 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTARS: Segment-level Token Alignment with Rejection Sampling in Large Language Models
Nov 05, 2025Aligning large language models with human values is crucial for their safe deployment; however, existing methods, such as fine-tuning, are computationally expensive and suboptimal. In contrast, inference-time approaches like Best-of-N sampling require practically infeasible computation to achieve optimal alignment. We propose STARS: Segment-level Token Alignment with Rejection Sampling, a decoding-time algorithm that steers model generation by iteratively sampling, scoring, and rejecting/accepting short, fixed-size token segments. This allows for early correction of the generation path, significantly improving computational efficiency and boosting alignment quality. Across a suite of six LLMs, we show that STARS outperforms Supervised Fine-Tuning (SFT) by up to 14.9 percentage points and Direct Preference Optimization (DPO) by up to 4.3 percentage points on win-rates, while remaining highly competitive with strong Best-of-N baselines. Our work establishes granular, reward-guided sampling as a generalizable, robust, and efficient alternative to traditional fine-tuning and full-sequence ranking methods for aligning LLMs.
Distributionally robust self-supervised learning for tabular data
Oct 11, 2024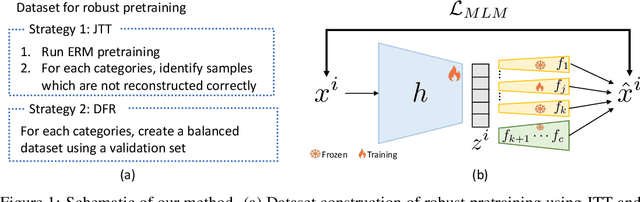
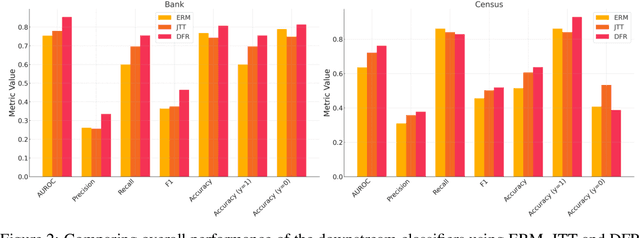
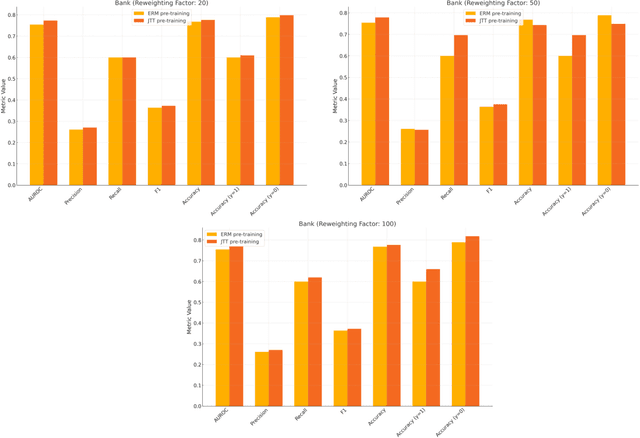
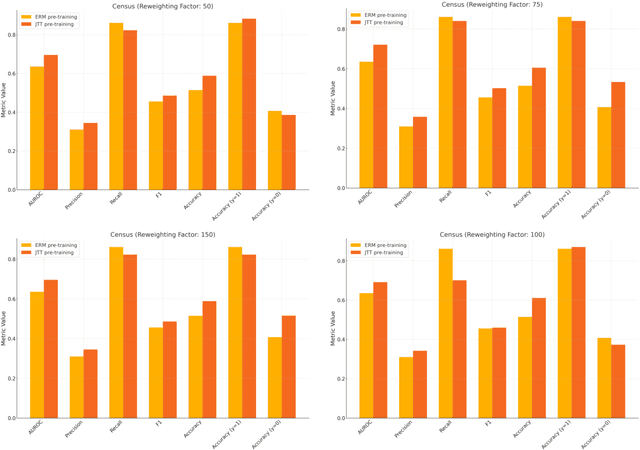
Machine learning (ML) models trained using Empirical Risk Minimization (ERM) often exhibit systematic errors on specific subpopulations of tabular data, known as error slices. Learning robust representation in presence of error slices is challenging, especially in self-supervised settings during the feature reconstruction phase, due to high cardinality features and the complexity of constructing error sets. Traditional robust representation learning methods are largely focused on improving worst group performance in supervised setting in computer vision, leaving a gap in approaches tailored for tabular data. We address this gap by developing a framework to learn robust representation in tabular data during self-supervised pre-training. Our approach utilizes an encoder-decoder model trained with Masked Language Modeling (MLM) loss to learn robust latent representations. This paper applies the Just Train Twice (JTT) and Deep Feature Reweighting (DFR) methods during the pre-training phase for tabular data. These methods fine-tune the ERM pre-trained model by up-weighting error-prone samples or creating balanced datasets for specific categorical features. This results in specialized models for each feature, which are then used in an ensemble approach to enhance downstream classification performance. This methodology improves robustness across slices, thus enhancing overall generalization performance. Extensive experiments across various datasets demonstrate the efficacy of our approach.
HLogformer: A Hierarchical Transformer for Representing Log Data
Aug 29, 2024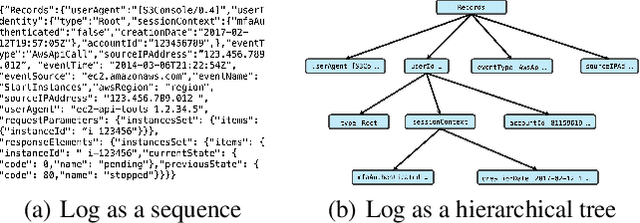
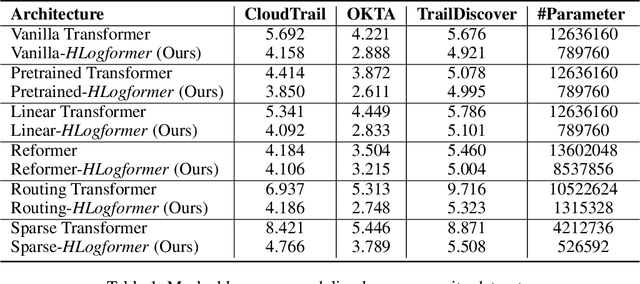
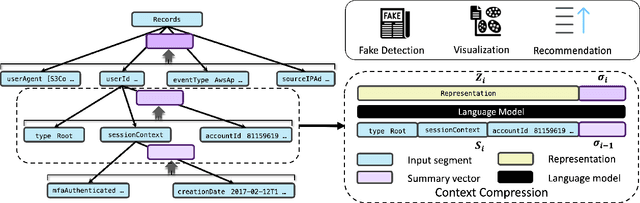
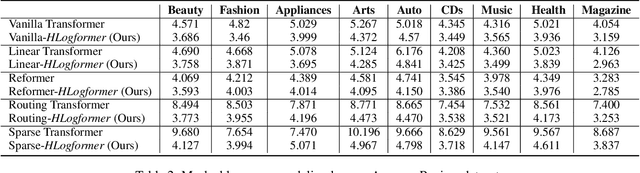
Transformers have gained widespread acclaim for their versatility in handling diverse data structures, yet their application to log data remains underexplored. Log data, characterized by its hierarchical, dictionary-like structure, poses unique challenges when processed using conventional transformer models. Traditional methods often rely on manually crafted templates for parsing logs, a process that is labor-intensive and lacks generalizability. Additionally, the linear treatment of log sequences by standard transformers neglects the rich, nested relationships within log entries, leading to suboptimal representations and excessive memory usage. To address these issues, we introduce HLogformer, a novel hierarchical transformer framework specifically designed for log data. HLogformer leverages the hierarchical structure of log entries to significantly reduce memory costs and enhance representation learning. Unlike traditional models that treat log data as flat sequences, our framework processes log entries in a manner that respects their inherent hierarchical organization. This approach ensures comprehensive encoding of both fine-grained details and broader contextual relationships. Our contributions are threefold: First, HLogformer is the first framework to design a dynamic hierarchical transformer tailored for dictionary-like log data. Second, it dramatically reduces memory costs associated with processing extensive log sequences. Third, comprehensive experiments demonstrate that HLogformer more effectively encodes hierarchical contextual information, proving to be highly effective for downstream tasks such as synthetic anomaly detection and product recommendation.
Salient Object-Aware Background Generation using Text-Guided Diffusion Models
Apr 15, 2024Generating background scenes for salient objects plays a crucial role across various domains including creative design and e-commerce, as it enhances the presentation and context of subjects by integrating them into tailored environments. Background generation can be framed as a task of text-conditioned outpainting, where the goal is to extend image content beyond a salient object's boundaries on a blank background. Although popular diffusion models for text-guided inpainting can also be used for outpainting by mask inversion, they are trained to fill in missing parts of an image rather than to place an object into a scene. Consequently, when used for background creation, inpainting models frequently extend the salient object's boundaries and thereby change the object's identity, which is a phenomenon we call "object expansion." This paper introduces a model for adapting inpainting diffusion models to the salient object outpainting task using Stable Diffusion and ControlNet architectures. We present a series of qualitative and quantitative results across models and datasets, including a newly proposed metric to measure object expansion that does not require any human labeling. Compared to Stable Diffusion 2.0 Inpainting, our proposed approach reduces object expansion by 3.6x on average with no degradation in standard visual metrics across multiple datasets.
HairFastGAN: Realistic and Robust Hair Transfer with a Fast Encoder-Based Approach
Apr 01, 2024Our paper addresses the complex task of transferring a hairstyle from a reference image to an input photo for virtual hair try-on. This task is challenging due to the need to adapt to various photo poses, the sensitivity of hairstyles, and the lack of objective metrics. The current state of the art hairstyle transfer methods use an optimization process for different parts of the approach, making them inexcusably slow. At the same time, faster encoder-based models are of very low quality because they either operate in StyleGAN's W+ space or use other low-dimensional image generators. Additionally, both approaches have a problem with hairstyle transfer when the source pose is very different from the target pose, because they either don't consider the pose at all or deal with it inefficiently. In our paper, we present the HairFast model, which uniquely solves these problems and achieves high resolution, near real-time performance, and superior reconstruction compared to optimization problem-based methods. Our solution includes a new architecture operating in the FS latent space of StyleGAN, an enhanced inpainting approach, and improved encoders for better alignment, color transfer, and a new encoder for post-processing. The effectiveness of our approach is demonstrated on realism metrics after random hairstyle transfer and reconstruction when the original hairstyle is transferred. In the most difficult scenario of transferring both shape and color of a hairstyle from different images, our method performs in less than a second on the Nvidia V100. Our code is available at https://github.com/AIRI-Institute/HairFastGAN.
Staging E-Commerce Products for Online Advertising using Retrieval Assisted Image Generation
Jul 28, 2023

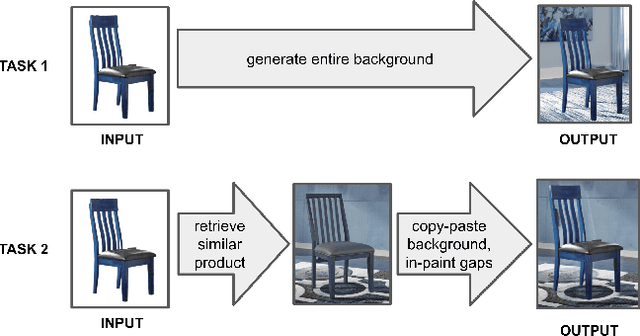

Online ads showing e-commerce products typically rely on the product images in a catalog sent to the advertising platform by an e-commerce platform. In the broader ads industry such ads are called dynamic product ads (DPA). It is common for DPA catalogs to be in the scale of millions (corresponding to the scale of products which can be bought from the e-commerce platform). However, not all product images in the catalog may be appealing when directly re-purposed as an ad image, and this may lead to lower click-through rates (CTRs). In particular, products just placed against a solid background may not be as enticing and realistic as a product staged in a natural environment. To address such shortcomings of DPA images at scale, we propose a generative adversarial network (GAN) based approach to generate staged backgrounds for un-staged product images. Generating the entire staged background is a challenging task susceptible to hallucinations. To get around this, we introduce a simpler approach called copy-paste staging using retrieval assisted GANs. In copy paste staging, we first retrieve (from the catalog) staged products similar to the un-staged input product, and then copy-paste the background of the retrieved product in the input image. A GAN based in-painting model is used to fill the holes left after this copy-paste operation. We show the efficacy of our copy-paste staging method via offline metrics, and human evaluation. In addition, we show how our staging approach can enable animations of moving products leading to a video ad from a product image.
Revising deep learning methods in parking lot occupancy detection
Jun 08, 2023Parking guidance systems have recently become a popular trend as a part of the smart cities' paradigm of development. The crucial part of such systems is the algorithm allowing drivers to search for available parking lots across regions of interest. The classic approach to this task is based on the application of neural network classifiers to camera records. However, existing systems demonstrate a lack of generalization ability and appropriate testing regarding specific visual conditions. In this study, we extensively evaluate state-of-the-art parking lot occupancy detection algorithms, compare their prediction quality with the recently emerged vision transformers, and propose a new pipeline based on EfficientNet architecture. Performed computational experiments have demonstrated the performance increase in the case of our model, which was evaluated on 5 different datasets.
VisualTextRank: Unsupervised Graph-based Content Extraction for Automating Ad Text to Image Search
Aug 05, 2021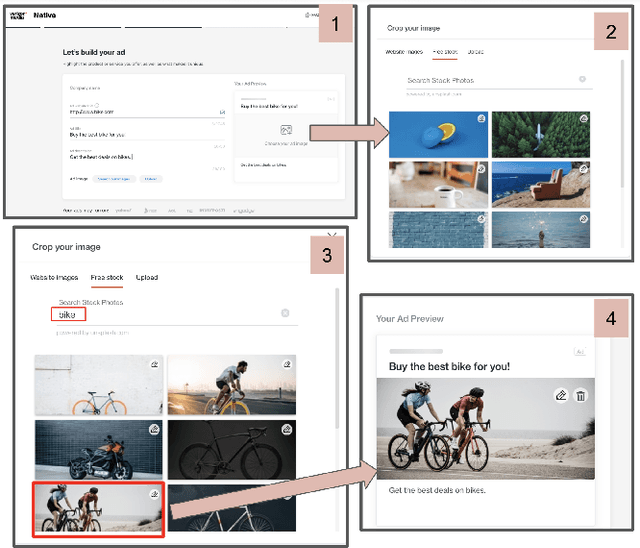
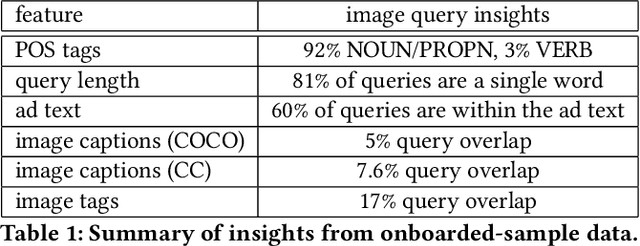
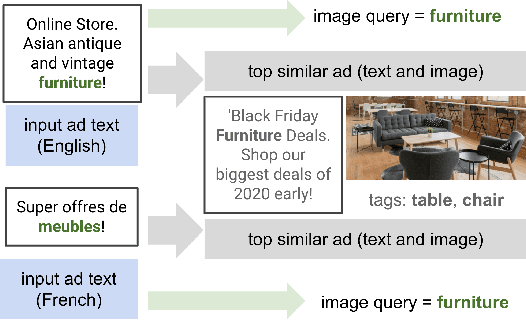
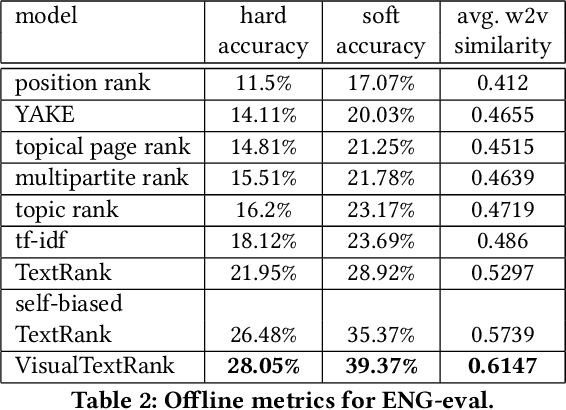
Numerous online stock image libraries offer high quality yet copyright free images for use in marketing campaigns. To assist advertisers in navigating such third party libraries, we study the problem of automatically fetching relevant ad images given the ad text (via a short textual query for images). Motivated by our observations in logged data on ad image search queries (given ad text), we formulate a keyword extraction problem, where a keyword extracted from the ad text (or its augmented version) serves as the ad image query. In this context, we propose VisualTextRank: an unsupervised method to (i) augment input ad text using semantically similar ads, and (ii) extract the image query from the augmented ad text. VisualTextRank builds on prior work on graph based context extraction (biased TextRank in particular) by leveraging both the text and image of similar ads for better keyword extraction, and using advertiser category specific biasing with sentence-BERT embeddings. Using data collected from the Verizon Media Native (Yahoo Gemini) ad platform's stock image search feature for onboarding advertisers, we demonstrate the superiority of VisualTextRank compared to competitive keyword extraction baselines (including an $11\%$ accuracy lift over biased TextRank). For the case when the stock image library is restricted to English queries, we show the effectiveness of VisualTextRank on multilingual ads (translated to English) while leveraging semantically similar English ads. Online tests with a simplified version of VisualTextRank led to a 28.7% increase in the usage of stock image search, and a 41.6% increase in the advertiser onboarding rate in the Verizon Media Native ad platform.
Probabilistic Label Trees for Extreme Multi-label Classification
Sep 23, 2020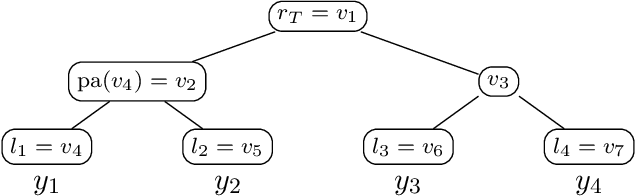

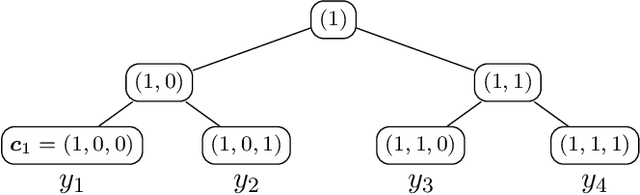
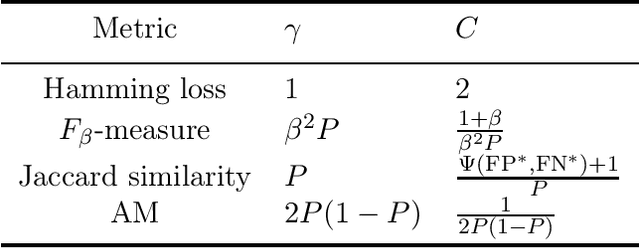
Extreme multi-label classification (XMLC) is a learning task of tagging instances with a small subset of relevant labels chosen from an extremely large pool of possible labels. Problems of this scale can be efficiently handled by organizing labels as a tree, like in hierarchical softmax used for multi-class problems. In this paper, we thoroughly investigate probabilistic label trees (PLTs) which can be treated as a generalization of hierarchical softmax for multi-label problems. We first introduce the PLT model and discuss training and inference procedures and their computational costs. Next, we prove the consistency of PLTs for a wide spectrum of performance metrics. To this end, we upperbound their regret by a function of surrogate-loss regrets of node classifiers. Furthermore, we consider a problem of training PLTs in a fully online setting, without any prior knowledge of training instances, their features, or labels. In this case, both node classifiers and the tree structure are trained online. We prove a specific equivalence between the fully online algorithm and an algorithm with a tree structure given in advance. Finally, we discuss several implementations of PLTs and introduce a new one, napkinXC, which we empirically evaluate and compare with state-of-the-art algorithms.
On the computational complexity of the probabilistic label tree algorithms
Jun 01, 2019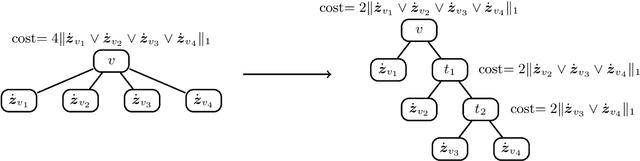
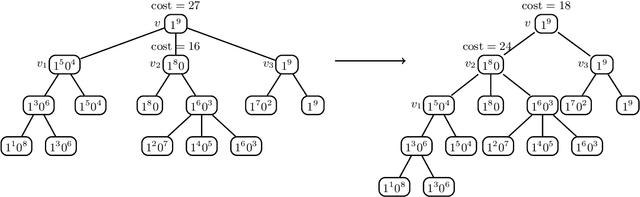


Label tree-based algorithms are widely used to tackle multi-class and multi-label problems with a large number of labels. We focus on a particular subclass of these algorithms that use probabilistic classifiers in the tree nodes. Examples of such algorithms are hierarchical softmax (HSM), designed for multi-class classification, and probabilistic label trees (PLTs) that generalize HSM to multi-label problems. If the tree structure is given, learning of PLT can be solved with provable regret guaranties [Wydmuch et.al. 2018]. However, to find a tree structure that results in a PLT with a low training and prediction computational costs as well as low statistical error seems to be a very challenging problem, not well-understood yet. In this paper, we address the problem of finding a tree structure that has low computational cost. First, we show that finding a tree with optimal training cost is NP-complete, nevertheless there are some tractable special cases with either perfect approximation or exact solution that can be obtained in linear time in terms of the number of labels $m$. For the general case, we obtain $O(\log m)$ approximation in linear time too. Moreover, we prove an upper bound on the expected prediction cost expressed in terms of the expected training cost. We also show that under additional assumptions the prediction cost of a PLT is $O(\log m)$.