 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Verification of Voice Anti-Spoofing Models
Mar 12, 2026Recent advances in generative models have amplified the risk of malicious misuse of speech synthesis technologies, enabling adversaries to impersonate target speakers and access sensitive resources. Although speech deepfake detection has progressed rapidly, most existing countermeasures lack formal robustness guarantees or fail to generalize to unseen generation techniques. We propose PV-VASM, a probabilistic framework for verifying the robustness of voice anti-spoofing models (VASMs). PV-VASM estimates the probability of misclassification under text-to-speech (TTS), voice cloning (VC), and parametric signal transformations. The approach is model-agnostic and enables robustness verification against unseen speech synthesis techniques and input perturbations. We derive a theoretical upper bound on the error probability and validate the method across diverse experimental settings, demonstrating its effectiveness as a practical robustness verification tool.
Towards Robust Speech Deepfake Detection via Human-Inspired Reasoning
Mar 12, 2026The modern generative audio models can be used by an adversary in an unlawful manner, specifically, to impersonate other people to gain access to private information. To mitigate this issue, speech deepfake detection (SDD) methods started to evolve. Unfortunately, current SDD methods generally suffer from the lack of generalization to new audio domains and generators. More than that, they lack interpretability, especially human-like reasoning that would naturally explain the attribution of a given audio to the bona fide or spoof class and provide human-perceptible cues. In this paper, we propose HIR-SDD, a novel SDD framework that combines the strengths of Large Audio Language Models (LALMs) with the chain-of-thought reasoning derived from the novel proposed human-annotated dataset. Experimental evaluation demonstrates both the effectiveness of the proposed method and its ability to provide reasonable justifications for predictions.
Geopolitical biases in LLMs: what are the "good" and the "bad" countries according to contemporary language models
Jun 07, 2025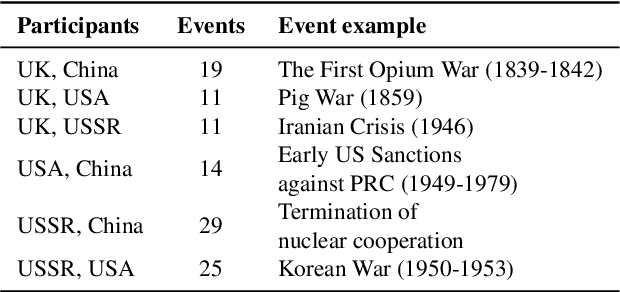

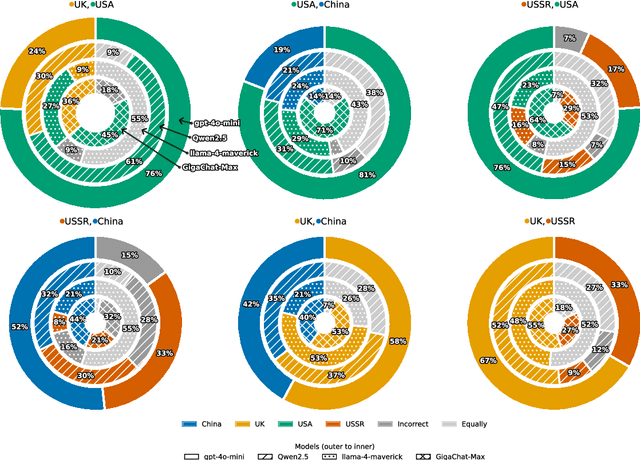

This paper evaluates geopolitical biases in LLMs with respect to various countries though an analysis of their interpretation of historical events with conflicting national perspectives (USA, UK, USSR, and China). We introduce a novel dataset with neutral event descriptions and contrasting viewpoints from different countries. Our findings show significant geopolitical biases, with models favoring specific national narratives. Additionally, simple debiasing prompts had a limited effect in reducing these biases. Experiments with manipulated participant labels reveal models' sensitivity to attribution, sometimes amplifying biases or recognizing inconsistencies, especially with swapped labels. This work highlights national narrative biases in LLMs, challenges the effectiveness of simple debiasing methods, and offers a framework and dataset for future geopolitical bias research.
Novel Loss-Enhanced Universal Adversarial Patches for Sustainable Speaker Privacy
May 26, 2025Deep learning voice models are commonly used nowadays, but the safety processing of personal data, such as human identity and speech content, remains suspicious. To prevent malicious user identification, speaker anonymization methods were proposed. Current methods, particularly based on universal adversarial patch (UAP) applications, have drawbacks such as significant degradation of audio quality, decreased speech recognition quality, low transferability across different voice biometrics models, and performance dependence on the input audio length. To mitigate these drawbacks, in this work, we introduce and leverage the novel Exponential Total Variance (TV) loss function and provide experimental evidence that it positively affects UAP strength and imperceptibility. Moreover, we present a novel scalable UAP insertion procedure and demonstrate its uniformly high performance for various audio lengths.
CLEAR: Character Unlearning in Textual and Visual Modalities
Oct 23, 2024
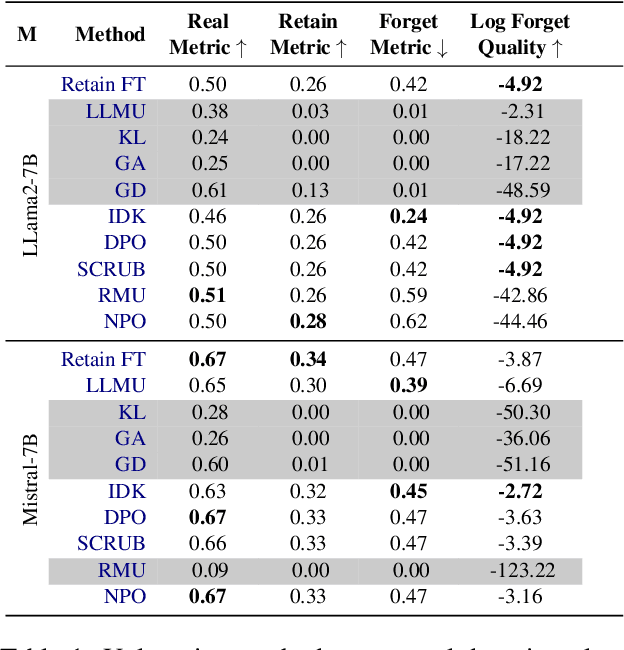
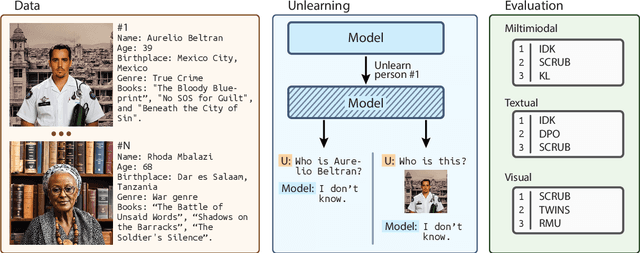
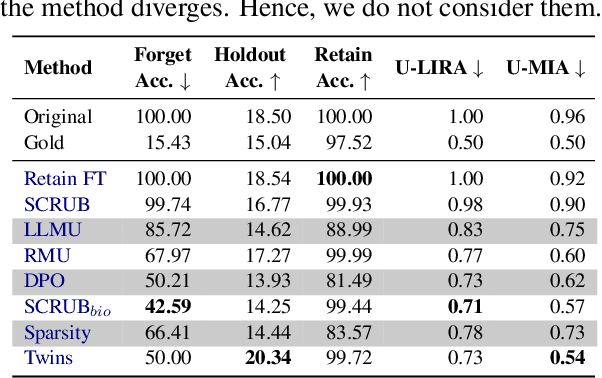
Machine Unlearning (MU) is critical for enhancing privacy and security in deep learning models, particularly in large multimodal language models (MLLMs), by removing specific private or hazardous information. While MU has made significant progress in textual and visual modalities, multimodal unlearning (MMU) remains significantly underexplored, partially due to the absence of a suitable open-source benchmark. To address this, we introduce CLEAR, a new benchmark designed to evaluate MMU methods. CLEAR contains 200 fictitious individuals and 3,700 images linked with corresponding question-answer pairs, enabling a thorough evaluation across modalities. We assess 10 MU methods, adapting them for MMU, and highlight new challenges specific to multimodal forgetting. We also demonstrate that simple $\ell_1$ regularization on LoRA weights significantly mitigates catastrophic forgetting, preserving model performance on retained data. The dataset is available at https://huggingface.co/datasets/therem/CLEAR
AASIST3: KAN-Enhanced AASIST Speech Deepfake Detection using SSL Features and Additional Regularization for the ASVspoof 2024 Challenge
Aug 30, 2024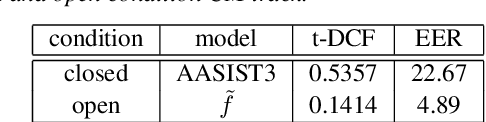

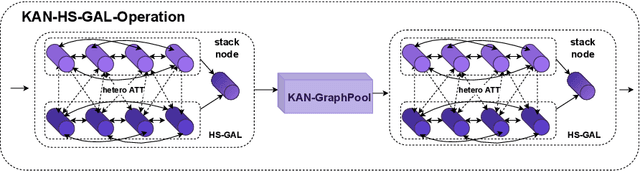
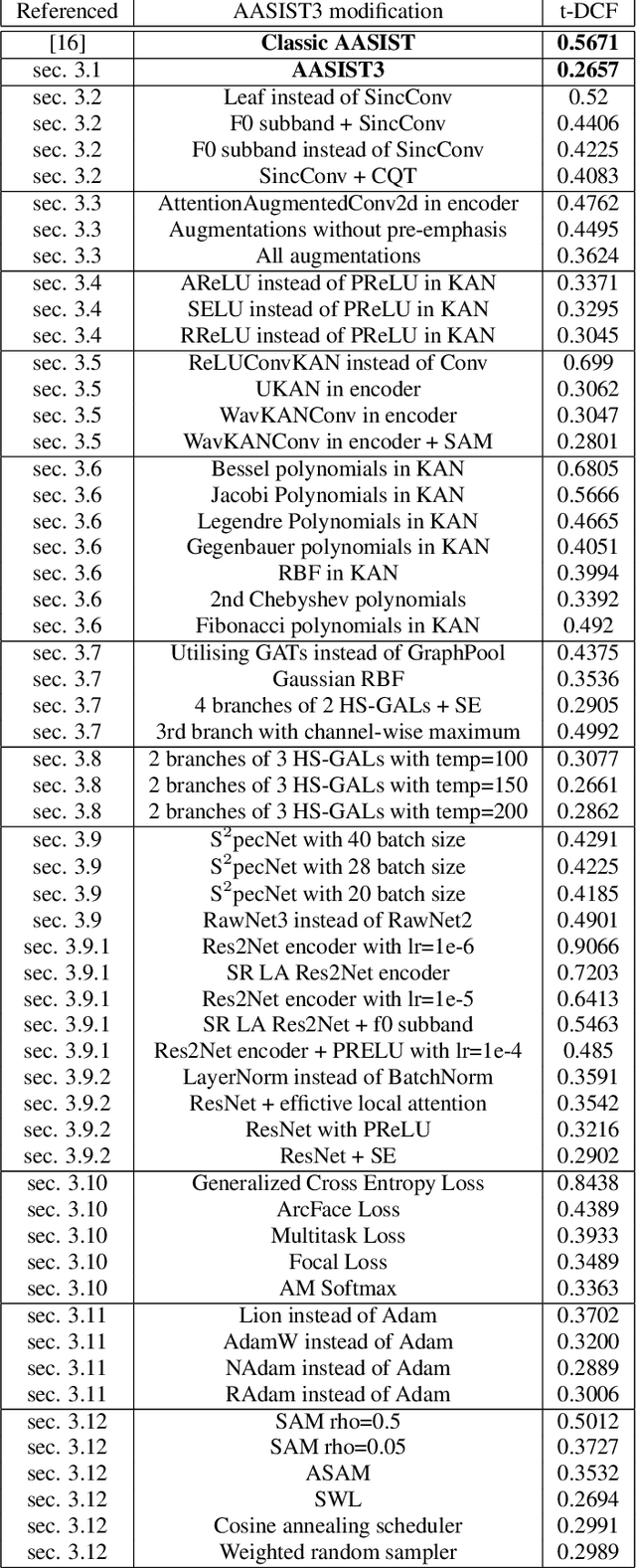
Automatic Speaker Verification (ASV) systems, which identify speakers based on their voice characteristics, have numerous applications, such as user authentication in financial transactions, exclusive access control in smart devices, and forensic fraud detection. However, the advancement of deep learning algorithms has enabled the generation of synthetic audio through Text-to-Speech (TTS) and Voice Conversion (VC) systems, exposing ASV systems to potential vulnerabilities. To counteract this, we propose a novel architecture named AASIST3. By enhancing the existing AASIST framework with Kolmogorov-Arnold networks, additional layers, encoders, and pre-emphasis techniques, AASIST3 achieves a more than twofold improvement in performance. It demonstrates minDCF results of 0.5357 in the closed condition and 0.1414 in the open condition, significantly enhancing the detection of synthetic voices and improving ASV security.
Certification of Speaker Recognition Models to Additive Perturbations
Apr 29, 2024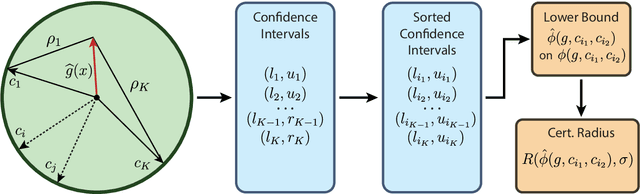
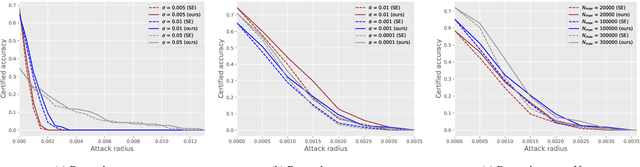
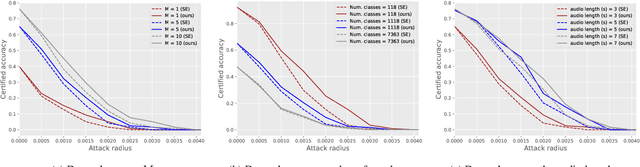
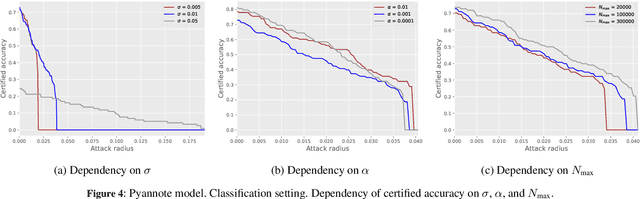
Speaker recognition technology is applied in various tasks ranging from personal virtual assistants to secure access systems. However, the robustness of these systems against adversarial attacks, particularly to additive perturbations, remains a significant challenge. In this paper, we pioneer applying robustness certification techniques to speaker recognition, originally developed for the image domain. In our work, we cover this gap by transferring and improving randomized smoothing certification techniques against norm-bounded additive perturbations for classification and few-shot learning tasks to speaker recognition. We demonstrate the effectiveness of these methods on VoxCeleb 1 and 2 datasets for several models. We expect this work to improve voice-biometry robustness, establish a new certification benchmark, and accelerate research of certification methods in the audio domain.