 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRiemannLoRA: A Unified Riemannian Framework for Ambiguity-Free LoRA Optimization
Jul 16, 2025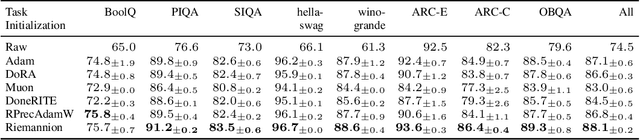
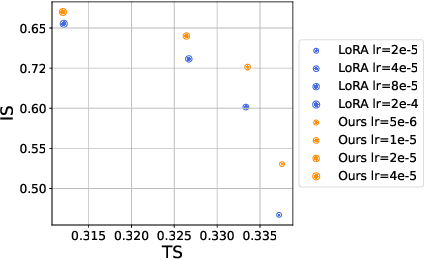


Low-Rank Adaptation (LoRA) has become a widely adopted standard for parameter-efficient fine-tuning of large language models (LLMs), significantly reducing memory and computational demands. However, challenges remain, including finding optimal initialization strategies or mitigating overparametrization in low-rank matrix factorization. In this work, we propose a novel approach that addresses both of the challenges simultaneously within a unified framework. Our method treats a set of fixed-rank LoRA matrices as a smooth manifold. Considering adapters as elements on this manifold removes overparametrization, while determining the direction of the fastest loss decrease along the manifold provides initialization. Special care is taken to obtain numerically stable and computationally efficient implementation of our method, using best practices from numerical linear algebra and Riemannian optimization. Experimental results on LLM and diffusion model architectures demonstrate that RiemannLoRA consistently improves both convergence speed and final performance over standard LoRA and its state-of-the-art modifications.
CLEAR: Character Unlearning in Textual and Visual Modalities
Oct 23, 2024
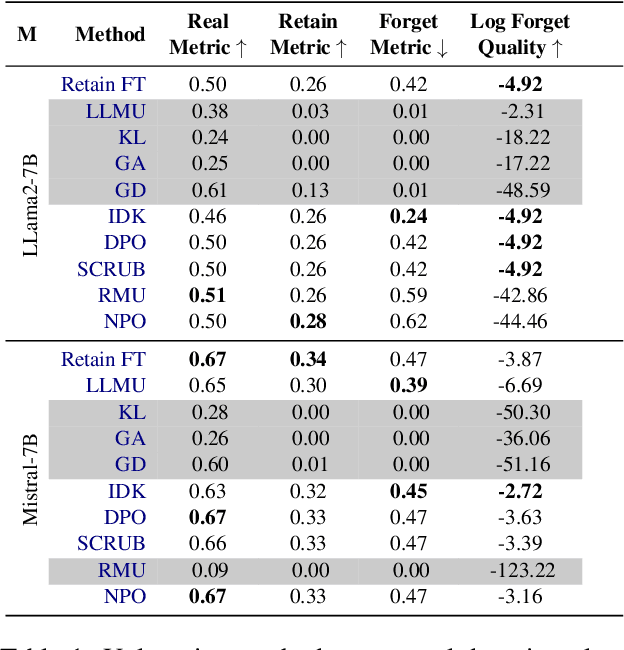
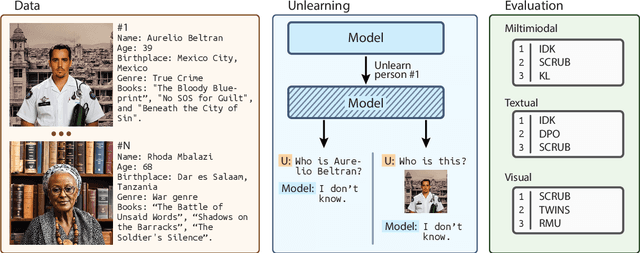
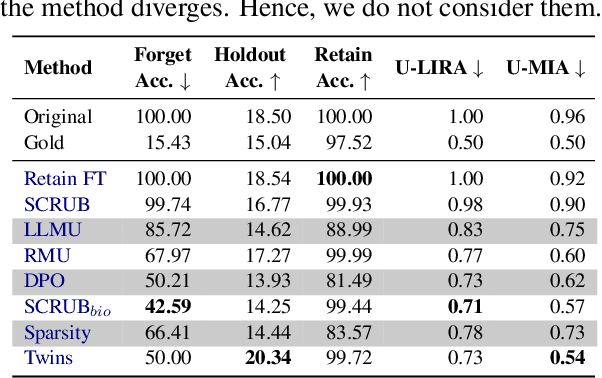
Machine Unlearning (MU) is critical for enhancing privacy and security in deep learning models, particularly in large multimodal language models (MLLMs), by removing specific private or hazardous information. While MU has made significant progress in textual and visual modalities, multimodal unlearning (MMU) remains significantly underexplored, partially due to the absence of a suitable open-source benchmark. To address this, we introduce CLEAR, a new benchmark designed to evaluate MMU methods. CLEAR contains 200 fictitious individuals and 3,700 images linked with corresponding question-answer pairs, enabling a thorough evaluation across modalities. We assess 10 MU methods, adapting them for MMU, and highlight new challenges specific to multimodal forgetting. We also demonstrate that simple $\ell_1$ regularization on LoRA weights significantly mitigates catastrophic forgetting, preserving model performance on retained data. The dataset is available at https://huggingface.co/datasets/therem/CLEAR
The Devil is in the Details: StyleFeatureEditor for Detail-Rich StyleGAN Inversion and High Quality Image Editing
Jun 15, 2024The task of manipulating real image attributes through StyleGAN inversion has been extensively researched. This process involves searching latent variables from a well-trained StyleGAN generator that can synthesize a real image, modifying these latent variables, and then synthesizing an image with the desired edits. A balance must be struck between the quality of the reconstruction and the ability to edit. Earlier studies utilized the low-dimensional W-space for latent search, which facilitated effective editing but struggled with reconstructing intricate details. More recent research has turned to the high-dimensional feature space F, which successfully inverses the input image but loses much of the detail during editing. In this paper, we introduce StyleFeatureEditor -- a novel method that enables editing in both w-latents and F-latents. This technique not only allows for the reconstruction of finer image details but also ensures their preservation during editing. We also present a new training pipeline specifically designed to train our model to accurately edit F-latents. Our method is compared with state-of-the-art encoding approaches, demonstrating that our model excels in terms of reconstruction quality and is capable of editing even challenging out-of-domain examples. Code is available at https://github.com/AIRI-Institute/StyleFeatureEditor.