 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRiemannLoRA: A Unified Riemannian Framework for Ambiguity-Free LoRA Optimization
Jul 16, 2025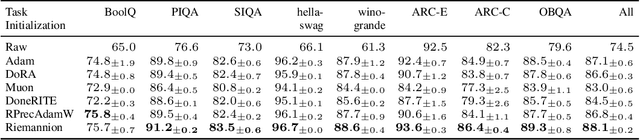
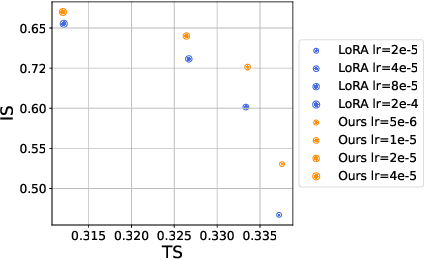


Low-Rank Adaptation (LoRA) has become a widely adopted standard for parameter-efficient fine-tuning of large language models (LLMs), significantly reducing memory and computational demands. However, challenges remain, including finding optimal initialization strategies or mitigating overparametrization in low-rank matrix factorization. In this work, we propose a novel approach that addresses both of the challenges simultaneously within a unified framework. Our method treats a set of fixed-rank LoRA matrices as a smooth manifold. Considering adapters as elements on this manifold removes overparametrization, while determining the direction of the fastest loss decrease along the manifold provides initialization. Special care is taken to obtain numerically stable and computationally efficient implementation of our method, using best practices from numerical linear algebra and Riemannian optimization. Experimental results on LLM and diffusion model architectures demonstrate that RiemannLoRA consistently improves both convergence speed and final performance over standard LoRA and its state-of-the-art modifications.
Beyond Fine-Tuning: A Systematic Study of Sampling Techniques in Personalized Image Generation
Feb 09, 2025



Personalized text-to-image generation aims to create images tailored to user-defined concepts and textual descriptions. Balancing the fidelity of the learned concept with its ability for generation in various contexts presents a significant challenge. Existing methods often address this through diverse fine-tuning parameterizations and improved sampling strategies that integrate superclass trajectories during the diffusion process. While improved sampling offers a cost-effective, training-free solution for enhancing fine-tuned models, systematic analyses of these methods remain limited. Current approaches typically tie sampling strategies with fixed fine-tuning configurations, making it difficult to isolate their impact on generation outcomes. To address this issue, we systematically analyze sampling strategies beyond fine-tuning, exploring the impact of concept and superclass trajectories on the results. Building on this analysis, we propose a decision framework evaluating text alignment, computational constraints, and fidelity objectives to guide strategy selection. It integrates with diverse architectures and training approaches, systematically optimizing concept preservation, prompt adherence, and resource efficiency. The source code can be found at https://github.com/ControlGenAI/PersonGenSampler.
Group and Shuffle: Efficient Structured Orthogonal Parametrization
Jun 14, 2024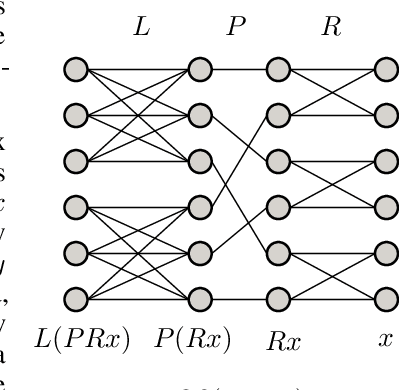

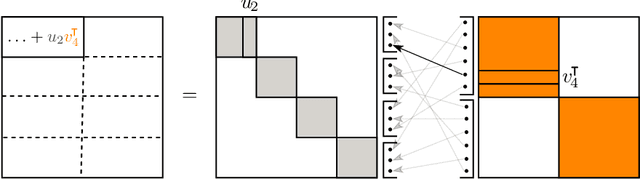

The increasing size of neural networks has led to a growing demand for methods of efficient fine-tuning. Recently, an orthogonal fine-tuning paradigm was introduced that uses orthogonal matrices for adapting the weights of a pretrained model. In this paper, we introduce a new class of structured matrices, which unifies and generalizes structured classes from previous works. We examine properties of this class and build a structured orthogonal parametrization upon it. We then use this parametrization to modify the orthogonal fine-tuning framework, improving parameter and computational efficiency. We empirically validate our method on different domains, including adapting of text-to-image diffusion models and downstream task fine-tuning in language modeling. Additionally, we adapt our construction for orthogonal convolutions and conduct experiments with 1-Lipschitz neural networks.
vox2vec: A Framework for Self-supervised Contrastive Learning of Voxel-level Representations in Medical Images
Jul 27, 2023This paper introduces vox2vec - a contrastive method for self-supervised learning (SSL) of voxel-level representations. vox2vec representations are modeled by a Feature Pyramid Network (FPN): a voxel representation is a concatenation of the corresponding feature vectors from different pyramid levels. The FPN is pre-trained to produce similar representations for the same voxel in different augmented contexts and distinctive representations for different voxels. This results in unified multi-scale representations that capture both global semantics (e.g., body part) and local semantics (e.g., different small organs or healthy versus tumor tissue). We use vox2vec to pre-train a FPN on more than 6500 publicly available computed tomography images. We evaluate the pre-trained representations by attaching simple heads on top of them and training the resulting models for 22 segmentation tasks. We show that vox2vec outperforms existing medical imaging SSL techniques in three evaluation setups: linear and non-linear probing and end-to-end fine-tuning. Moreover, a non-linear head trained on top of the frozen vox2vec representations achieves competitive performance with the FPN trained from scratch while having 50 times fewer trainable parameters. The code is available at https://github.com/mishgon/vox2vec .
Raindrops on Windshield: Dataset and Lightweight Gradient-Based Detection Algorithm
Apr 11, 2021


Autonomous vehicles use cameras as one of the primary sources of information about the environment. Adverse weather conditions such as raindrops, snow, mud, and others, can lead to various image artifacts. Such artifacts significantly degrade the quality and reliability of the obtained visual data and can lead to accidents if they are not detected in time. This paper presents ongoing work on a new dataset for training and assessing vision algorithms' performance for different tasks of image artifacts detection on either camera lens or windshield. At the moment, we present a publicly available set of images containing $8190$ images, of which $3390$ contain raindrops. Images are annotated with the binary mask representing areas with raindrops. We demonstrate the applicability of the dataset in the problems of raindrops presence detection and raindrop region segmentation. To augment the data, we also propose an algorithm for data augmentation which allows the generation of synthetic raindrops on images. Apart from the dataset, we present a novel gradient-based algorithm for raindrop presence detection in a video sequence. The experimental evaluation proves that the algorithm reliably detects raindrops. Moreover, compared with the state-of-the-art cross-correlation-based algorithm \cite{Einecke2014}, the proposed algorithm showed a higher quality of raindrop presence detection and image processing speed, making it applicable for the self-check procedure of real autonomous systems. The dataset is available at \href{https://github.com/EvoCargo/RaindropsOnWindshield}{$github.com/EvoCargo/RaindropsOnWindshield$}.