 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAASIST3: KAN-Enhanced AASIST Speech Deepfake Detection using SSL Features and Additional Regularization for the ASVspoof 2024 Challenge
Aug 30, 2024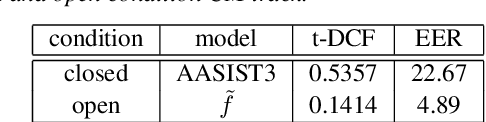

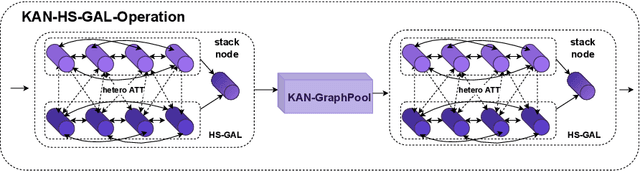
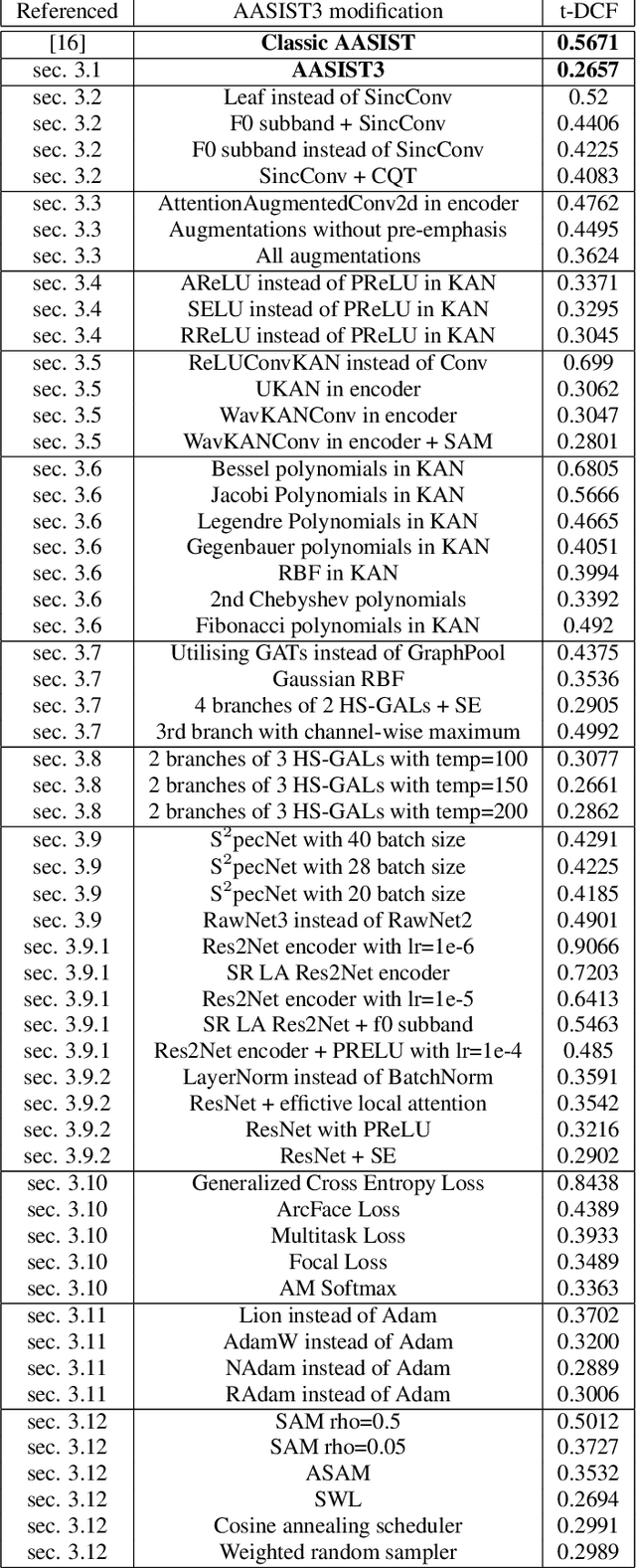
Automatic Speaker Verification (ASV) systems, which identify speakers based on their voice characteristics, have numerous applications, such as user authentication in financial transactions, exclusive access control in smart devices, and forensic fraud detection. However, the advancement of deep learning algorithms has enabled the generation of synthetic audio through Text-to-Speech (TTS) and Voice Conversion (VC) systems, exposing ASV systems to potential vulnerabilities. To counteract this, we propose a novel architecture named AASIST3. By enhancing the existing AASIST framework with Kolmogorov-Arnold networks, additional layers, encoders, and pre-emphasis techniques, AASIST3 achieves a more than twofold improvement in performance. It demonstrates minDCF results of 0.5357 in the closed condition and 0.1414 in the open condition, significantly enhancing the detection of synthetic voices and improving ASV security.