 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Central Limit Theorem and Bootstrap Approximations for Linear Stochastic Approximation
Oct 14, 2025In this paper, we refine the Berry-Esseen bounds for the multivariate normal approximation of Polyak-Ruppert averaged iterates arising from the linear stochastic approximation (LSA) algorithm with decreasing step size. We consider the normal approximation by the Gaussian distribution with covariance matrix predicted by the Polyak-Juditsky central limit theorem and establish the rate up to order $n^{-1/3}$ in convex distance, where $n$ is the number of samples used in the algorithm. We also prove a non-asymptotic validity of the multiplier bootstrap procedure for approximating the distribution of the rescaled error of the averaged LSA estimator. We establish approximation rates of order up to $1/\sqrt{n}$ for the latter distribution, which significantly improves upon the previous results obtained by Samsonov et al. (2024).
Gaussian Approximation for Two-Timescale Linear Stochastic Approximation
Aug 11, 2025In this paper, we establish non-asymptotic bounds for accuracy of normal approximation for linear two-timescale stochastic approximation (TTSA) algorithms driven by martingale difference or Markov noise. Focusing on both the last iterate and Polyak-Ruppert averaging regimes, we derive bounds for normal approximation in terms of the convex distance between probability distributions. Our analysis reveals a non-trivial interaction between the fast and slow timescales: the normal approximation rate for the last iterate improves as the timescale separation increases, while it decreases in the Polyak-Ruppert averaged setting. We also provide the high-order moment bounds for the error of linear TTSA algorithm, which may be of independent interest.
Tight Bounds for Schrödinger Potential Estimation in Unpaired Image-to-Image Translation Problems
Aug 10, 2025



Modern methods of generative modelling and unpaired image-to-image translation based on Schr\"odinger bridges and stochastic optimal control theory aim to transform an initial density to a target one in an optimal way. In the present paper, we assume that we only have access to i.i.d. samples from initial and final distributions. This makes our setup suitable for both generative modelling and unpaired image-to-image translation. Relying on the stochastic optimal control approach, we choose an Ornstein-Uhlenbeck process as the reference one and estimate the corresponding Schr\"odinger potential. Introducing a risk function as the Kullback-Leibler divergence between couplings, we derive tight bounds on generalization ability of an empirical risk minimizer in a class of Schr\"odinger potentials including Gaussian mixtures. Thanks to the mixing properties of the Ornstein-Uhlenbeck process, we almost achieve fast rates of convergence up to some logarithmic factors in favourable scenarios. We also illustrate performance of the suggested approach with numerical experiments.
High-Order Error Bounds for Markovian LSA with Richardson-Romberg Extrapolation
Aug 07, 2025In this paper, we study the bias and high-order error bounds of the Linear Stochastic Approximation (LSA) algorithm with Polyak-Ruppert (PR) averaging under Markovian noise. We focus on the version of the algorithm with constant step size $\alpha$ and propose a novel decomposition of the bias via a linearization technique. We analyze the structure of the bias and show that the leading-order term is linear in $\alpha$ and cannot be eliminated by PR averaging. To address this, we apply the Richardson-Romberg (RR) extrapolation procedure, which effectively cancels the leading bias term. We derive high-order moment bounds for the RR iterates and show that the leading error term aligns with the asymptotically optimal covariance matrix of the vanilla averaged LSA iterates.
On the Upper Bounds for the Matrix Spectral Norm
Jun 18, 2025We consider the problem of estimating the spectral norm of a matrix using only matrix-vector products. We propose a new Counterbalance estimator that provides upper bounds on the norm and derive probabilistic guarantees on its underestimation. Compared to standard approaches such as the power method, the proposed estimator produces significantly tighter upper bounds in both synthetic and real-world settings. Our method is especially effective for matrices with fast-decaying spectra, such as those arising in deep learning and inverse problems.
Accelerating Nash Learning from Human Feedback via Mirror Prox
May 26, 2025Traditional Reinforcement Learning from Human Feedback (RLHF) often relies on reward models, frequently assuming preference structures like the Bradley-Terry model, which may not accurately capture the complexities of real human preferences (e.g., intransitivity). Nash Learning from Human Feedback (NLHF) offers a more direct alternative by framing the problem as finding a Nash equilibrium of a game defined by these preferences. In this work, we introduce Nash Mirror Prox ($\mathtt{Nash-MP}$), an online NLHF algorithm that leverages the Mirror Prox optimization scheme to achieve fast and stable convergence to the Nash equilibrium. Our theoretical analysis establishes that Nash-MP exhibits last-iterate linear convergence towards the $\beta$-regularized Nash equilibrium. Specifically, we prove that the KL-divergence to the optimal policy decreases at a rate of order $(1+2\beta)^{-N/2}$, where $N$ is a number of preference queries. We further demonstrate last-iterate linear convergence for the exploitability gap and uniformly for the span semi-norm of log-probabilities, with all these rates being independent of the size of the action space. Furthermore, we propose and analyze an approximate version of Nash-MP where proximal steps are estimated using stochastic policy gradients, making the algorithm closer to applications. Finally, we detail a practical implementation strategy for fine-tuning large language models and present experiments that demonstrate its competitive performance and compatibility with existing methods.
Statistical inference for Linear Stochastic Approximation with Markovian Noise
May 25, 2025In this paper we derive non-asymptotic Berry-Esseen bounds for Polyak-Ruppert averaged iterates of the Linear Stochastic Approximation (LSA) algorithm driven by the Markovian noise. Our analysis yields $\mathcal{O}(n^{-1/4})$ convergence rates to the Gaussian limit in the Kolmogorov distance. We further establish the non-asymptotic validity of a multiplier block bootstrap procedure for constructing the confidence intervals, guaranteeing consistent inference under Markovian sampling. Our work provides the first non-asymptotic guarantees on the rate of convergence of bootstrap-based confidence intervals for stochastic approximation with Markov noise. Moreover, we recover the classical rate of order $\mathcal{O}(n^{-1/8})$ up to logarithmic factors for estimating the asymptotic variance of the iterates of the LSA algorithm.
A note on concentration inequalities for the overlapped batch mean variance estimators for Markov chains
May 13, 2025In this paper, we study the concentration properties of quadratic forms associated with Markov chains using the martingale decomposition method introduced by Atchad\'e and Cattaneo (2014). In particular, we derive concentration inequalities for the overlapped batch mean (OBM) estimators of the asymptotic variance for uniformly geometrically ergodic Markov chains. Our main result provides an explicit control of the $p$-th moment of the difference between the OBM estimator and the asymptotic variance of the Markov chain with explicit dependence upon $p$ and mixing time of the underlying Markov chain.
Improving GFlowNets with Monte Carlo Tree Search
Jun 19, 2024Generative Flow Networks (GFlowNets) treat sampling from distributions over compositional discrete spaces as a sequential decision-making problem, training a stochastic policy to construct objects step by step. Recent studies have revealed strong connections between GFlowNets and entropy-regularized reinforcement learning. Building on these insights, we propose to enhance planning capabilities of GFlowNets by applying Monte Carlo Tree Search (MCTS). Specifically, we show how the MENTS algorithm (Xiao et al., 2019) can be adapted for GFlowNets and used during both training and inference. Our experiments demonstrate that this approach improves the sample efficiency of GFlowNet training and the generation fidelity of pre-trained GFlowNet models.
Group and Shuffle: Efficient Structured Orthogonal Parametrization
Jun 14, 2024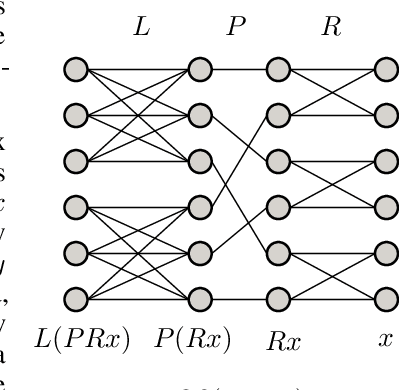

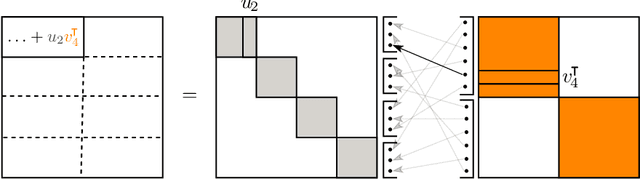

The increasing size of neural networks has led to a growing demand for methods of efficient fine-tuning. Recently, an orthogonal fine-tuning paradigm was introduced that uses orthogonal matrices for adapting the weights of a pretrained model. In this paper, we introduce a new class of structured matrices, which unifies and generalizes structured classes from previous works. We examine properties of this class and build a structured orthogonal parametrization upon it. We then use this parametrization to modify the orthogonal fine-tuning framework, improving parameter and computational efficiency. We empirically validate our method on different domains, including adapting of text-to-image diffusion models and downstream task fine-tuning in language modeling. Additionally, we adapt our construction for orthogonal convolutions and conduct experiments with 1-Lipschitz neural networks.