 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActiveMark: on watermarking of visual foundation models via massive activations
Oct 06, 2025Being trained on large and vast datasets, visual foundation models (VFMs) can be fine-tuned for diverse downstream tasks, achieving remarkable performance and efficiency in various computer vision applications. The high computation cost of data collection and training motivates the owners of some VFMs to distribute them alongside the license to protect their intellectual property rights. However, a dishonest user of the protected model's copy may illegally redistribute it, for example, to make a profit. As a consequence, the development of reliable ownership verification tools is of great importance today, since such methods can be used to differentiate between a redistributed copy of the protected model and an independent model. In this paper, we propose an approach to ownership verification of visual foundation models by fine-tuning a small set of expressive layers of a VFM along with a small encoder-decoder network to embed digital watermarks into an internal representation of a hold-out set of input images. Importantly, the watermarks embedded remain detectable in the functional copies of the protected model, obtained, for example, by fine-tuning the VFM for a particular downstream task. Theoretically and experimentally, we demonstrate that the proposed method yields a low probability of false detection of a non-watermarked model and a low probability of false misdetection of a watermarked model.
Spread them Apart: Towards Robust Watermarking of Generated Content
Feb 11, 2025Generative models that can produce realistic images have improved significantly in recent years. The quality of the generated content has increased drastically, so sometimes it is very difficult to distinguish between the real images and the generated ones. Such an improvement comes at a price of ethical concerns about the usage of the generative models: the users of generative models can improperly claim ownership of the generated content protected by a license. In this paper, we propose an approach to embed watermarks into the generated content to allow future detection of the generated content and identification of the user who generated it. The watermark is embedded during the inference of the model, so the proposed approach does not require the retraining of the latter. We prove that watermarks embedded are guaranteed to be robust against additive perturbations of a bounded magnitude. We apply our method to watermark diffusion models and show that it matches state-of-the-art watermarking schemes in terms of robustness to different types of synthetic watermark removal attacks.
Stochastic BIQA: Median Randomized Smoothing for Certified Blind Image Quality Assessment
Nov 19, 2024



Most modern No-Reference Image-Quality Assessment (NR-IQA) metrics are based on neural networks vulnerable to adversarial attacks. Attacks on such metrics lead to incorrect image/video quality predictions, which poses significant risks, especially in public benchmarks. Developers of image processing algorithms may unfairly increase the score of a target IQA metric without improving the actual quality of the adversarial image. Although some empirical defenses for IQA metrics were proposed, they do not provide theoretical guarantees and may be vulnerable to adaptive attacks. This work focuses on developing a provably robust no-reference IQA metric. Our method is based on Median Smoothing (MS) combined with an additional convolution denoiser with ranking loss to improve the SROCC and PLCC scores of the defended IQA metric. Compared with two prior methods on three datasets, our method exhibited superior SROCC and PLCC scores while maintaining comparable certified guarantees.
Model Mimic Attack: Knowledge Distillation for Provably Transferable Adversarial Examples
Oct 21, 2024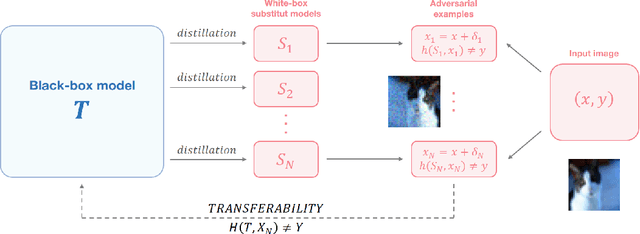
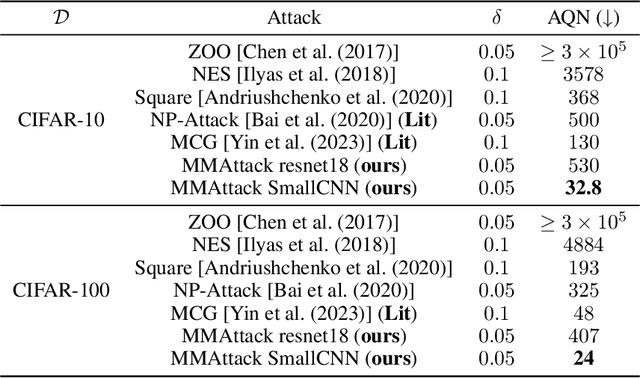
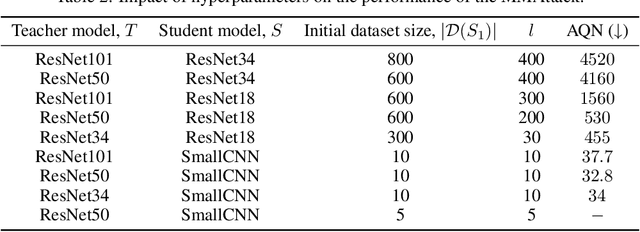
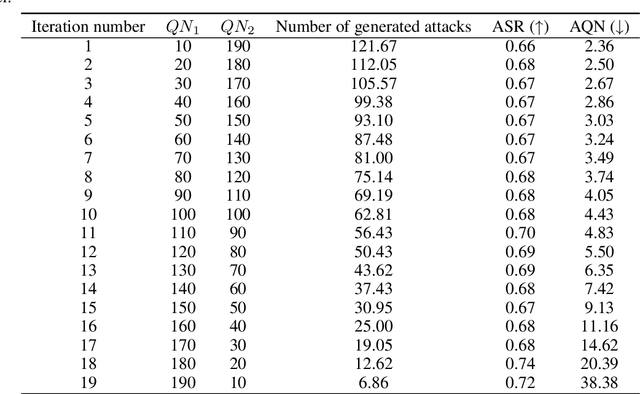
The vulnerability of artificial neural networks to adversarial perturbations in the black-box setting is widely studied in the literature. The majority of attack methods to construct these perturbations suffer from an impractically large number of queries required to find an adversarial example. In this work, we focus on knowledge distillation as an approach to conduct transfer-based black-box adversarial attacks and propose an iterative training of the surrogate model on an expanding dataset. This work is the first, to our knowledge, to provide provable guarantees on the success of knowledge distillation-based attack on classification neural networks: we prove that if the student model has enough learning capabilities, the attack on the teacher model is guaranteed to be found within the finite number of distillation iterations.
GLiRA: Black-Box Membership Inference Attack via Knowledge Distillation
May 13, 2024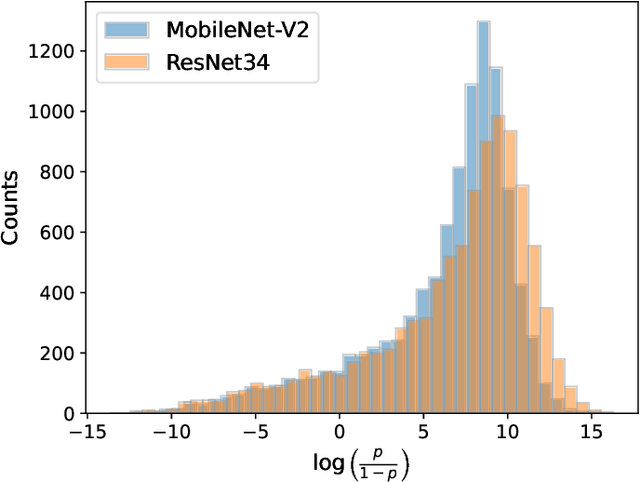
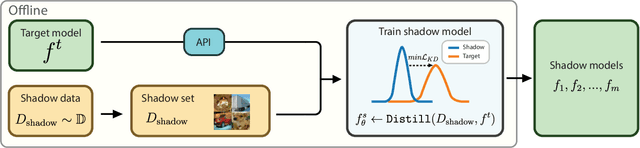
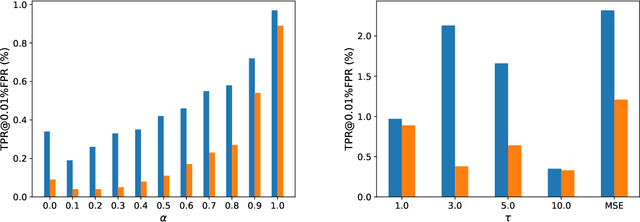
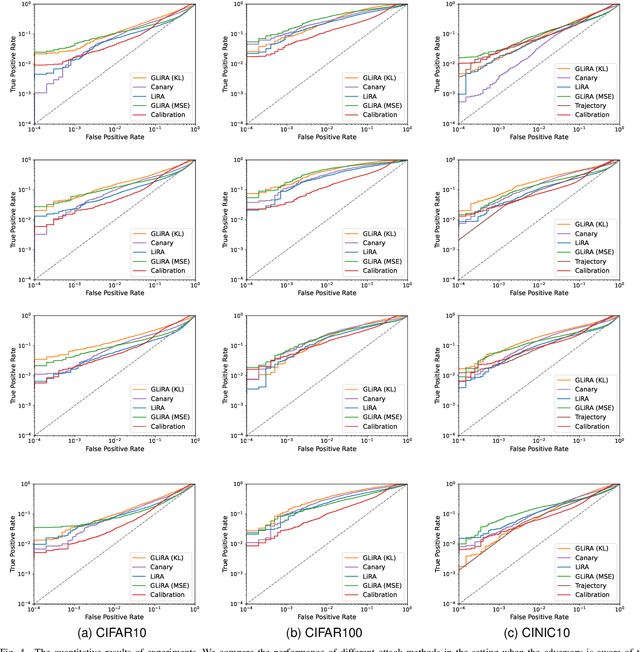
While Deep Neural Networks (DNNs) have demonstrated remarkable performance in tasks related to perception and control, there are still several unresolved concerns regarding the privacy of their training data, particularly in the context of vulnerability to Membership Inference Attacks (MIAs). In this paper, we explore a connection between the susceptibility to membership inference attacks and the vulnerability to distillation-based functionality stealing attacks. In particular, we propose {GLiRA}, a distillation-guided approach to membership inference attack on the black-box neural network. We observe that the knowledge distillation significantly improves the efficiency of likelihood ratio of membership inference attack, especially in the black-box setting, i.e., when the architecture of the target model is unknown to the attacker. We evaluate the proposed method across multiple image classification datasets and models and demonstrate that likelihood ratio attacks when guided by the knowledge distillation, outperform the current state-of-the-art membership inference attacks in the black-box setting.
Certification of Speaker Recognition Models to Additive Perturbations
Apr 29, 2024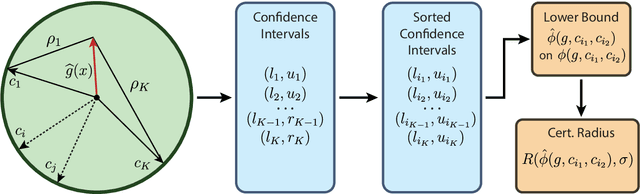
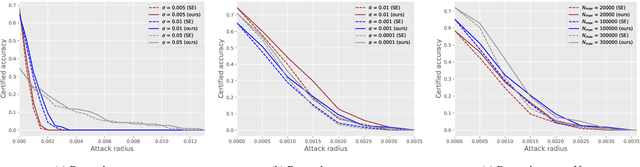
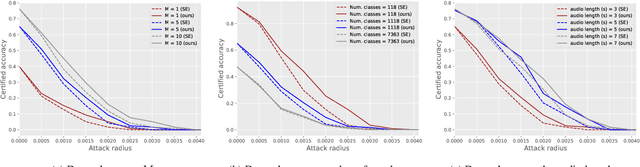
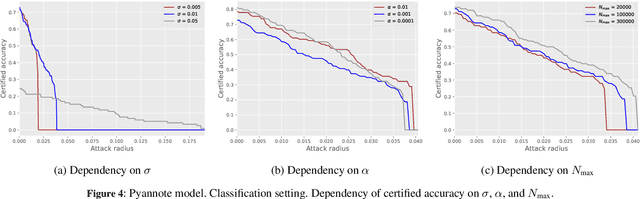
Speaker recognition technology is applied in various tasks ranging from personal virtual assistants to secure access systems. However, the robustness of these systems against adversarial attacks, particularly to additive perturbations, remains a significant challenge. In this paper, we pioneer applying robustness certification techniques to speaker recognition, originally developed for the image domain. In our work, we cover this gap by transferring and improving randomized smoothing certification techniques against norm-bounded additive perturbations for classification and few-shot learning tasks to speaker recognition. We demonstrate the effectiveness of these methods on VoxCeleb 1 and 2 datasets for several models. We expect this work to improve voice-biometry robustness, establish a new certification benchmark, and accelerate research of certification methods in the audio domain.
Probabilistically Robust Watermarking of Neural Networks
Jan 16, 2024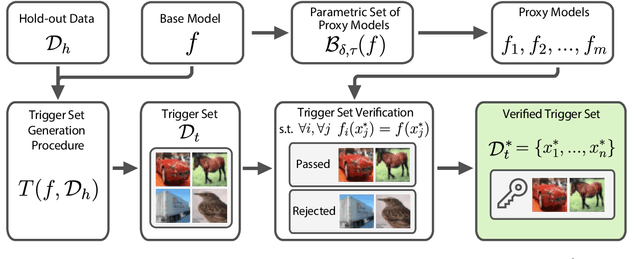
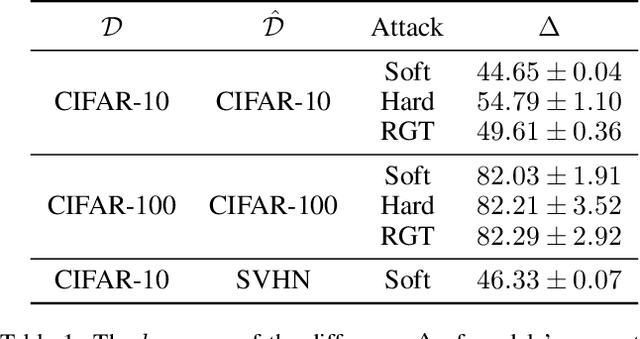
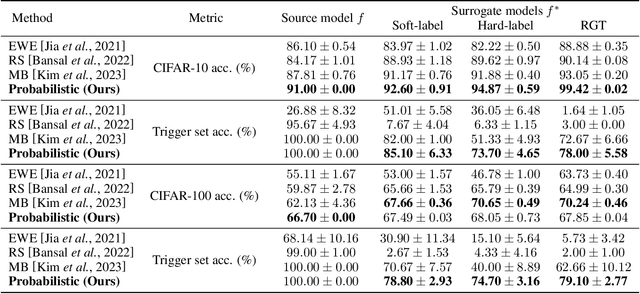
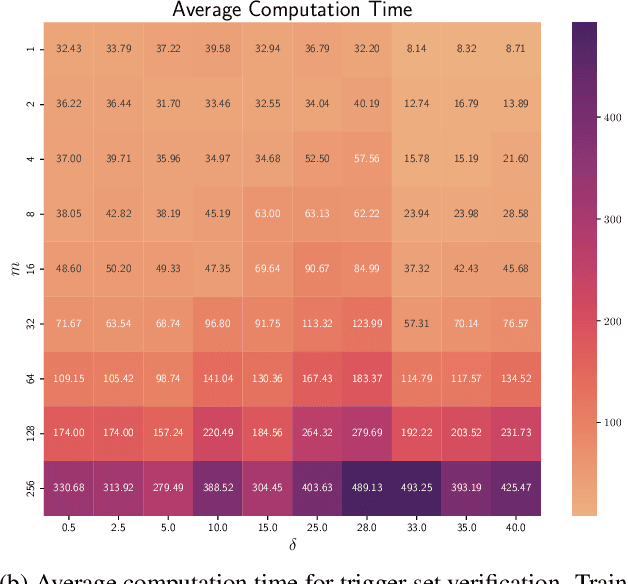
As deep learning (DL) models are widely and effectively used in Machine Learning as a Service (MLaaS) platforms, there is a rapidly growing interest in DL watermarking techniques that can be used to confirm the ownership of a particular model. Unfortunately, these methods usually produce watermarks susceptible to model stealing attacks. In our research, we introduce a novel trigger set-based watermarking approach that demonstrates resilience against functionality stealing attacks, particularly those involving extraction and distillation. Our approach does not require additional model training and can be applied to any model architecture. The key idea of our method is to compute the trigger set, which is transferable between the source model and the set of proxy models with a high probability. In our experimental study, we show that if the probability of the set being transferable is reasonably high, it can be effectively used for ownership verification of the stolen model. We evaluate our method on multiple benchmarks and show that our approach outperforms current state-of-the-art watermarking techniques in all considered experimental setups.
Translate your gibberish: black-box adversarial attack on machine translation systems
Mar 20, 2023Neural networks are deployed widely in natural language processing tasks on the industrial scale, and perhaps the most often they are used as compounds of automatic machine translation systems. In this work, we present a simple approach to fool state-of-the-art machine translation tools in the task of translation from Russian to English and vice versa. Using a novel black-box gradient-free tensor-based optimizer, we show that many online translation tools, such as Google, DeepL, and Yandex, may both produce wrong or offensive translations for nonsensical adversarial input queries and refuse to translate seemingly benign input phrases. This vulnerability may interfere with understanding a new language and simply worsen the user's experience while using machine translation systems, and, hence, additional improvements of these tools are required to establish better translation.
Smoothed Embeddings for Certified Few-Shot Learning
Feb 02, 2022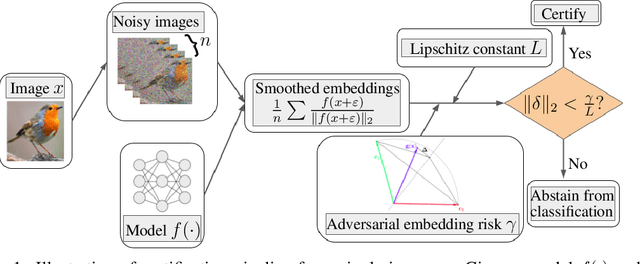
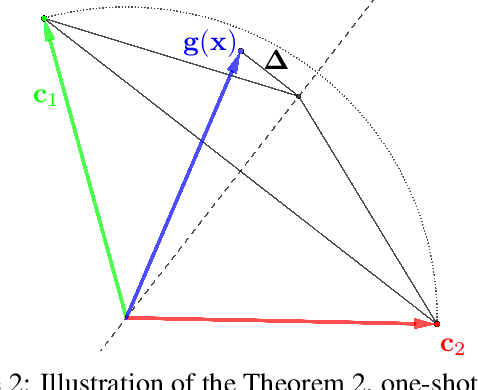
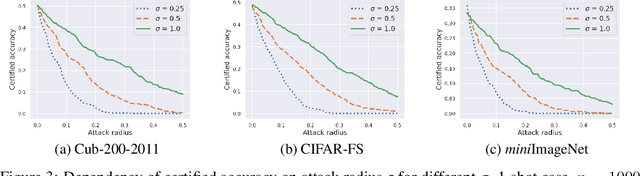
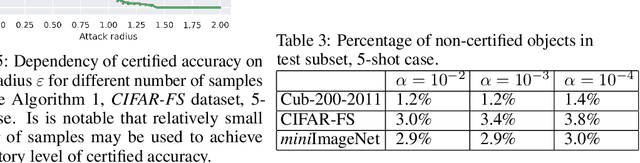
Randomized smoothing is considered to be the state-of-the-art provable defense against adversarial perturbations. However, it heavily exploits the fact that classifiers map input objects to class probabilities and do not focus on the ones that learn a metric space in which classification is performed by computing distances to embeddings of classes prototypes. In this work, we extend randomized smoothing to few-shot learning models that map inputs to normalized embeddings. We provide analysis of Lipschitz continuity of such models and derive robustness certificate against $\ell_2$-bounded perturbations that may be useful in few-shot learning scenarios. Our theoretical results are confirmed by experiments on different datasets.
CC-Cert: A Probabilistic Approach to Certify General Robustness of Neural Networks
Sep 22, 2021
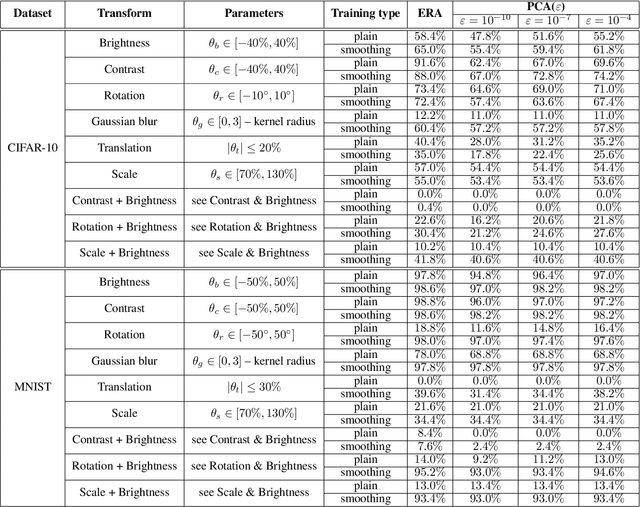
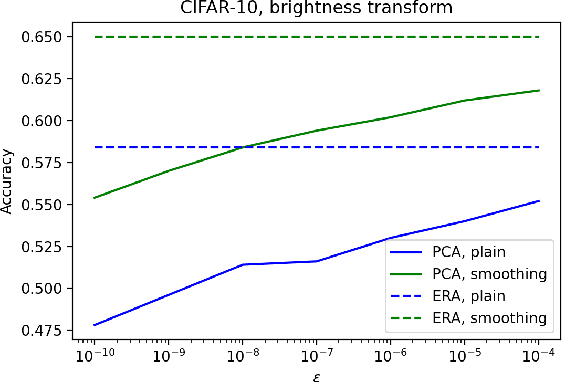
In safety-critical machine learning applications, it is crucial to defend models against adversarial attacks -- small modifications of the input that change the predictions. Besides rigorously studied $\ell_p$-bounded additive perturbations, recently proposed semantic perturbations (e.g. rotation, translation) raise a serious concern on deploying ML systems in real-world. Therefore, it is important to provide provable guarantees for deep learning models against semantically meaningful input transformations. In this paper, we propose a new universal probabilistic certification approach based on Chernoff-Cramer bounds that can be used in general attack settings. We estimate the probability of a model to fail if the attack is sampled from a certain distribution. Our theoretical findings are supported by experimental results on different datasets.