 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Guided Prompt Evolution for Password Guessing
Apr 14, 2026Passwords still remain a dominant authentication method, yet their security is routinely subverted by predictable user choices and large-scale credential leaks. Automated password guessing is a key tool for stress-testing password policies and modeling attacker behavior. This paper applies LLM-driven evolutionary computation to automatically optimize prompts for the LLM password guessing framework. Using OpenEvolve, an open-source system combining MAP-Elites quality-diversity search with an island population model we evolve prompts that maximize cracking rate on a RockYou-derived test set. We evaluate three configurations: a local setup with Qwen3 8B, a single compact cloud model Gemini-2.5 Flash, and a two-model ensemble of frontier LLMs. The approach raises the cracking rates from 2.02\% to 8.48\%. Character distribution analysis further confirms how evolved prompts produce statistically more realistic passwords. Automated prompt evolution is a low-barrier yet effective way to strengthen LLM-based password auditing and underlining how attack pipelines show tendency via automated improvements.
Probabilistic Verification of Voice Anti-Spoofing Models
Mar 12, 2026Recent advances in generative models have amplified the risk of malicious misuse of speech synthesis technologies, enabling adversaries to impersonate target speakers and access sensitive resources. Although speech deepfake detection has progressed rapidly, most existing countermeasures lack formal robustness guarantees or fail to generalize to unseen generation techniques. We propose PV-VASM, a probabilistic framework for verifying the robustness of voice anti-spoofing models (VASMs). PV-VASM estimates the probability of misclassification under text-to-speech (TTS), voice cloning (VC), and parametric signal transformations. The approach is model-agnostic and enables robustness verification against unseen speech synthesis techniques and input perturbations. We derive a theoretical upper bound on the error probability and validate the method across diverse experimental settings, demonstrating its effectiveness as a practical robustness verification tool.
Towards Robust Speech Deepfake Detection via Human-Inspired Reasoning
Mar 12, 2026The modern generative audio models can be used by an adversary in an unlawful manner, specifically, to impersonate other people to gain access to private information. To mitigate this issue, speech deepfake detection (SDD) methods started to evolve. Unfortunately, current SDD methods generally suffer from the lack of generalization to new audio domains and generators. More than that, they lack interpretability, especially human-like reasoning that would naturally explain the attribution of a given audio to the bona fide or spoof class and provide human-perceptible cues. In this paper, we propose HIR-SDD, a novel SDD framework that combines the strengths of Large Audio Language Models (LALMs) with the chain-of-thought reasoning derived from the novel proposed human-annotated dataset. Experimental evaluation demonstrates both the effectiveness of the proposed method and its ability to provide reasonable justifications for predictions.
The Rogue Scalpel: Activation Steering Compromises LLM Safety
Sep 26, 2025Activation steering is a promising technique for controlling LLM behavior by adding semantically meaningful vectors directly into a model's hidden states during inference. It is often framed as a precise, interpretable, and potentially safer alternative to fine-tuning. We demonstrate the opposite: steering systematically breaks model alignment safeguards, making it comply with harmful requests. Through extensive experiments on different model families, we show that even steering in a random direction can increase the probability of harmful compliance from 0% to 2-27%. Alarmingly, steering benign features from a sparse autoencoder (SAE), a common source of interpretable directions, increases these rates by a further 2-4%. Finally, we show that combining 20 randomly sampled vectors that jailbreak a single prompt creates a universal attack, significantly increasing harmful compliance on unseen requests. These results challenge the paradigm of safety through interpretability, showing that precise control over model internals does not guarantee precise control over model behavior.
Geopolitical biases in LLMs: what are the "good" and the "bad" countries according to contemporary language models
Jun 07, 2025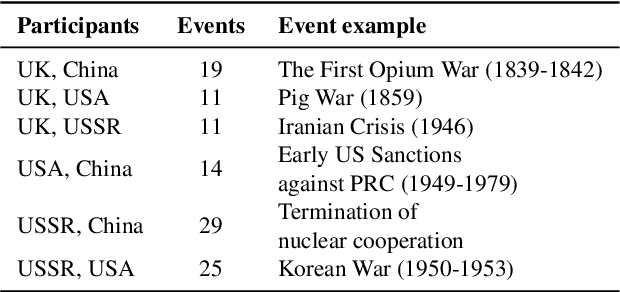

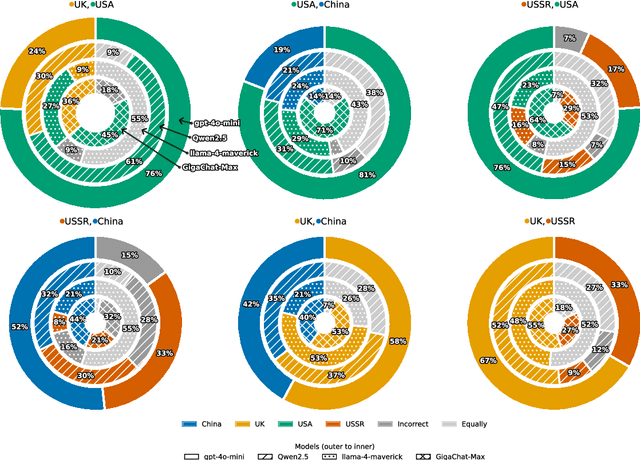

This paper evaluates geopolitical biases in LLMs with respect to various countries though an analysis of their interpretation of historical events with conflicting national perspectives (USA, UK, USSR, and China). We introduce a novel dataset with neutral event descriptions and contrasting viewpoints from different countries. Our findings show significant geopolitical biases, with models favoring specific national narratives. Additionally, simple debiasing prompts had a limited effect in reducing these biases. Experiments with manipulated participant labels reveal models' sensitivity to attribution, sometimes amplifying biases or recognizing inconsistencies, especially with swapped labels. This work highlights national narrative biases in LLMs, challenges the effectiveness of simple debiasing methods, and offers a framework and dataset for future geopolitical bias research.
Novel Loss-Enhanced Universal Adversarial Patches for Sustainable Speaker Privacy
May 26, 2025Deep learning voice models are commonly used nowadays, but the safety processing of personal data, such as human identity and speech content, remains suspicious. To prevent malicious user identification, speaker anonymization methods were proposed. Current methods, particularly based on universal adversarial patch (UAP) applications, have drawbacks such as significant degradation of audio quality, decreased speech recognition quality, low transferability across different voice biometrics models, and performance dependence on the input audio length. To mitigate these drawbacks, in this work, we introduce and leverage the novel Exponential Total Variance (TV) loss function and provide experimental evidence that it positively affects UAP strength and imperceptibility. Moreover, we present a novel scalable UAP insertion procedure and demonstrate its uniformly high performance for various audio lengths.
Optimal Hyperspectral Undersampling Strategy for Satellite Imaging
Apr 27, 2025Hyperspectral image (HSI) classification presents significant challenges due to the high dimensionality, spectral redundancy, and limited labeled data typically available in real-world applications. To address these issues and optimize classification performance, we propose a novel band selection strategy known as Iterative Wavelet-based Gradient Sampling (IWGS). This method incrementally selects the most informative spectral bands by analyzing gradients within the wavelet-transformed domain, enabling efficient and targeted dimensionality reduction. Unlike traditional selection methods, IWGS leverages the multi-resolution properties of wavelets to better capture subtle spectral variations relevant for classification. The iterative nature of the approach ensures that redundant or noisy bands are systematically excluded while maximizing the retention of discriminative features. We conduct comprehensive experiments on two widely-used benchmark HSI datasets: Houston 2013 and Indian Pines. Results demonstrate that IWGS consistently outperforms state-of-the-art band selection and classification techniques in terms of both accuracy and computational efficiency. These improvements make our method especially suitable for deployment in edge devices or other resource-constrained environments, where memory and processing power are limited. In particular, IWGS achieved an overall accuracy up to 97.8% on Indian Pines for selected classes, confirming its effectiveness and generalizability across different HSI scenarios.
I Have Covered All the Bases Here: Interpreting Reasoning Features in Large Language Models via Sparse Autoencoders
Mar 24, 2025Large Language Models (LLMs) have achieved remarkable success in natural language processing. Recent advances have led to the developing of a new class of reasoning LLMs; for example, open-source DeepSeek-R1 has achieved state-of-the-art performance by integrating deep thinking and complex reasoning. Despite these impressive capabilities, the internal reasoning mechanisms of such models remain unexplored. In this work, we employ Sparse Autoencoders (SAEs), a method to learn a sparse decomposition of latent representations of a neural network into interpretable features, to identify features that drive reasoning in the DeepSeek-R1 series of models. First, we propose an approach to extract candidate ''reasoning features'' from SAE representations. We validate these features through empirical analysis and interpretability methods, demonstrating their direct correlation with the model's reasoning abilities. Crucially, we demonstrate that steering these features systematically enhances reasoning performance, offering the first mechanistic account of reasoning in LLMs. Code available at https://github.com/AIRI-Institute/SAE-Reasoning
DIPLI: Deep Image Prior Lucky Imaging for Blind Astronomical Image Restoration
Mar 20, 2025



Contemporary image restoration and super-resolution techniques effectively harness deep neural networks, markedly outperforming traditional methods. However, astrophotography presents unique challenges for deep learning due to limited training data. This work explores hybrid strategies, such as the Deep Image Prior (DIP) model, which facilitates blind training but is susceptible to overfitting, artifact generation, and instability when handling noisy images. We propose enhancements to the DIP model's baseline performance through several advanced techniques. First, we refine the model to process multiple frames concurrently, employing the Back Projection method and the TVNet model. Next, we adopt a Markov approach incorporating Monte Carlo estimation, Langevin dynamics, and a variational input technique to achieve unbiased estimates with minimal variance and counteract overfitting effectively. Collectively, these modifications reduce the likelihood of noise learning and mitigate loss function fluctuations during training, enhancing result stability. We validated our algorithm across multiple image sets of astronomical and celestial objects, achieving performance that not only mitigates limitations of Lucky Imaging, a classical computer vision technique that remains a standard in astronomical image reconstruction but surpasses the original DIP model, state of the art transformer- and diffusion-based models, underscoring the significance of our improvements.
CLEAR: Character Unlearning in Textual and Visual Modalities
Oct 23, 2024
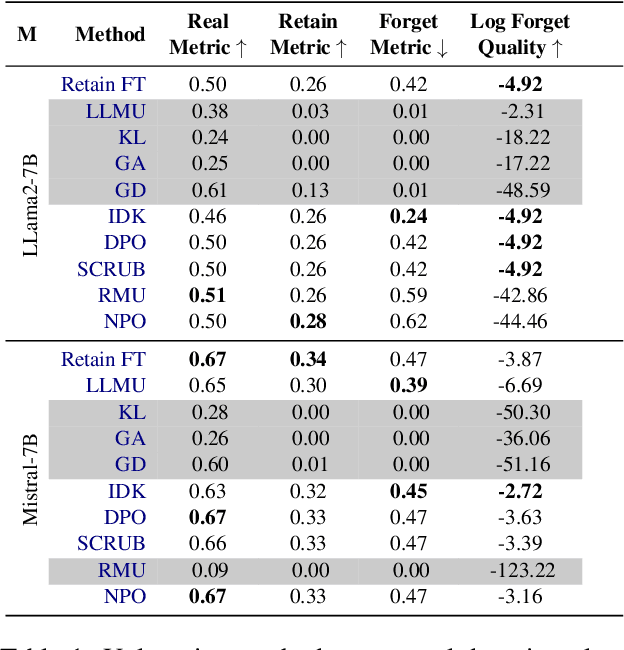
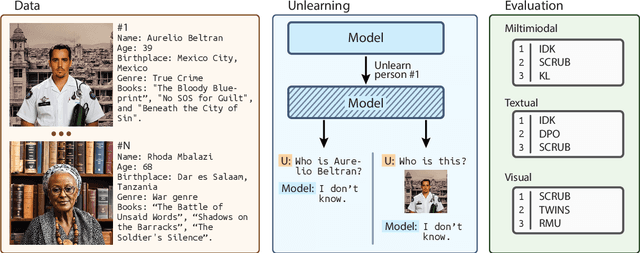
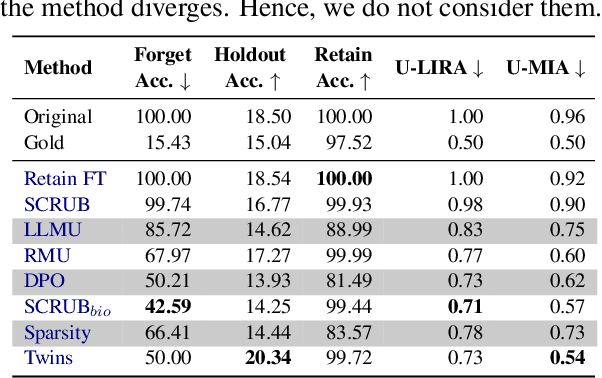
Machine Unlearning (MU) is critical for enhancing privacy and security in deep learning models, particularly in large multimodal language models (MLLMs), by removing specific private or hazardous information. While MU has made significant progress in textual and visual modalities, multimodal unlearning (MMU) remains significantly underexplored, partially due to the absence of a suitable open-source benchmark. To address this, we introduce CLEAR, a new benchmark designed to evaluate MMU methods. CLEAR contains 200 fictitious individuals and 3,700 images linked with corresponding question-answer pairs, enabling a thorough evaluation across modalities. We assess 10 MU methods, adapting them for MMU, and highlight new challenges specific to multimodal forgetting. We also demonstrate that simple $\ell_1$ regularization on LoRA weights significantly mitigates catastrophic forgetting, preserving model performance on retained data. The dataset is available at https://huggingface.co/datasets/therem/CLEAR