 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchrödinger bridge problem via empirical risk minimization
Feb 09, 2026We study the Schrödinger bridge problem when the endpoint distributions are available only through samples. Classical computational approaches estimate Schrödinger potentials via Sinkhorn iterations on empirical measures and then construct a time-inhomogeneous drift by differentiating a kernel-smoothed dual solution. In contrast, we propose a learning-theoretic route: we rewrite the Schrödinger system in terms of a single positive transformed potential that satisfies a nonlinear fixed-point equation and estimate this potential by empirical risk minimization over a function class. We establish uniform concentration of the empirical risk around its population counterpart under sub-Gaussian assumptions on the reference kernel and terminal density. We plug the learned potential into a stochastic control representation of the bridge to generate samples. We illustrate performance of the suggested approach with numerical experiments.
Implicit score matching meets denoising score matching: improved rates of convergence and log-density Hessian estimation
Dec 30, 2025We study the problem of estimating the score function using both implicit score matching and denoising score matching. Assuming that the data distribution exhibiting a low-dimensional structure, we prove that implicit score matching is able not only to adapt to the intrinsic dimension, but also to achieve the same rates of convergence as denoising score matching in terms of the sample size. Furthermore, we demonstrate that both methods allow us to estimate log-density Hessians without the curse of dimensionality by simple differentiation. This justifies convergence of ODE-based samplers for generative diffusion models. Our approach is based on Gagliardo-Nirenberg-type inequalities relating weighted $L^2$-norms of smooth functions and their derivatives.
Simultaneous Approximation of the Score Function and Its Derivatives by Deep Neural Networks
Dec 29, 2025We present a theory for simultaneous approximation of the score function and its derivatives, enabling the handling of data distributions with low-dimensional structure and unbounded support. Our approximation error bounds match those in the literature while relying on assumptions that relax the usual bounded support requirement. Crucially, our bounds are free from the curse of dimensionality. Moreover, we establish approximation guarantees for derivatives of any prescribed order, extending beyond the commonly considered first-order setting.
Approximation Capabilities of Feedforward Neural Networks with GELU Activations
Dec 25, 2025We derive an approximation error bound that holds simultaneously for a function and all its derivatives up to any prescribed order. The bounds apply to elementary functions, including multivariate polynomials, the exponential function, and the reciprocal function, and are obtained using feedforward neural networks with the Gaussian Error Linear Unit (GELU) activation. In addition, we report the network size, weight magnitudes, and behavior at infinity. Our analysis begins with a constructive approximation of multiplication, where we prove the simultaneous validity of error bounds over domains of increasing size for a given approximator. Leveraging this result, we obtain approximation guarantees for division and the exponential function, ensuring that all higher-order derivatives of the resulting approximators remain globally bounded.
Tight Bounds for Schrödinger Potential Estimation in Unpaired Image-to-Image Translation Problems
Aug 10, 2025



Modern methods of generative modelling and unpaired image-to-image translation based on Schr\"odinger bridges and stochastic optimal control theory aim to transform an initial density to a target one in an optimal way. In the present paper, we assume that we only have access to i.i.d. samples from initial and final distributions. This makes our setup suitable for both generative modelling and unpaired image-to-image translation. Relying on the stochastic optimal control approach, we choose an Ornstein-Uhlenbeck process as the reference one and estimate the corresponding Schr\"odinger potential. Introducing a risk function as the Kullback-Leibler divergence between couplings, we derive tight bounds on generalization ability of an empirical risk minimizer in a class of Schr\"odinger potentials including Gaussian mixtures. Thanks to the mixing properties of the Ornstein-Uhlenbeck process, we almost achieve fast rates of convergence up to some logarithmic factors in favourable scenarios. We also illustrate performance of the suggested approach with numerical experiments.
Dimension-free bounds in high-dimensional linear regression via error-in-operator approach
Feb 21, 2025We consider a problem of high-dimensional linear regression with random design. We suggest a novel approach referred to as error-in-operator which does not estimate the design covariance $\Sigma$ directly but incorporates it into empirical risk minimization. We provide an expansion of the excess prediction risk and derive non-asymptotic dimension-free bounds on the leading term and the remainder. This helps us to show that auxiliary variables do not increase the effective dimension of the problem, provided that parameters of the procedure are tuned properly. We also discuss computational aspects of our method and illustrate its performance with numerical experiments.
Generalization error bound for denoising score matching under relaxed manifold assumption
Feb 19, 2025We examine theoretical properties of the denoising score matching estimate. We model the density of observations with a nonparametric Gaussian mixture. We significantly relax the standard manifold assumption allowing the samples step away from the manifold. At the same time, we are still able to leverage a nice distribution structure. We derive non-asymptotic bounds on the approximation and generalization errors of the denoising score matching estimate. The rates of convergence are determined by the intrinsic dimension. Furthermore, our bounds remain valid even if we allow the ambient dimension grow polynomially with the sample size.
Score-based change point detection via tracking the best of infinitely many experts
Aug 26, 2024



We suggest a novel algorithm for online change point detection based on sequential score function estimation and tracking the best expert approach. The core of the procedure is a version of the fixed share forecaster for the case of infinite number of experts and quadratic loss functions. The algorithm shows a promising performance in numerical experiments on artificial and real-world data sets. We also derive new upper bounds on the dynamic regret of the fixed share forecaster with varying parameter, which are of independent interest.
Dimension-free Structured Covariance Estimation
Feb 15, 2024Given a sample of i.i.d. high-dimensional centered random vectors, we consider a problem of estimation of their covariance matrix $\Sigma$ with an additional assumption that $\Sigma$ can be represented as a sum of a few Kronecker products of smaller matrices. Under mild conditions, we derive the first non-asymptotic dimension-free high-probability bound on the Frobenius distance between $\Sigma$ and a widely used penalized permuted least squares estimate. Because of the hidden structure, the established rate of convergence is faster than in the standard covariance estimation problem.
Breaking the Heavy-Tailed Noise Barrier in Stochastic Optimization Problems
Nov 07, 2023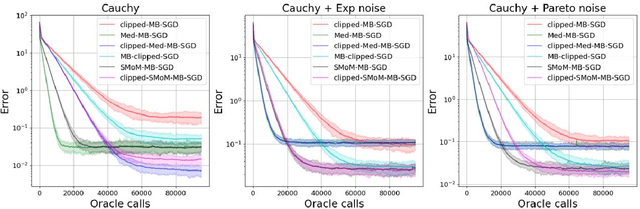
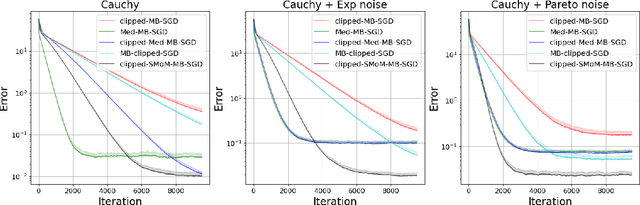
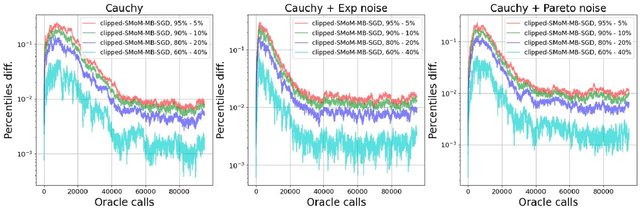
We consider stochastic optimization problems with heavy-tailed noise with structured density. For such problems, we show that it is possible to get faster rates of convergence than $\mathcal{O}(K^{-2(\alpha - 1)/\alpha})$, when the stochastic gradients have finite moments of order $\alpha \in (1, 2]$. In particular, our analysis allows the noise norm to have an unbounded expectation. To achieve these results, we stabilize stochastic gradients, using smoothed medians of means. We prove that the resulting estimates have negligible bias and controllable variance. This allows us to carefully incorporate them into clipped-SGD and clipped-SSTM and derive new high-probability complexity bounds in the considered setup.