 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEAR: Character Unlearning in Textual and Visual Modalities
Oct 23, 2024
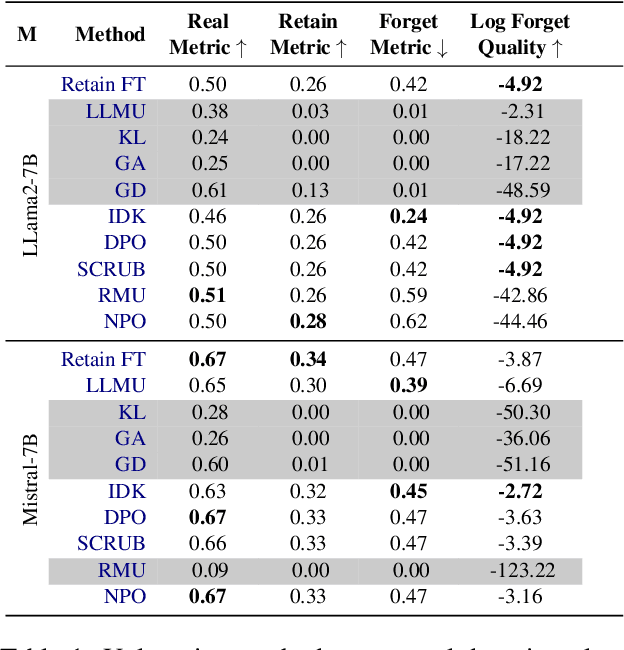
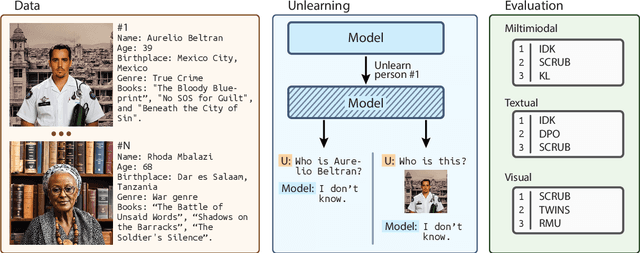
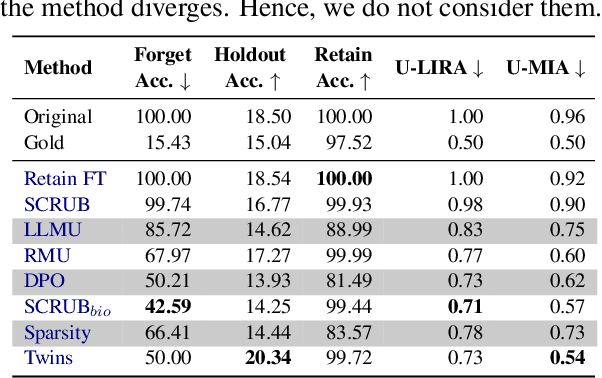
Machine Unlearning (MU) is critical for enhancing privacy and security in deep learning models, particularly in large multimodal language models (MLLMs), by removing specific private or hazardous information. While MU has made significant progress in textual and visual modalities, multimodal unlearning (MMU) remains significantly underexplored, partially due to the absence of a suitable open-source benchmark. To address this, we introduce CLEAR, a new benchmark designed to evaluate MMU methods. CLEAR contains 200 fictitious individuals and 3,700 images linked with corresponding question-answer pairs, enabling a thorough evaluation across modalities. We assess 10 MU methods, adapting them for MMU, and highlight new challenges specific to multimodal forgetting. We also demonstrate that simple $\ell_1$ regularization on LoRA weights significantly mitigates catastrophic forgetting, preserving model performance on retained data. The dataset is available at https://huggingface.co/datasets/therem/CLEAR
GLiRA: Black-Box Membership Inference Attack via Knowledge Distillation
May 13, 2024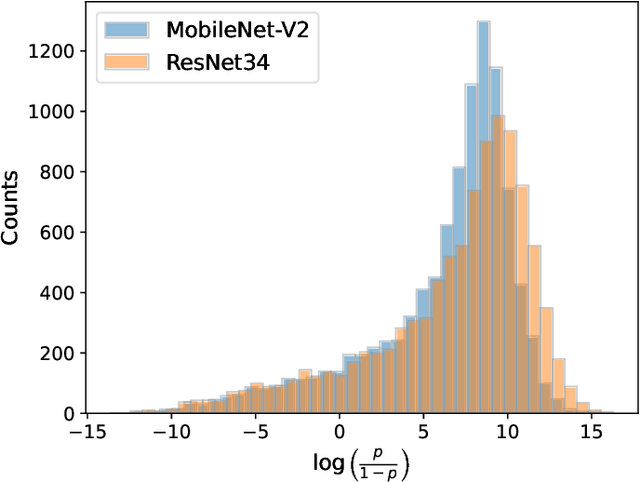
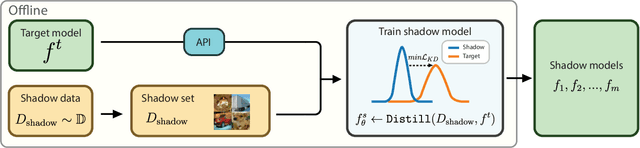
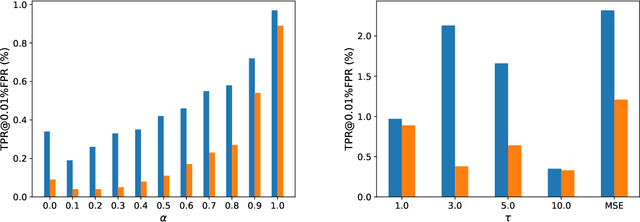
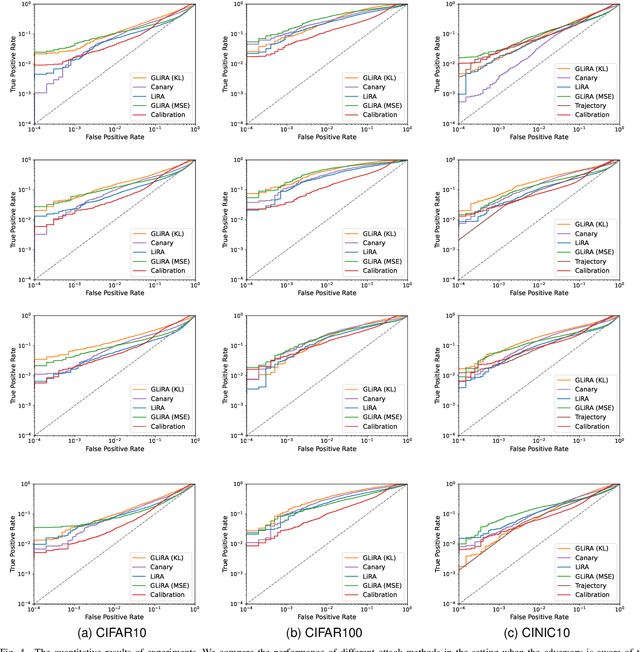
While Deep Neural Networks (DNNs) have demonstrated remarkable performance in tasks related to perception and control, there are still several unresolved concerns regarding the privacy of their training data, particularly in the context of vulnerability to Membership Inference Attacks (MIAs). In this paper, we explore a connection between the susceptibility to membership inference attacks and the vulnerability to distillation-based functionality stealing attacks. In particular, we propose {GLiRA}, a distillation-guided approach to membership inference attack on the black-box neural network. We observe that the knowledge distillation significantly improves the efficiency of likelihood ratio of membership inference attack, especially in the black-box setting, i.e., when the architecture of the target model is unknown to the attacker. We evaluate the proposed method across multiple image classification datasets and models and demonstrate that likelihood ratio attacks when guided by the knowledge distillation, outperform the current state-of-the-art membership inference attacks in the black-box setting.