 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiAD: Mirage Atom Diffusion for De Novo Crystal Generation
Nov 18, 2025



In recent years, diffusion-based models have demonstrated exceptional performance in searching for simultaneously stable, unique, and novel (S.U.N.) crystalline materials. However, most of these models don't have the ability to change the number of atoms in the crystal during the generation process, which limits the variability of model sampling trajectories. In this paper, we demonstrate the severity of this restriction and introduce a simple yet powerful technique, mirage infusion, which enables diffusion models to change the state of the atoms that make up the crystal from existent to non-existent (mirage) and vice versa. We show that this technique improves model quality by up to $\times2.5$ compared to the same model without this modification. The resulting model, Mirage Atom Diffusion (MiAD), is an equivariant joint diffusion model for de novo crystal generation that is capable of altering the number of atoms during the generation process. MiAD achieves an $8.2\%$ S.U.N. rate on the MP-20 dataset, which substantially exceeds existing state-of-the-art approaches. The source code can be found at \href{https://github.com/andrey-okhotin/miad.git}{\texttt{github.com/andrey-okhotin/miad}}.
Can Training Dynamics of Scale-Invariant Neural Networks Be Explained by the Thermodynamics of an Ideal Gas?
Nov 10, 2025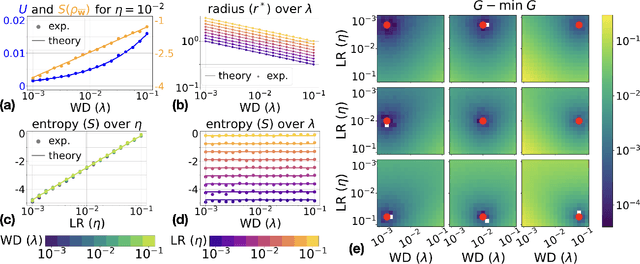

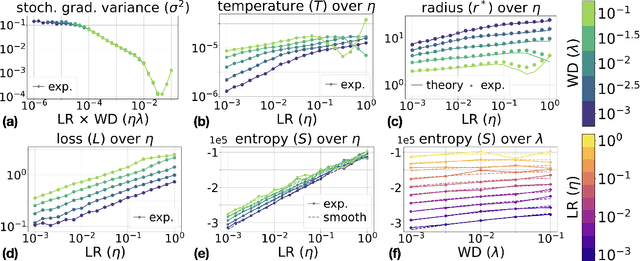

Understanding the training dynamics of deep neural networks remains a major open problem, with physics-inspired approaches offering promising insights. Building on this perspective, we develop a thermodynamic framework to describe the stationary distributions of stochastic gradient descent (SGD) with weight decay for scale-invariant neural networks, a setting that both reflects practical architectures with normalization layers and permits theoretical analysis. We establish analogies between training hyperparameters (e.g., learning rate, weight decay) and thermodynamic variables such as temperature, pressure, and volume. Starting with a simplified isotropic noise model, we uncover a close correspondence between SGD dynamics and ideal gas behavior, validated through theory and simulation. Extending to training of neural networks, we show that key predictions of the framework, including the behavior of stationary entropy, align closely with experimental observations. This framework provides a principled foundation for interpreting training dynamics and may guide future work on hyperparameter tuning and the design of learning rate schedulers.
SGD as Free Energy Minimization: A Thermodynamic View on Neural Network Training
May 29, 2025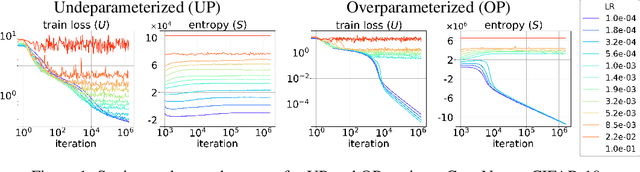

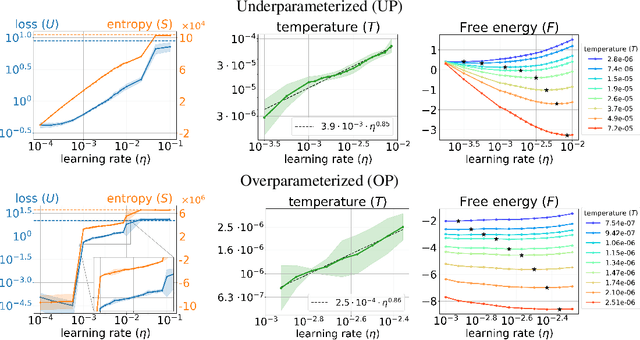
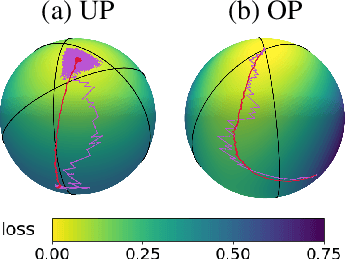
We present a thermodynamic interpretation of the stationary behavior of stochastic gradient descent (SGD) under fixed learning rates (LRs) in neural network training. We show that SGD implicitly minimizes a free energy function $F=U-TS$, balancing training loss $U$ and the entropy of the weights distribution $S$, with temperature $T$ determined by the LR. This perspective offers a new lens on why high LRs prevent training from converging to the loss minima and how different LRs lead to stabilization at different loss levels. We empirically validate the free energy framework on both underparameterized (UP) and overparameterized (OP) models. UP models consistently follow free energy minimization, with temperature increasing monotonically with LR, while for OP models, the temperature effectively drops to zero at low LRs, causing SGD to minimize the loss directly and converge to an optimum. We attribute this mismatch to differences in the signal-to-noise ratio of stochastic gradients near optima, supported by both a toy example and neural network experiments.
Smoothie: Smoothing Diffusion on Token Embeddings for Text Generation
May 24, 2025Diffusion models have achieved state-of-the-art performance in generating images, audio, and video, but their adaptation to text remains challenging due to its discrete nature. Prior approaches either apply Gaussian diffusion in continuous latent spaces, which inherits semantic structure but struggles with token decoding, or operate in categorical simplex space, which respect discreteness but disregard semantic relation between tokens. In this paper, we propose Smoothing Diffusion on Token Embeddings (Smoothie), a novel diffusion method that combines the strengths of both approaches by progressively smoothing token embeddings based on semantic similarity. This technique enables gradual information removal while maintaining a natural decoding process. Experimental results on several sequence-to-sequence generation tasks demonstrate that Smoothie outperforms existing diffusion-based models in generation quality. Furthermore, ablation studies show that our proposed diffusion space yields better performance than both the standard embedding space and the categorical simplex. Our code is available at https://github.com/ashaba1in/smoothie.
Streaming Generation of Co-Speech Gestures via Accelerated Rolling Diffusion
Mar 13, 2025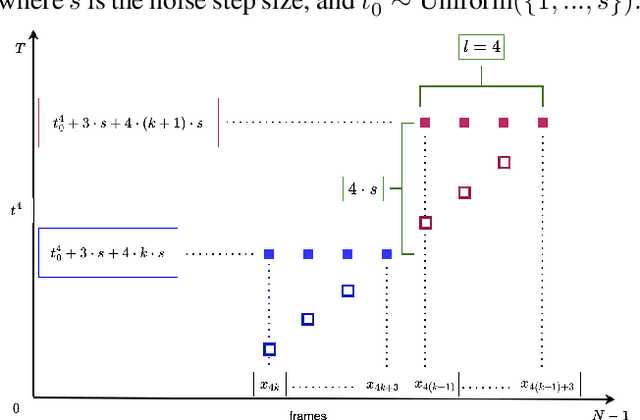


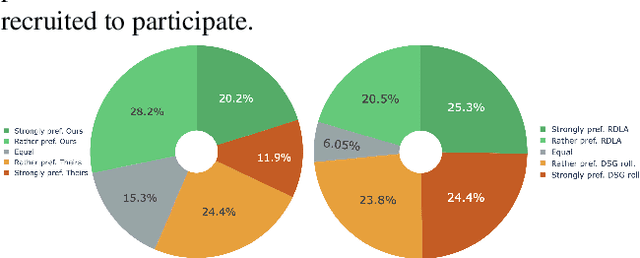
Generating co-speech gestures in real time requires both temporal coherence and efficient sampling. We introduce Accelerated Rolling Diffusion, a novel framework for streaming gesture generation that extends rolling diffusion models with structured progressive noise scheduling, enabling seamless long-sequence motion synthesis while preserving realism and diversity. We further propose Rolling Diffusion Ladder Acceleration (RDLA), a new approach that restructures the noise schedule into a stepwise ladder, allowing multiple frames to be denoised simultaneously. This significantly improves sampling efficiency while maintaining motion consistency, achieving up to a 2x speedup with high visual fidelity and temporal coherence. We evaluate our approach on ZEGGS and BEAT, strong benchmarks for real-world applicability. Our framework is universally applicable to any diffusion-based gesture generation model, transforming it into a streaming approach. Applied to three state-of-the-art methods, it consistently outperforms them, demonstrating its effectiveness as a generalizable and efficient solution for real-time, high-fidelity co-speech gesture synthesis.
SDE Matching: Scalable and Simulation-Free Training of Latent Stochastic Differential Equations
Feb 04, 2025The Latent Stochastic Differential Equation (SDE) is a powerful tool for time series and sequence modeling. However, training Latent SDEs typically relies on adjoint sensitivity methods, which depend on simulation and backpropagation through approximate SDE solutions, which limit scalability. In this work, we propose SDE Matching, a new simulation-free method for training Latent SDEs. Inspired by modern Score- and Flow Matching algorithms for learning generative dynamics, we extend these ideas to the domain of stochastic dynamics for time series and sequence modeling, eliminating the need for costly numerical simulations. Our results demonstrate that SDE Matching achieves performance comparable to adjoint sensitivity methods while drastically reducing computational complexity.
Where Do Large Learning Rates Lead Us?
Oct 29, 2024



It is generally accepted that starting neural networks training with large learning rates (LRs) improves generalization. Following a line of research devoted to understanding this effect, we conduct an empirical study in a controlled setting focusing on two questions: 1) how large an initial LR is required for obtaining optimal quality, and 2) what are the key differences between models trained with different LRs? We discover that only a narrow range of initial LRs slightly above the convergence threshold lead to optimal results after fine-tuning with a small LR or weight averaging. By studying the local geometry of reached minima, we observe that using LRs from this optimal range allows for the optimization to locate a basin that only contains high-quality minima. Additionally, we show that these initial LRs result in a sparse set of learned features, with a clear focus on those most relevant for the task. In contrast, starting training with too small LRs leads to unstable minima and attempts to learn all features simultaneously, resulting in poor generalization. Conversely, using initial LRs that are too large fails to detect a basin with good solutions and extract meaningful patterns from the data.
Guide-and-Rescale: Self-Guidance Mechanism for Effective Tuning-Free Real Image Editing
Sep 02, 2024



Despite recent advances in large-scale text-to-image generative models, manipulating real images with these models remains a challenging problem. The main limitations of existing editing methods are that they either fail to perform with consistent quality on a wide range of image edits or require time-consuming hyperparameter tuning or fine-tuning of the diffusion model to preserve the image-specific appearance of the input image. We propose a novel approach that is built upon a modified diffusion sampling process via the guidance mechanism. In this work, we explore the self-guidance technique to preserve the overall structure of the input image and its local regions appearance that should not be edited. In particular, we explicitly introduce layout-preserving energy functions that are aimed to save local and global structures of the source image. Additionally, we propose a noise rescaling mechanism that allows to preserve noise distribution by balancing the norms of classifier-free guidance and our proposed guiders during generation. Such a guiding approach does not require fine-tuning the diffusion model and exact inversion process. As a result, the proposed method provides a fast and high-quality editing mechanism. In our experiments, we show through human evaluation and quantitative analysis that the proposed method allows to produce desired editing which is more preferable by humans and also achieves a better trade-off between editing quality and preservation of the original image. Our code is available at https://github.com/FusionBrainLab/Guide-and-Rescale.
Regularized Distribution Matching Distillation for One-step Unpaired Image-to-Image Translation
Jun 20, 2024
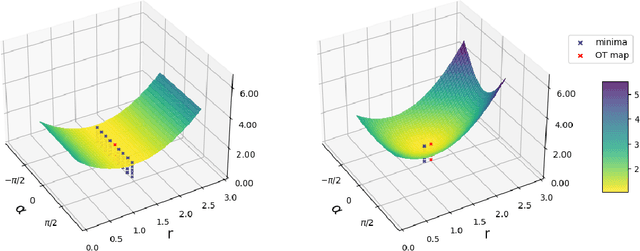
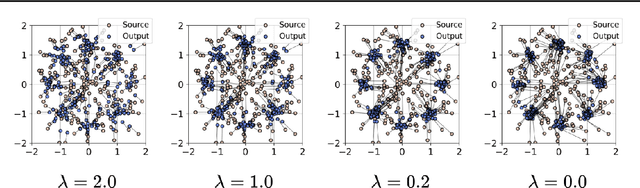
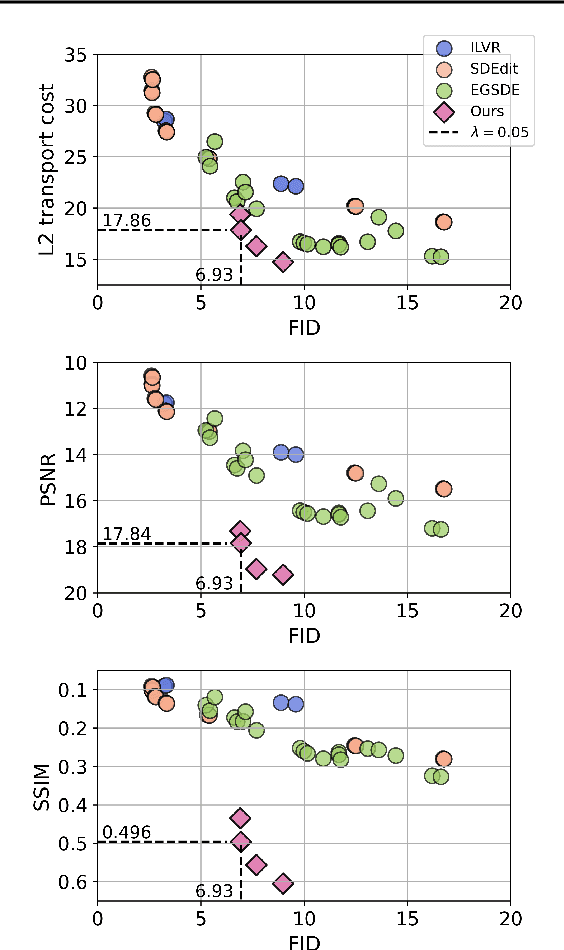
Diffusion distillation methods aim to compress the diffusion models into efficient one-step generators while trying to preserve quality. Among them, Distribution Matching Distillation (DMD) offers a suitable framework for training general-form one-step generators, applicable beyond unconditional generation. In this work, we introduce its modification, called Regularized Distribution Matching Distillation, applicable to unpaired image-to-image (I2I) problems. We demonstrate its empirical performance in application to several translation tasks, including 2D examples and I2I between different image datasets, where it performs on par or better than multi-step diffusion baselines.
Improving GFlowNets with Monte Carlo Tree Search
Jun 19, 2024Generative Flow Networks (GFlowNets) treat sampling from distributions over compositional discrete spaces as a sequential decision-making problem, training a stochastic policy to construct objects step by step. Recent studies have revealed strong connections between GFlowNets and entropy-regularized reinforcement learning. Building on these insights, we propose to enhance planning capabilities of GFlowNets by applying Monte Carlo Tree Search (MCTS). Specifically, we show how the MENTS algorithm (Xiao et al., 2019) can be adapted for GFlowNets and used during both training and inference. Our experiments demonstrate that this approach improves the sample efficiency of GFlowNet training and the generation fidelity of pre-trained GFlowNet models.