reinforcement learning for resource management problems, we present the Deep-EAS scheduler that learns efficient energy-aware scheduling strategies for workloads with different characteristics without initially knowing anything about the scheduling task at hand. Results show that Deep-EAS converges quickly, and performs better compared to standard manually-tuned heuristics, especially in heavy load conditions.
BottleNet: A Deep Learning Architecture for Intelligent Mobile Cloud Computing Services
Feb 04, 2019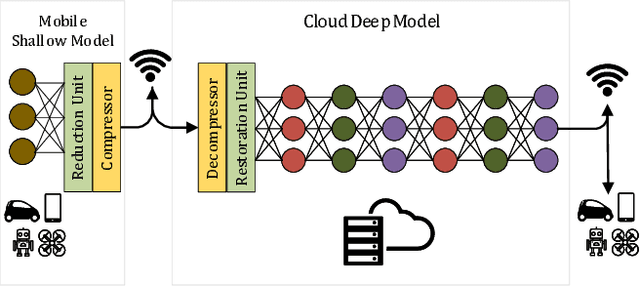

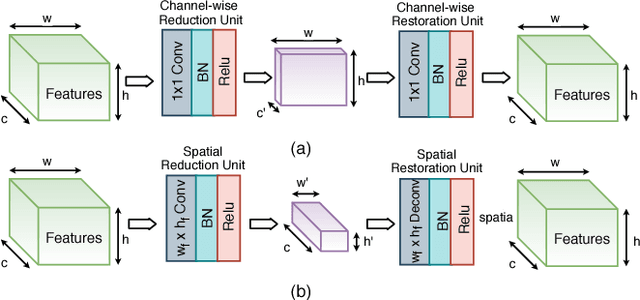

Recent studies have shown the latency and energy consumption of deep neural networks can be significantly improved by splitting the network between the mobile device and cloud. This paper introduces a new deep learning architecture, called BottleNet, for reducing the feature size needed to be sent to the cloud. Furthermore, we propose a training method for compensating for the potential accuracy loss due to the lossy compression of features before transmitting them to the cloud. BottleNet achieves on average 30x improvement in end-to-end latency and 40x improvement in mobile energy consumption compared to the cloud-only approach with negligible accuracy loss.