 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTight and Efficient Upper Bound on Spectral Norm of Convolutional Layers
Sep 18, 2024Controlling the spectral norm of the Jacobian matrix, which is related to the convolution operation, has been shown to improve generalization, training stability and robustness in CNNs. Existing methods for computing the norm either tend to overestimate it or their performance may deteriorate quickly with increasing the input and kernel sizes. In this paper, we demonstrate that the tensor version of the spectral norm of a four-dimensional convolution kernel, up to a constant factor, serves as an upper bound for the spectral norm of the Jacobian matrix associated with the convolution operation. This new upper bound is independent of the input image resolution, differentiable and can be efficiently calculated during training. Through experiments, we demonstrate how this new bound can be used to improve the performance of convolutional architectures.
Group and Shuffle: Efficient Structured Orthogonal Parametrization
Jun 14, 2024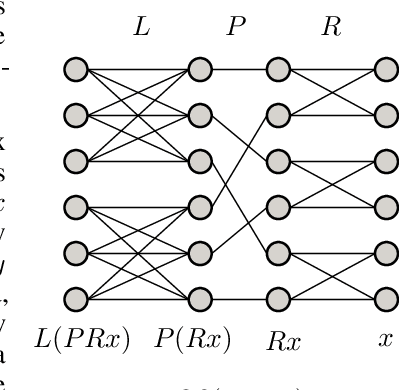

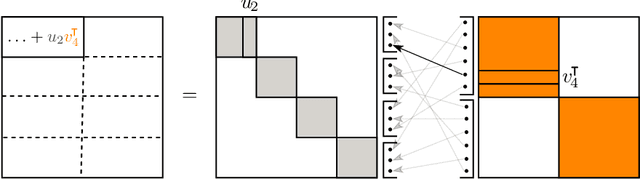

The increasing size of neural networks has led to a growing demand for methods of efficient fine-tuning. Recently, an orthogonal fine-tuning paradigm was introduced that uses orthogonal matrices for adapting the weights of a pretrained model. In this paper, we introduce a new class of structured matrices, which unifies and generalizes structured classes from previous works. We examine properties of this class and build a structured orthogonal parametrization upon it. We then use this parametrization to modify the orthogonal fine-tuning framework, improving parameter and computational efficiency. We empirically validate our method on different domains, including adapting of text-to-image diffusion models and downstream task fine-tuning in language modeling. Additionally, we adapt our construction for orthogonal convolutions and conduct experiments with 1-Lipschitz neural networks.