 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastFace: Tuning Identity Preservation in Distilled Diffusion via Guidance and Attention
May 28, 2025In latest years plethora of identity-preserving adapters for a personalized generation with diffusion models have been released. Their main disadvantage is that they are dominantly trained jointly with base diffusion models, which suffer from slow multi-step inference. This work aims to tackle the challenge of training-free adaptation of pretrained ID-adapters to diffusion models accelerated via distillation - through careful re-design of classifier-free guidance for few-step stylistic generation and attention manipulation mechanisms in decoupled blocks to improve identity similarity and fidelity, we propose universal FastFace framework. Additionally, we develop a disentangled public evaluation protocol for id-preserving adapters.
Guide-and-Rescale: Self-Guidance Mechanism for Effective Tuning-Free Real Image Editing
Sep 02, 2024



Despite recent advances in large-scale text-to-image generative models, manipulating real images with these models remains a challenging problem. The main limitations of existing editing methods are that they either fail to perform with consistent quality on a wide range of image edits or require time-consuming hyperparameter tuning or fine-tuning of the diffusion model to preserve the image-specific appearance of the input image. We propose a novel approach that is built upon a modified diffusion sampling process via the guidance mechanism. In this work, we explore the self-guidance technique to preserve the overall structure of the input image and its local regions appearance that should not be edited. In particular, we explicitly introduce layout-preserving energy functions that are aimed to save local and global structures of the source image. Additionally, we propose a noise rescaling mechanism that allows to preserve noise distribution by balancing the norms of classifier-free guidance and our proposed guiders during generation. Such a guiding approach does not require fine-tuning the diffusion model and exact inversion process. As a result, the proposed method provides a fast and high-quality editing mechanism. In our experiments, we show through human evaluation and quantitative analysis that the proposed method allows to produce desired editing which is more preferable by humans and also achieves a better trade-off between editing quality and preservation of the original image. Our code is available at https://github.com/FusionBrainLab/Guide-and-Rescale.
The Devil is in the Details: StyleFeatureEditor for Detail-Rich StyleGAN Inversion and High Quality Image Editing
Jun 15, 2024The task of manipulating real image attributes through StyleGAN inversion has been extensively researched. This process involves searching latent variables from a well-trained StyleGAN generator that can synthesize a real image, modifying these latent variables, and then synthesizing an image with the desired edits. A balance must be struck between the quality of the reconstruction and the ability to edit. Earlier studies utilized the low-dimensional W-space for latent search, which facilitated effective editing but struggled with reconstructing intricate details. More recent research has turned to the high-dimensional feature space F, which successfully inverses the input image but loses much of the detail during editing. In this paper, we introduce StyleFeatureEditor -- a novel method that enables editing in both w-latents and F-latents. This technique not only allows for the reconstruction of finer image details but also ensures their preservation during editing. We also present a new training pipeline specifically designed to train our model to accurately edit F-latents. Our method is compared with state-of-the-art encoding approaches, demonstrating that our model excels in terms of reconstruction quality and is capable of editing even challenging out-of-domain examples. Code is available at https://github.com/AIRI-Institute/StyleFeatureEditor.
StyleDomain: Analysis of StyleSpace for Domain Adaptation of StyleGAN
Dec 20, 2022



Domain adaptation of GANs is a problem of fine-tuning the state-of-the-art GAN models (e.g. StyleGAN) pretrained on a large dataset to a specific domain with few samples (e.g. painting faces, sketches, etc.). While there are a great number of methods that tackle this problem in different ways there are still many important questions that remain unanswered. In this paper, we provide a systematic and in-depth analysis of the domain adaptation problem of GANs, focusing on the StyleGAN model. First, we perform a detailed exploration of the most important parts of StyleGAN that are responsible for adapting the generator to a new domain depending on the similarity between the source and target domains. In particular, we show that affine layers of StyleGAN can be sufficient for fine-tuning to similar domains. Second, inspired by these findings, we investigate StyleSpace to utilize it for domain adaptation. We show that there exist directions in the StyleSpace that can adapt StyleGAN to new domains. Further, we examine these directions and discover their many surprising properties. Finally, we leverage our analysis and findings to deliver practical improvements and applications in such standard tasks as image-to-image translation and cross-domain morphing.
HyperDomainNet: Universal Domain Adaptation for Generative Adversarial Networks
Oct 18, 2022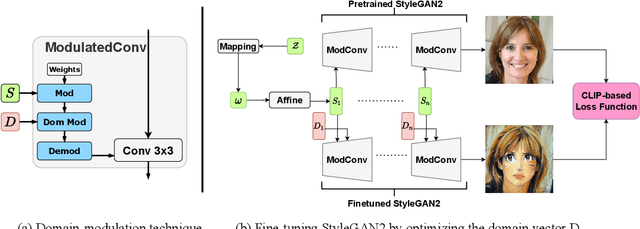
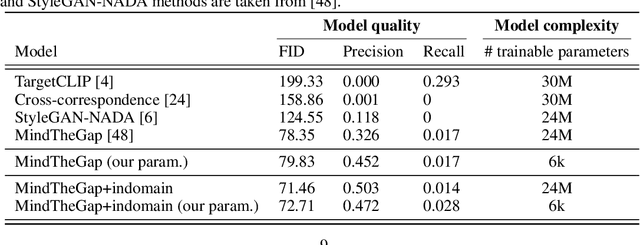
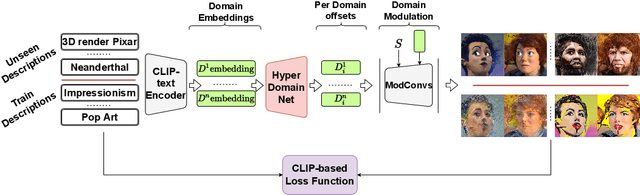
Domain adaptation framework of GANs has achieved great progress in recent years as a main successful approach of training contemporary GANs in the case of very limited training data. In this work, we significantly improve this framework by proposing an extremely compact parameter space for fine-tuning the generator. We introduce a novel domain-modulation technique that allows to optimize only 6 thousand-dimensional vector instead of 30 million weights of StyleGAN2 to adapt to a target domain. We apply this parameterization to the state-of-art domain adaptation methods and show that it has almost the same expressiveness as the full parameter space. Additionally, we propose a new regularization loss that considerably enhances the diversity of the fine-tuned generator. Inspired by the reduction in the size of the optimizing parameter space we consider the problem of multi-domain adaptation of GANs, i.e. setting when the same model can adapt to several domains depending on the input query. We propose the HyperDomainNet that is a hypernetwork that predicts our parameterization given the target domain. We empirically confirm that it can successfully learn a number of domains at once and may even generalize to unseen domains. Source code can be found at https://github.com/MACderRu/HyperDomainNet