 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpread them Apart: Towards Robust Watermarking of Generated Content
Feb 11, 2025Generative models that can produce realistic images have improved significantly in recent years. The quality of the generated content has increased drastically, so sometimes it is very difficult to distinguish between the real images and the generated ones. Such an improvement comes at a price of ethical concerns about the usage of the generative models: the users of generative models can improperly claim ownership of the generated content protected by a license. In this paper, we propose an approach to embed watermarks into the generated content to allow future detection of the generated content and identification of the user who generated it. The watermark is embedded during the inference of the model, so the proposed approach does not require the retraining of the latter. We prove that watermarks embedded are guaranteed to be robust against additive perturbations of a bounded magnitude. We apply our method to watermark diffusion models and show that it matches state-of-the-art watermarking schemes in terms of robustness to different types of synthetic watermark removal attacks.
GLiRA: Black-Box Membership Inference Attack via Knowledge Distillation
May 13, 2024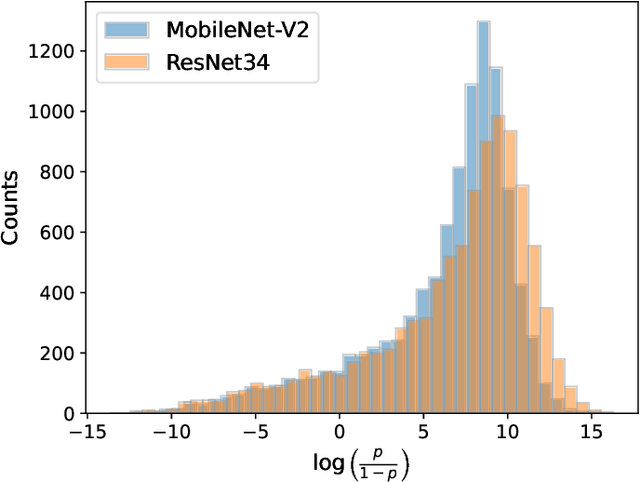
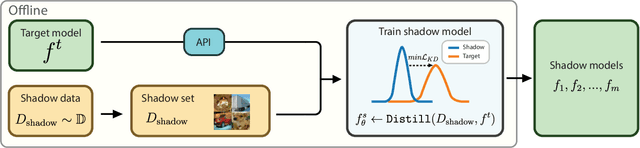
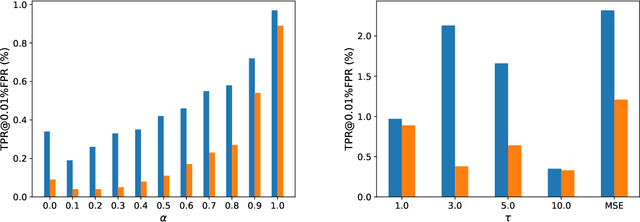
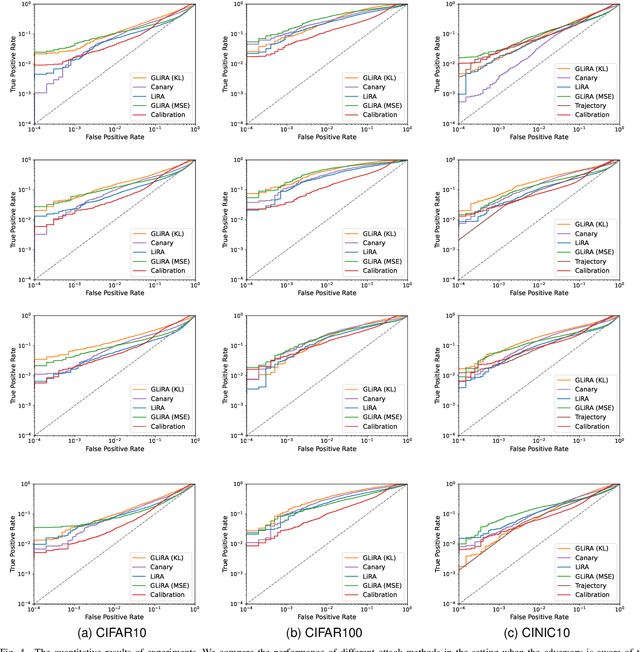
While Deep Neural Networks (DNNs) have demonstrated remarkable performance in tasks related to perception and control, there are still several unresolved concerns regarding the privacy of their training data, particularly in the context of vulnerability to Membership Inference Attacks (MIAs). In this paper, we explore a connection between the susceptibility to membership inference attacks and the vulnerability to distillation-based functionality stealing attacks. In particular, we propose {GLiRA}, a distillation-guided approach to membership inference attack on the black-box neural network. We observe that the knowledge distillation significantly improves the efficiency of likelihood ratio of membership inference attack, especially in the black-box setting, i.e., when the architecture of the target model is unknown to the attacker. We evaluate the proposed method across multiple image classification datasets and models and demonstrate that likelihood ratio attacks when guided by the knowledge distillation, outperform the current state-of-the-art membership inference attacks in the black-box setting.