 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOT: Self-Supervised Contrastive Pretraining For Zero-Shot Compositional Retrieval
Jan 12, 2025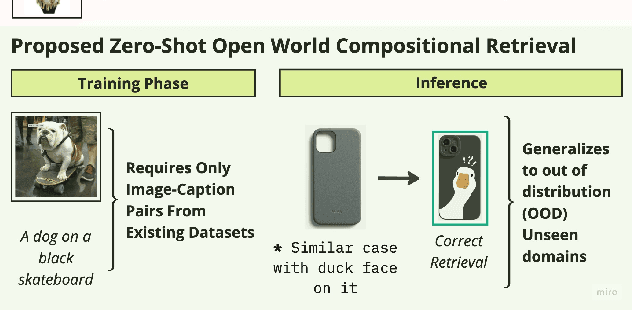
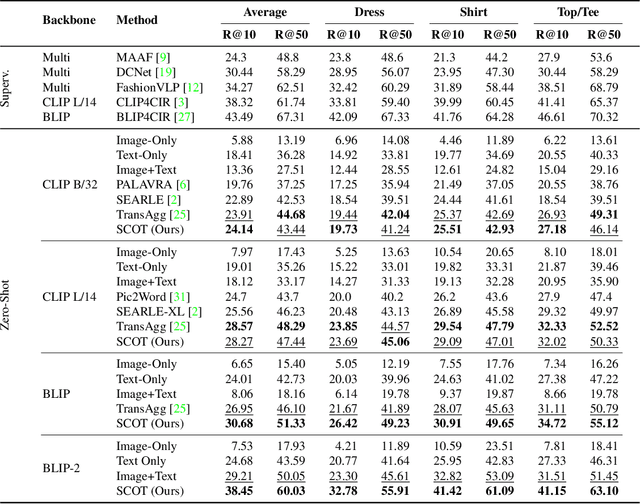
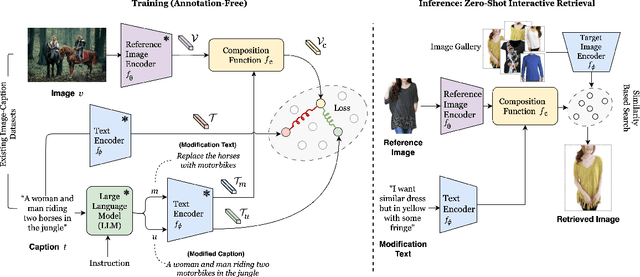
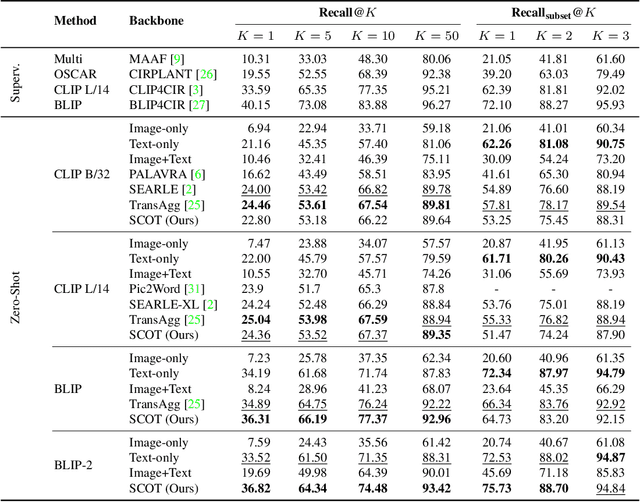
Compositional image retrieval (CIR) is a multimodal learning task where a model combines a query image with a user-provided text modification to retrieve a target image. CIR finds applications in a variety of domains including product retrieval (e-commerce) and web search. Existing methods primarily focus on fully-supervised learning, wherein models are trained on datasets of labeled triplets such as FashionIQ and CIRR. This poses two significant challenges: (i) curating such triplet datasets is labor intensive; and (ii) models lack generalization to unseen objects and domains. In this work, we propose SCOT (Self-supervised COmpositional Training), a novel zero-shot compositional pretraining strategy that combines existing large image-text pair datasets with the generative capabilities of large language models to contrastively train an embedding composition network. Specifically, we show that the text embedding from a large-scale contrastively-pretrained vision-language model can be utilized as proxy target supervision during compositional pretraining, replacing the target image embedding. In zero-shot settings, this strategy surpasses SOTA zero-shot compositional retrieval methods as well as many fully-supervised methods on standard benchmarks such as FashionIQ and CIRR.
Salient Object-Aware Background Generation using Text-Guided Diffusion Models
Apr 15, 2024Generating background scenes for salient objects plays a crucial role across various domains including creative design and e-commerce, as it enhances the presentation and context of subjects by integrating them into tailored environments. Background generation can be framed as a task of text-conditioned outpainting, where the goal is to extend image content beyond a salient object's boundaries on a blank background. Although popular diffusion models for text-guided inpainting can also be used for outpainting by mask inversion, they are trained to fill in missing parts of an image rather than to place an object into a scene. Consequently, when used for background creation, inpainting models frequently extend the salient object's boundaries and thereby change the object's identity, which is a phenomenon we call "object expansion." This paper introduces a model for adapting inpainting diffusion models to the salient object outpainting task using Stable Diffusion and ControlNet architectures. We present a series of qualitative and quantitative results across models and datasets, including a newly proposed metric to measure object expansion that does not require any human labeling. Compared to Stable Diffusion 2.0 Inpainting, our proposed approach reduces object expansion by 3.6x on average with no degradation in standard visual metrics across multiple datasets.
Efficient Training of Deep Convolutional Neural Networks by Augmentation in Embedding Space
Feb 12, 2020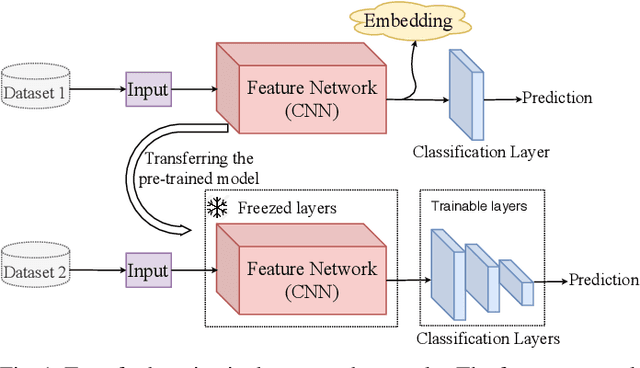
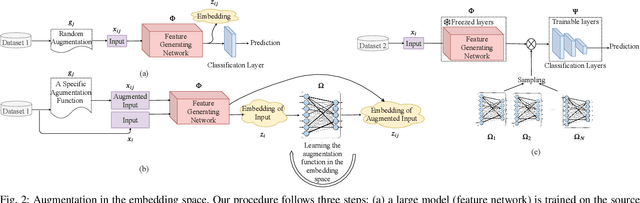
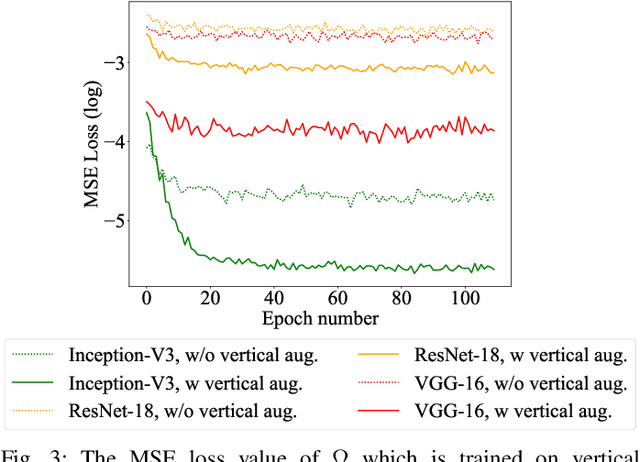
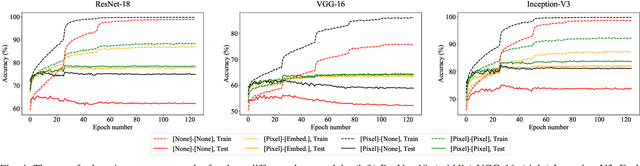
Recent advances in the field of artificial intelligence have been made possible by deep neural networks. In applications where data are scarce, transfer learning and data augmentation techniques are commonly used to improve the generalization of deep learning models. However, fine-tuning a transfer model with data augmentation in the raw input space has a high computational cost to run the full network for every augmented input. This is particularly critical when large models are implemented on embedded devices with limited computational and energy resources. In this work, we propose a method that replaces the augmentation in the raw input space with an approximate one that acts purely in the embedding space. Our experimental results show that the proposed method drastically reduces the computation, while the accuracy of models is negligibly compromised.
Run-time Deep Model Multiplexing
Jan 14, 2020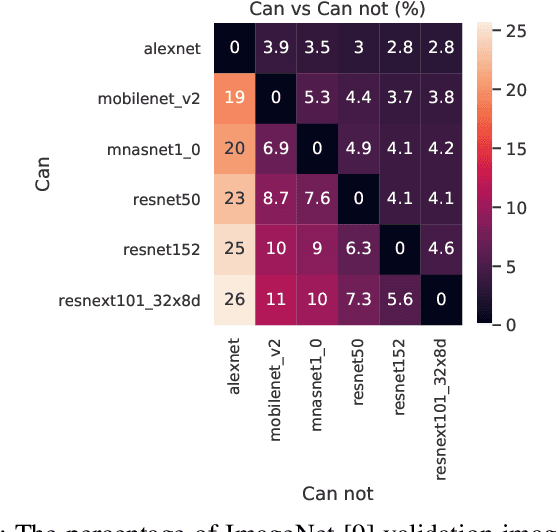
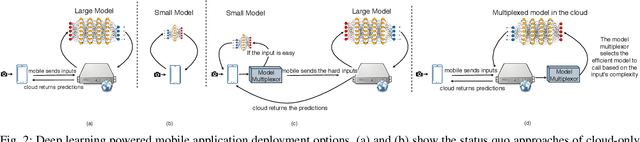


We propose a framework to design a light-weight neural multiplexer that given input and resource budgets, decides upon the appropriate model to be called for the inference. Mobile devices can use this framework to offload the hard inputs to the cloud while inferring the easy ones locally. Besides, in the large scale cloud-based intelligent applications, instead of replicating the most-accurate model, a range of small and large models can be multiplexed from depending on the input's complexity and resource budgets. Our experimental results demonstrate the effectiveness of our framework benefiting both mobile users and cloud providers.
Video Person Re-ID: Fantastic Techniques and Where to Find Them
Nov 21, 2019



The ability to identify the same person from multiple camera views without the explicit use of facial recognition is receiving commercial and academic interest. The current status-quo solutions are based on attention neural models. In this paper, we propose Attention and CL loss, which is a hybrid of center and Online Soft Mining (OSM) loss added to the attention loss on top of a temporal attention-based neural network. The proposed loss function applied with bag-of-tricks for training surpasses the state of the art on the common person Re-ID datasets, MARS and PRID 2011. Our source code is publicly available on github.
Coarse2Fine: A Two-stage Training Method for Fine-grained Visual Classification
Sep 06, 2019

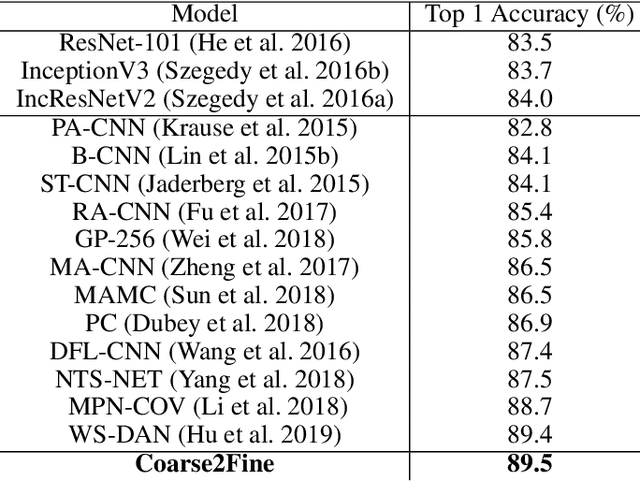
Small inter-class and large intra-class variations are the main challenges in fine-grained visual classification. Objects from different classes share visually similar structures and objects in the same class can have different poses and viewpoints. Therefore, the proper extraction of discriminative local features (e.g. bird's beak or car's headlight) is crucial. Most of the recent successes on this problem are based upon the attention models which can localize and attend the local discriminative objects parts. In this work, we propose a training method for visual attention networks, Coarse2Fine, which creates a differentiable path from the input space to the attended feature maps. Coarse2Fine learns an inverse mapping function from the attended feature maps to the informative regions in the raw image, which will guide the attention maps to better attend the fine-grained features. We show Coarse2Fine and orthogonal initialization of the attention weights can surpass the state-of-the-art accuracies on common fine-grained classification tasks.
BottleNet: A Deep Learning Architecture for Intelligent Mobile Cloud Computing Services
Feb 04, 2019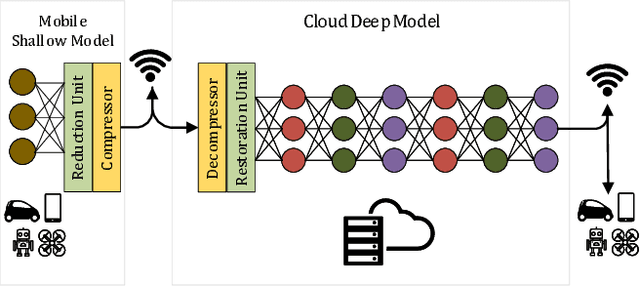

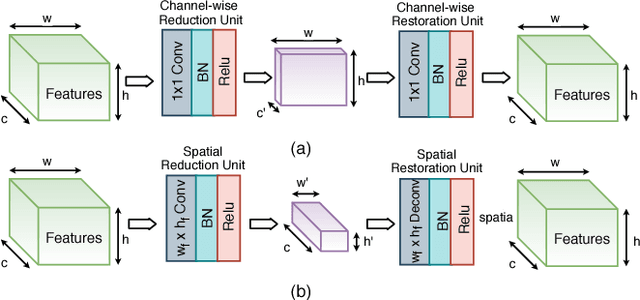

Recent studies have shown the latency and energy consumption of deep neural networks can be significantly improved by splitting the network between the mobile device and cloud. This paper introduces a new deep learning architecture, called BottleNet, for reducing the feature size needed to be sent to the cloud. Furthermore, we propose a training method for compensating for the potential accuracy loss due to the lossy compression of features before transmitting them to the cloud. BottleNet achieves on average 30x improvement in end-to-end latency and 40x improvement in mobile energy consumption compared to the cloud-only approach with negligible accuracy loss.
Gradient Agreement as an Optimization Objective for Meta-Learning
Oct 18, 2018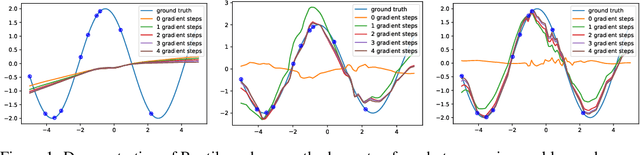
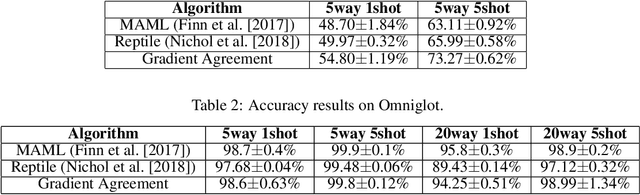
This paper presents a novel optimization method for maximizing generalization over tasks in meta-learning. The goal of meta-learning is to learn a model for an agent adapting rapidly when presented with previously unseen tasks. Tasks are sampled from a specific distribution which is assumed to be similar for both seen and unseen tasks. We focus on a family of meta-learning methods learning initial parameters of a base model which can be fine-tuned quickly on a new task, by few gradient steps (MAML). Our approach is based on pushing the parameters of the model to a direction in which tasks have more agreement upon. If the gradients of a task agree with the parameters update vector, then their inner product will be a large positive value. As a result, given a batch of tasks to be optimized for, we associate a positive (negative) weight to the loss function of a task, if the inner product between its gradients and the average of the gradients of all tasks in the batch is a positive (negative) value. Therefore, the degree of the contribution of a task to the parameter updates is controlled by introducing a set of weights on the loss function of the tasks. Our method can be easily integrated with the current meta-learning algorithms for neural networks. Our experiments demonstrate that it yields models with better generalization compared to MAML and Reptile.
A Meta-Learning Approach for Custom Model Training
Sep 21, 2018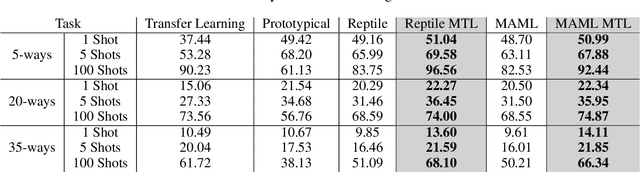

Transfer-learning and meta-learning are two effective methods to apply knowledge learned from large data sources to new tasks. In few-class, few-shot target task settings (i.e. when there are only a few classes and training examples available in the target task), meta-learning approaches that optimize for future task learning have outperformed the typical transfer approach of initializing model weights from a pre-trained starting point. But as we experimentally show, meta-learning algorithms that work well in the few-class setting do not generalize well in many-shot and many-class cases. In this paper, we propose a joint training approach that combines both transfer-learning and meta-learning. Benefiting from the advantages of each, our method obtains improved generalization performance on unseen target tasks in both few- and many-class and few- and many-shot scenarios.
JointDNN: An Efficient Training and Inference Engine for Intelligent Mobile Cloud Computing Services
Jan 25, 2018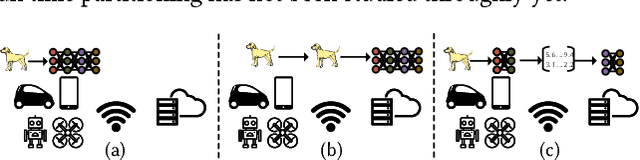
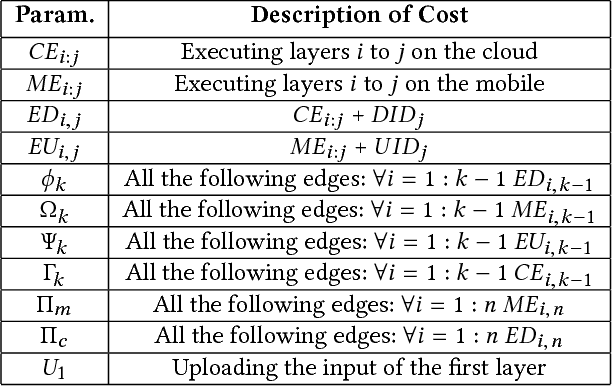
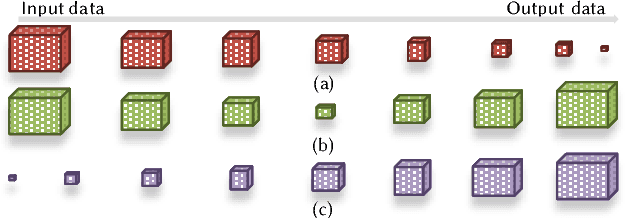

Deep neural networks are among the most influential architectures of deep learning algorithms, being deployed in many mobile intelligent applications. End-side services, such as intelligent personal assistants (IPAs), autonomous cars, and smart home services often employ either simple local models or complex remote models on the cloud. Mobile-only and cloud-only computations are currently the status quo approaches. In this paper, we propose an efficient, adaptive, and practical engine, JointDNN, for collaborative computation between a mobile device and cloud for DNNs in both inference and training phase. JointDNN not only provides an energy and performance efficient method of querying DNNs for the mobile side, but also benefits the cloud server by reducing the amount of its workload and communications compared to the cloud-only approach. Given the DNN architecture, we investigate the efficiency of processing some layers on the mobile device and some layers on the cloud server. We provide optimization formulations at layer granularity for forward and backward propagation in DNNs, which can adapt to mobile battery limitations and cloud server load constraints and quality of service. JointDNN achieves up to 18X and 32X reductions on the latency and mobile energy consumption of querying DNNs, respectively.