 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Compilation and Mapping of Fixed Function Combinational Logic onto Digital Signal Processors Targeting Neural Network Inference and Utilizing High-level Synthesis
Jul 30, 2022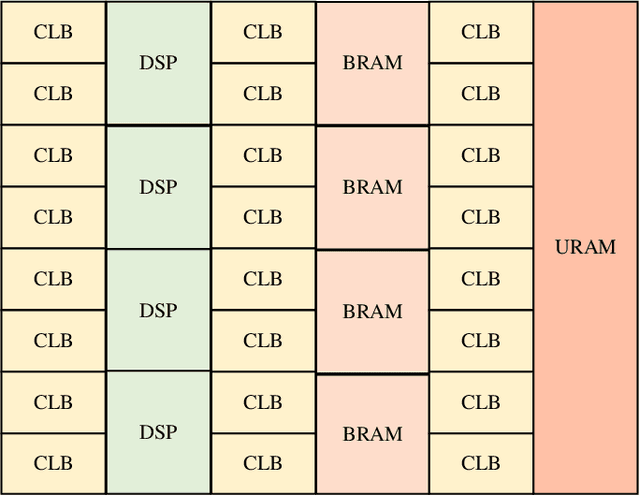
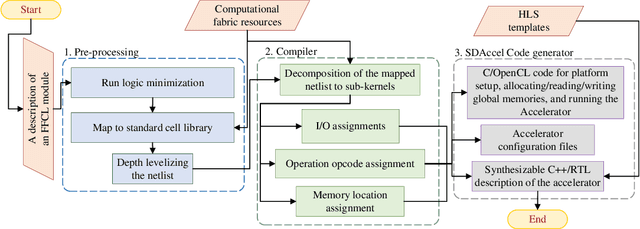
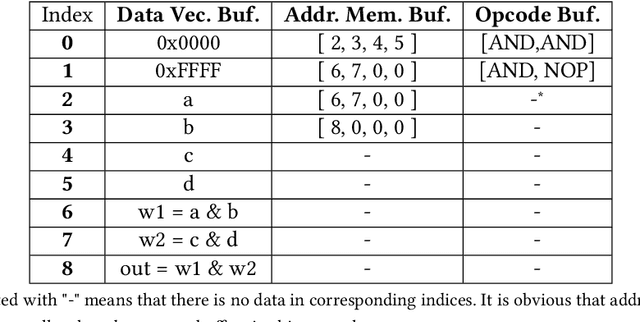
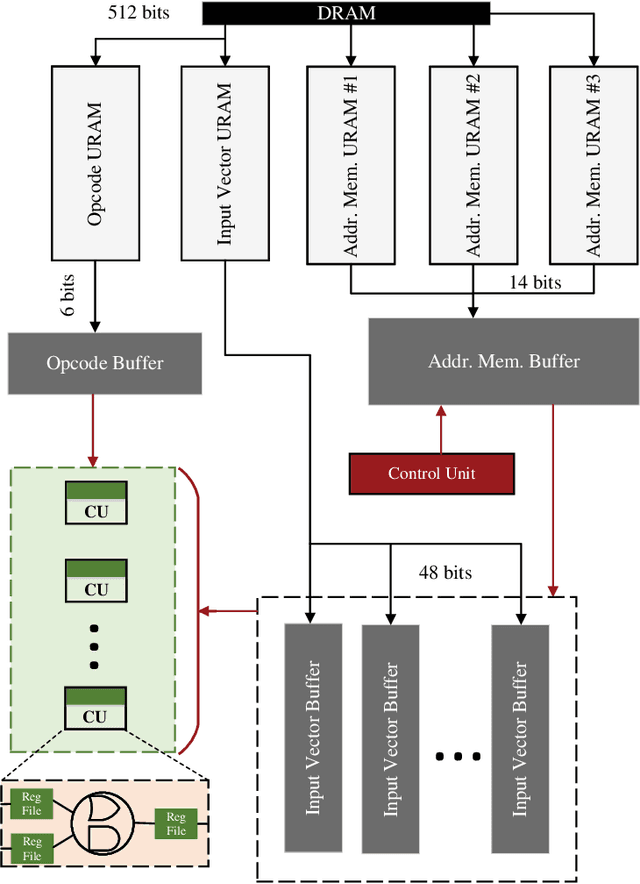
Recent efforts for improving the performance of neural network (NN) accelerators that meet today's application requirements have given rise to a new trend of logic-based NN inference relying on fixed function combinational logic. Mapping such large Boolean functions with many input variables and product terms to digital signal processors (DSPs) on Field-programmable gate arrays (FPGAs) needs a novel framework considering the structure and the reconfigurability of DSP blocks during this process. The proposed methodology in this paper maps the fixed function combinational logic blocks to a set of Boolean functions where Boolean operations corresponding to each function are mapped to DSP devices rather than look-up tables (LUTs) on the FPGAs to take advantage of the high performance, low latency, and parallelism of DSP blocks. % This paper also presents an innovative design and optimization methodology for compilation and mapping of NNs, utilizing fixed function combinational logic to DSPs on FPGAs employing high-level synthesis flow. % Our experimental evaluations across several \REVone{datasets} and selected NNs demonstrate the comparable performance of our framework in terms of the inference latency and output accuracy compared to prior art FPGA-based NN accelerators employing DSPs.
NullaNet Tiny: Ultra-low-latency DNN Inference Through Fixed-function Combinational Logic
Apr 07, 2021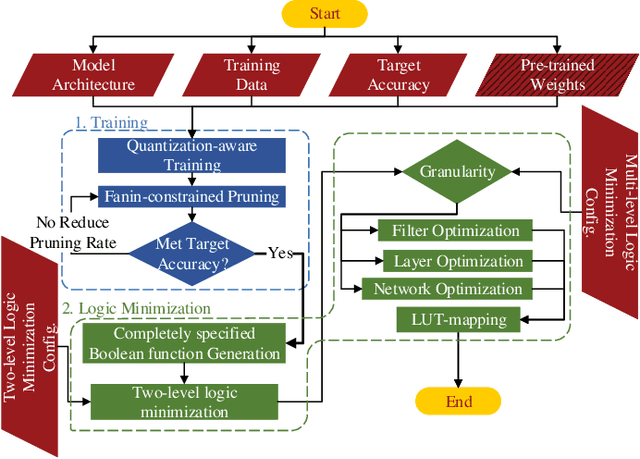
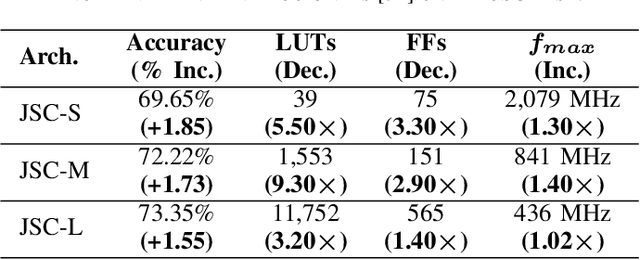
While there is a large body of research on efficient processing of deep neural networks (DNNs), ultra-low-latency realization of these models for applications with stringent, sub-microsecond latency requirements continues to be an unresolved, challenging problem. Field-programmable gate array (FPGA)-based DNN accelerators are gaining traction as a serious contender to replace graphics processing unit/central processing unit-based platforms considering their performance, flexibility, and energy efficiency. This paper presents NullaNet Tiny, an across-the-stack design and optimization framework for constructing resource and energy-efficient, ultra-low-latency FPGA-based neural network accelerators. The key idea is to replace expensive operations required to compute various filter/neuron functions in a DNN with Boolean logic expressions that are mapped to the native look-up tables (LUTs) of the FPGA device (examples of such operations are multiply-and-accumulate and batch normalization). At about the same level of classification accuracy, compared to Xilinx's LogicNets, our design achieves 2.36$\times$ lower latency and 24.42$\times$ lower LUT utilization.