 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertification of Speaker Recognition Models to Additive Perturbations
Paper and Code
Apr 29, 2024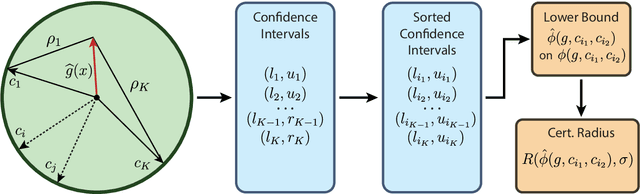
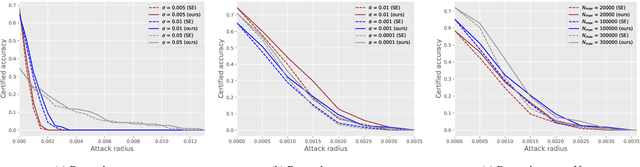
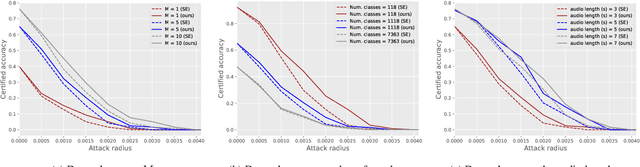
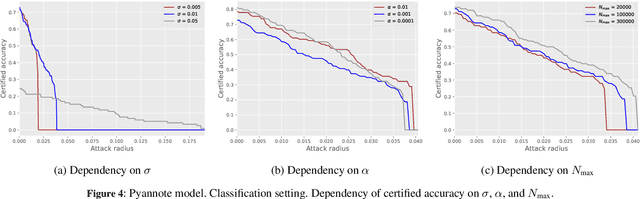
Speaker recognition technology is applied in various tasks ranging from personal virtual assistants to secure access systems. However, the robustness of these systems against adversarial attacks, particularly to additive perturbations, remains a significant challenge. In this paper, we pioneer applying robustness certification techniques to speaker recognition, originally developed for the image domain. In our work, we cover this gap by transferring and improving randomized smoothing certification techniques against norm-bounded additive perturbations for classification and few-shot learning tasks to speaker recognition. We demonstrate the effectiveness of these methods on VoxCeleb 1 and 2 datasets for several models. We expect this work to improve voice-biometry robustness, establish a new certification benchmark, and accelerate research of certification methods in the audio domain.