 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReCache: Learning Budget-Aware Caching Schedules for Diffusion Models via REINFORCE
Jun 04, 2026Modern diffusion models generate high-quality images and videos, but their iterative denoising process makes inference expensive. Feature caching accelerates sampling by reusing or predicting intermediate activations across neighboring denoising steps, exploiting the redundancy of computations along the reverse trajectory. In this work, we focus on the caching schedule: selecting which denoising steps should be fully recomputed. Existing schedules are either fixed (e.g. uniform) or chosen adaptively from per-step error heuristics; in both cases, the actual compute cost is a side-effect of hand-tuned thresholds rather than a quantity the user can specify. We propose ReCache, which inverts this: given a target budget k, it learns the recomputation schedule that maximizes generation quality, turning compute into a directly controllable input. ReCache trains via policy gradients, sidestepping backpropagation through full diffusion inference, and uses no labelled data. Generations from uncached inference serve as matching targets, paired with a reward for generation quality. ReCache is compatible with any caching mechanism, including feature reuse and feature forecasting; for each mechanism, a single trained policy adapts across computational budgets at inference time. ReCache consistently outperforms scheduling baselines: under a $\times5.04$ FLOPs reduction on FLUX, it reduces LPIPS by 31% (from 0.456 to 0.316) compared to DiCache; on Wan 2.1 at a $\sim \times2.6$ speedup, it drops LPIPS by 65% (from 0.480 to 0.169) and boosts the VBench score by 7% (5.6 points, from 70.4 to 76.0) over uniform HiCache. Code is available at https://github.com/thecrazymage/ReCache.
SHIFT: Steering Hidden Intermediates in Flow Transformers
Apr 10, 2026Diffusion models have become leading approaches for high-fidelity image generation. Recent DiT-based diffusion models, in particular, achieve strong prompt adherence while producing high-quality samples. We propose SHIFT, a simple but effective and lightweight framework for concept removal in DiT diffusion models via targeted manipulation of intermediate activations at inference time, inspired by activation steering in large language models. SHIFT learns steering vectors that are dynamically applied to selected layers and timesteps to suppress unwanted visual concepts while preserving the prompt's remaining content and overall image quality. Beyond suppression, the same mechanism can shift generations into a desired \emph{style domain} or bias samples toward adding or changing target objects. We demonstrate that SHIFT provides effective and flexible control over DiT generation across diverse prompts and targets without time-consuming retraining.
OrthoFuse: Training-free Riemannian Fusion of Orthogonal Style-Concept Adapters for Diffusion Models
Apr 06, 2026In a rapidly growing field of model training there is a constant practical interest in parameter-efficient fine-tuning and various techniques that use a small amount of training data to adapt the model to a narrow task. However, there is an open question: how to combine several adapters tuned for different tasks into one which is able to yield adequate results on both tasks? Specifically, merging subject and style adapters for generative models remains unresolved. In this paper we seek to show that in the case of orthogonal fine-tuning (OFT), we can use structured orthogonal parametrization and its geometric properties to get the formulas for training-free adapter merging. In particular, we derive the structure of the manifold formed by the recently proposed Group-and-Shuffle ($\mathcal{GS}$) orthogonal matrices, and obtain efficient formulas for the geodesics approximation between two points. Additionally, we propose a $\text{spectra restoration}$ transform that restores spectral properties of the merged adapter for higher-quality fusion. We conduct experiments in subject-driven generation tasks showing that our technique to merge two $\mathcal{GS}$ orthogonal matrices is capable of uniting concept and style features of different adapters. To the best of our knowledge, this is the first training-free method for merging multiplicative orthogonal adapters. Code is available via the $\href{https://github.com/ControlGenAI/OrthoFuse}{link}$.
ATATA: One Algorithm to Align Them All
Jan 16, 2026We suggest a new multi-modal algorithm for joint inference of paired structurally aligned samples with Rectified Flow models. While some existing methods propose a codependent generation process, they do not view the problem of joint generation from a structural alignment perspective. Recent work uses Score Distillation Sampling to generate aligned 3D models, but SDS is known to be time-consuming, prone to mode collapse, and often provides cartoonish results. By contrast, our suggested approach relies on the joint transport of a segment in the sample space, yielding faster computation at inference time. Our approach can be built on top of an arbitrary Rectified Flow model operating on the structured latent space. We show the applicability of our method to the domains of image, video, and 3D shape generation using state-of-the-art baselines and evaluate it against both editing-based and joint inference-based competing approaches. We demonstrate a high degree of structural alignment for the sample pairs obtained with our method and a high visual quality of the samples. Our method improves the state-of-the-art for image and video generation pipelines. For 3D generation, it is able to show comparable quality while working orders of magnitude faster.
RiemannLoRA: A Unified Riemannian Framework for Ambiguity-Free LoRA Optimization
Jul 16, 2025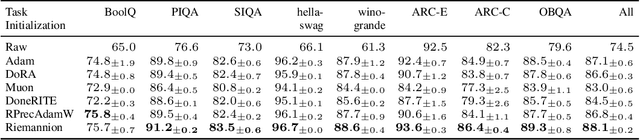
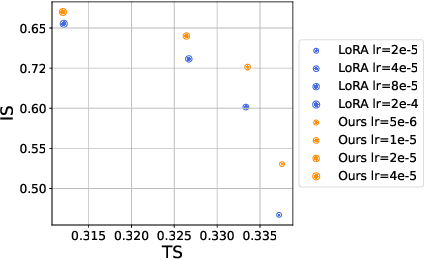


Low-Rank Adaptation (LoRA) has become a widely adopted standard for parameter-efficient fine-tuning of large language models (LLMs), significantly reducing memory and computational demands. However, challenges remain, including finding optimal initialization strategies or mitigating overparametrization in low-rank matrix factorization. In this work, we propose a novel approach that addresses both of the challenges simultaneously within a unified framework. Our method treats a set of fixed-rank LoRA matrices as a smooth manifold. Considering adapters as elements on this manifold removes overparametrization, while determining the direction of the fastest loss decrease along the manifold provides initialization. Special care is taken to obtain numerically stable and computationally efficient implementation of our method, using best practices from numerical linear algebra and Riemannian optimization. Experimental results on LLM and diffusion model architectures demonstrate that RiemannLoRA consistently improves both convergence speed and final performance over standard LoRA and its state-of-the-art modifications.
Heeding the Inner Voice: Aligning ControlNet Training via Intermediate Features Feedback
Jul 03, 2025Despite significant progress in text-to-image diffusion models, achieving precise spatial control over generated outputs remains challenging. ControlNet addresses this by introducing an auxiliary conditioning module, while ControlNet++ further refines alignment through a cycle consistency loss applied only to the final denoising steps. However, this approach neglects intermediate generation stages, limiting its effectiveness. We propose InnerControl, a training strategy that enforces spatial consistency across all diffusion steps. Our method trains lightweight convolutional probes to reconstruct input control signals (e.g., edges, depth) from intermediate UNet features at every denoising step. These probes efficiently extract signals even from highly noisy latents, enabling pseudo ground truth controls for training. By minimizing the discrepancy between predicted and target conditions throughout the entire diffusion process, our alignment loss improves both control fidelity and generation quality. Combined with established techniques like ControlNet++, InnerControl achieves state-of-the-art performance across diverse conditioning methods (e.g., edges, depth).
Inverse-and-Edit: Effective and Fast Image Editing by Cycle Consistency Models
Jun 23, 2025Recent advances in image editing with diffusion models have achieved impressive results, offering fine-grained control over the generation process. However, these methods are computationally intensive because of their iterative nature. While distilled diffusion models enable faster inference, their editing capabilities remain limited, primarily because of poor inversion quality. High-fidelity inversion and reconstruction are essential for precise image editing, as they preserve the structural and semantic integrity of the source image. In this work, we propose a novel framework that enhances image inversion using consistency models, enabling high-quality editing in just four steps. Our method introduces a cycle-consistency optimization strategy that significantly improves reconstruction accuracy and enables a controllable trade-off between editability and content preservation. We achieve state-of-the-art performance across various image editing tasks and datasets, demonstrating that our method matches or surpasses full-step diffusion models while being substantially more efficient. The code of our method is available on GitHub at https://github.com/ControlGenAI/Inverse-and-Edit.
ImageReFL: Balancing Quality and Diversity in Human-Aligned Diffusion Models
May 28, 2025Recent advances in diffusion models have led to impressive image generation capabilities, but aligning these models with human preferences remains challenging. Reward-based fine-tuning using models trained on human feedback improves alignment but often harms diversity, producing less varied outputs. In this work, we address this trade-off with two contributions. First, we introduce \textit{combined generation}, a novel sampling strategy that applies a reward-tuned diffusion model only in the later stages of the generation process, while preserving the base model for earlier steps. This approach mitigates early-stage overfitting and helps retain global structure and diversity. Second, we propose \textit{ImageReFL}, a fine-tuning method that improves image diversity with minimal loss in quality by training on real images and incorporating multiple regularizers, including diffusion and ReFL losses. Our approach outperforms conventional reward tuning methods on standard quality and diversity metrics. A user study further confirms that our method better balances human preference alignment and visual diversity. The source code can be found at https://github.com/ControlGenAI/ImageReFL .
FastFace: Tuning Identity Preservation in Distilled Diffusion via Guidance and Attention
May 28, 2025In latest years plethora of identity-preserving adapters for a personalized generation with diffusion models have been released. Their main disadvantage is that they are dominantly trained jointly with base diffusion models, which suffer from slow multi-step inference. This work aims to tackle the challenge of training-free adaptation of pretrained ID-adapters to diffusion models accelerated via distillation - through careful re-design of classifier-free guidance for few-step stylistic generation and attention manipulation mechanisms in decoupled blocks to improve identity similarity and fidelity, we propose universal FastFace framework. Additionally, we develop a disentangled public evaluation protocol for id-preserving adapters.
DreamBoothDPO: Improving Personalized Generation using Direct Preference Optimization
May 27, 2025Personalized diffusion models have shown remarkable success in Text-to-Image (T2I) generation by enabling the injection of user-defined concepts into diverse contexts. However, balancing concept fidelity with contextual alignment remains a challenging open problem. In this work, we propose an RL-based approach that leverages the diverse outputs of T2I models to address this issue. Our method eliminates the need for human-annotated scores by generating a synthetic paired dataset for DPO-like training using external quality metrics. These better-worse pairs are specifically constructed to improve both concept fidelity and prompt adherence. Moreover, our approach supports flexible adjustment of the trade-off between image fidelity and textual alignment. Through multi-step training, our approach outperforms a naive baseline in convergence speed and output quality. We conduct extensive qualitative and quantitative analysis, demonstrating the effectiveness of our method across various architectures and fine-tuning techniques. The source code can be found at https://github.com/ControlGenAI/DreamBoothDPO.