 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOPE: Smooth Convex Optimization for Planned Evolution of Deformable Linear Objects
Jan 27, 2026We present SCOPE, a fast and efficient framework for modeling and manipulating deformable linear objects (DLOs). Unlike conventional energy-based approaches, SCOPE leverages convex approximations to significantly reduce computational cost while maintaining smooth and physically plausible deformations. This trade-off between speed and accuracy makes the method particularly suitable for applications requiring real-time or near-real-time response. The effectiveness of the proposed framework is demonstrated through comprehensive simulation experiments, highlighting its ability to generate smooth shape trajectories under geometric and length constraints.
Quantum-Inspired Episode Selection for Monte Carlo Reinforcement Learning via QUBO Optimization
Jan 24, 2026Monte Carlo (MC) reinforcement learning suffers from high sample complexity, especially in environments with sparse rewards, large state spaces, and correlated trajectories. We address these limitations by reformulating episode selection as a Quadratic Unconstrained Binary Optimization (QUBO) problem and solving it with quantum-inspired samplers. Our method, MC+QUBO, integrates a combinatorial filtering step into standard MC policy evaluation: from each batch of trajectories, we select a subset that maximizes cumulative reward while promoting state-space coverage. This selection is encoded as a QUBO, where linear terms favor high-reward episodes and quadratic terms penalize redundancy. We explore both Simulated Quantum Annealing (SQA) and Simulated Bifurcation (SB) as black-box solvers within this framework. Experiments in a finite-horizon GridWorld demonstrate that MC+QUBO outperforms vanilla MC in convergence speed and final policy quality, highlighting the potential of quantum-inspired optimization as a decision-making subroutine in reinforcement learning.
Gradient-Free Approaches is a Key to an Efficient Interaction with Markovian Stochasticity
Jan 03, 2026This paper deals with stochastic optimization problems involving Markovian noise with a zero-order oracle. We present and analyze a novel derivative-free method for solving such problems in strongly convex smooth and non-smooth settings with both one-point and two-point feedback oracles. Using a randomized batching scheme, we show that when mixing time $τ$ of the underlying noise sequence is less than the dimension of the problem $d$, the convergence estimates of our method do not depend on $τ$. This observation provides an efficient way to interact with Markovian stochasticity: instead of invoking the expensive first-order oracle, one should use the zero-order oracle. Finally, we complement our upper bounds with the corresponding lower bounds. This confirms the optimality of our results.
UCB-type Algorithm for Budget-Constrained Expert Learning
Oct 26, 2025In many modern applications, a system must dynamically choose between several adaptive learning algorithms that are trained online. Examples include model selection in streaming environments, switching between trading strategies in finance, and orchestrating multiple contextual bandit or reinforcement learning agents. At each round, a learner must select one predictor among $K$ adaptive experts to make a prediction, while being able to update at most $M \le K$ of them under a fixed training budget. We address this problem in the \emph{stochastic setting} and introduce \algname{M-LCB}, a computationally efficient UCB-style meta-algorithm that provides \emph{anytime regret guarantees}. Its confidence intervals are built directly from realized losses, require no additional optimization, and seamlessly reflect the convergence properties of the underlying experts. If each expert achieves internal regret $\tilde O(T^\alpha)$, then \algname{M-LCB} ensures overall regret bounded by $\tilde O\!\Bigl(\sqrt{\tfrac{KT}{M}} \;+\; (K/M)^{1-\alpha}\,T^\alpha\Bigr)$. To our knowledge, this is the first result establishing regret guarantees when multiple adaptive experts are trained simultaneously under per-round budget constraints. We illustrate the framework with two representative cases: (i) parametric models trained online with stochastic losses, and (ii) experts that are themselves multi-armed bandit algorithms. These examples highlight how \algname{M-LCB} extends the classical bandit paradigm to the more realistic scenario of coordinating stateful, self-learning experts under limited resources.
Simple Stepsize for Quasi-Newton Methods with Global Convergence Guarantees
Aug 27, 2025Quasi-Newton methods are widely used for solving convex optimization problems due to their ease of implementation, practical efficiency, and strong local convergence guarantees. However, their global convergence is typically established only under specific line search strategies and the assumption of strong convexity. In this work, we extend the theoretical understanding of Quasi-Newton methods by introducing a simple stepsize schedule that guarantees a global convergence rate of ${O}(1/k)$ for the convex functions. Furthermore, we show that when the inexactness of the Hessian approximation is controlled within a prescribed relative accuracy, the method attains an accelerated convergence rate of ${O}(1/k^2)$ -- matching the best-known rates of both Nesterov's accelerated gradient method and cubically regularized Newton methods. We validate our theoretical findings through empirical comparisons, demonstrating clear improvements over standard Quasi-Newton baselines. To further enhance robustness, we develop an adaptive variant that adjusts to the function's curvature while retaining the global convergence guarantees of the non-adaptive algorithm.
AdLoCo: adaptive batching significantly improves communications efficiency and convergence for Large Language Models
Aug 25, 2025Scaling distributed training of Large Language Models (LLMs) requires not only algorithmic advances but also efficient utilization of heterogeneous hardware resources. While existing methods such as DiLoCo have demonstrated promising results, they often fail to fully exploit computational clusters under dynamic workloads. To address this limitation, we propose a three-stage method that combines Multi-Instance Training (MIT), Adaptive Batched DiLoCo, and switch mode mechanism. MIT allows individual nodes to run multiple lightweight training streams with different model instances in parallel and merge them to combine knowledge, increasing throughput and reducing idle time. Adaptive Batched DiLoCo dynamically adjusts local batch sizes to balance computation and communication, substantially lowering synchronization delays. Switch mode further stabilizes training by seamlessly introducing gradient accumulation once adaptive batch sizes grow beyond hardware-friendly limits. Together, these innovations improve both convergence speed and system efficiency. We also provide a theoretical estimate of the number of communications required for the full convergence of a model trained using our method.
KompeteAI: Accelerated Autonomous Multi-Agent System for End-to-End Pipeline Generation for Machine Learning Problems
Aug 13, 2025



Recent Large Language Model (LLM)-based AutoML systems demonstrate impressive capabilities but face significant limitations such as constrained exploration strategies and a severe execution bottleneck. Exploration is hindered by one-shot methods lacking diversity and Monte Carlo Tree Search (MCTS) approaches that fail to recombine strong partial solutions. The execution bottleneck arises from lengthy code validation cycles that stifle iterative refinement. To overcome these challenges, we introduce KompeteAI, a novel AutoML framework with dynamic solution space exploration. Unlike previous MCTS methods that treat ideas in isolation, KompeteAI introduces a merging stage that composes top candidates. We further expand the hypothesis space by integrating Retrieval-Augmented Generation (RAG), sourcing ideas from Kaggle notebooks and arXiv papers to incorporate real-world strategies. KompeteAI also addresses the execution bottleneck via a predictive scoring model and an accelerated debugging method, assessing solution potential using early stage metrics to avoid costly full-code execution. This approach accelerates pipeline evaluation 6.9 times. KompeteAI outperforms leading methods (e.g., RD-agent, AIDE, and Ml-Master) by an average of 3\% on the primary AutoML benchmark, MLE-Bench. Additionally, we propose Kompete-bench to address limitations in MLE-Bench, where KompeteAI also achieves state-of-the-art results
Sign Operator for Coping with Heavy-Tailed Noise: High Probability Convergence Bounds with Extensions to Distributed Optimization and Comparison Oracle
Feb 11, 2025



The growing popularity of AI optimization problems involving severely corrupted data has increased the demand for methods capable of handling heavy-tailed noise, i.e., noise with bounded $\kappa$-th moment, $\kappa \in (1,2]$. For the widely used clipping technique, effectiveness heavily depends on the careful tuning of clipping levels throughout training. In this paper, we demonstrate that using only the sign of the input, without introducing additional hyperparameters, is sufficient to cope with heavy-tailed noise effectively. For smooth non-convex functions, we prove that SignSGD achieves optimal sample complexity $\tilde{O}\left(\varepsilon^{-\frac{3\kappa - 2}{\kappa - 1}}\right)$ with high probability for attaining an average gradient norm accuracy of $\varepsilon$. Under the assumption of symmetric noise, we use SignSGD with Majority Voting to extend this bound to the distributed optimization or reduce the sample complexity to $\tilde{O}(\varepsilon^{-4})$ in the case of a single worker with arbitrary parameters. Furthermore, we explore the application of the sign operator in zeroth-order optimization with an oracle that can only compare function values at two different points. We propose a novel method, MajorityVote-CompsSGD, and provide the first-known high-probability bound $\tilde{O}(\varepsilon^{-6})$ for the number of comparisons under symmetric noise assumption. Our theoretical findings are supported by the superior performance of sign-based methods in training Large Language Models.
Accelerated zero-order SGD under high-order smoothness and overparameterized regime
Nov 21, 2024
We present a novel gradient-free algorithm to solve a convex stochastic optimization problem, such as those encountered in medicine, physics, and machine learning (e.g., adversarial multi-armed bandit problem), where the objective function can only be computed through numerical simulation, either as the result of a real experiment or as feedback given by the function evaluations from an adversary. Thus we suppose that only a black-box access to the function values of the objective is available, possibly corrupted by adversarial noise: deterministic or stochastic. The noisy setup can arise naturally from modeling randomness within a simulation or by computer discretization, or when exact values of function are forbidden due to privacy issues, or when solving non-convex problems as convex ones with an inexact function oracle. By exploiting higher-order smoothness, fulfilled, e.g., in logistic regression, we improve the performance of zero-order methods developed under the assumption of classical smoothness (or having a Lipschitz gradient). The proposed algorithm enjoys optimal oracle complexity and is designed under an overparameterization setup, i.e., when the number of model parameters is much larger than the size of the training dataset. Overparametrized models fit to the training data perfectly while also having good generalization and outperforming underparameterized models on unseen data. We provide convergence guarantees for the proposed algorithm under both types of noise. Moreover, we estimate the maximum permissible adversarial noise level that maintains the desired accuracy in the Euclidean setup, and then we extend our results to a non-Euclidean setup. Our theoretical results are verified on the logistic regression problem.
Exploring Applications of State Space Models and Advanced Training Techniques in Sequential Recommendations: A Comparative Study on Efficiency and Performance
Aug 10, 2024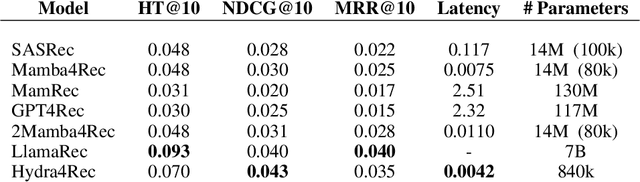
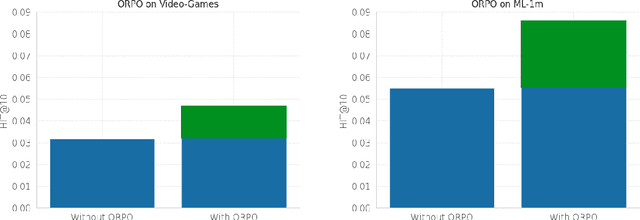
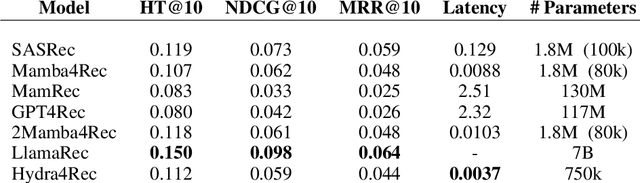
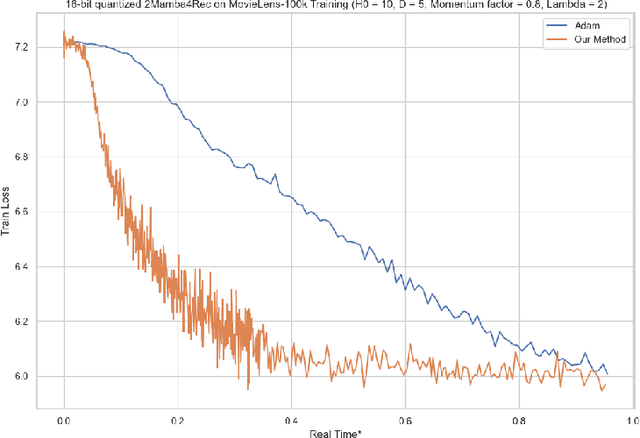
Recommender systems aim to estimate the dynamically changing user preferences and sequential dependencies between historical user behaviour and metadata. Although transformer-based models have proven to be effective in sequential recommendations, their state growth is proportional to the length of the sequence that is being processed, which makes them expensive in terms of memory and inference costs. Our research focused on three promising directions in sequential recommendations: enhancing speed through the use of State Space Models (SSM), as they can achieve SOTA results in the sequential recommendations domain with lower latency, memory, and inference costs, as proposed by arXiv:2403.03900 improving the quality of recommendations with Large Language Models (LLMs) via Monolithic Preference Optimization without Reference Model (ORPO); and implementing adaptive batch- and step-size algorithms to reduce costs and accelerate training processes.