 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
eSASRec: Enhancing Transformer-based Recommendations in a Modular Fashion
Aug 08, 2025Since their introduction, Transformer-based models, such as SASRec and BERT4Rec, have become common baselines for sequential recommendations, surpassing earlier neural and non-neural methods. A number of following publications have shown that the effectiveness of these models can be improved by, for example, slightly updating the architecture of the Transformer layers, using better training objectives, and employing improved loss functions. However, the additivity of these modular improvements has not been systematically benchmarked - this is the gap we aim to close in this paper. Through our experiments, we identify a very strong model that uses SASRec's training objective, LiGR Transformer layers, and Sampled Softmax Loss. We call this combination eSASRec (Enhanced SASRec). While we primarily focus on realistic, production-like evaluation, in our preliminarily study we find that common academic benchmarks show eSASRec to be 23% more effective compared to the most recent state-of-the-art models, such as ActionPiece. In our main production-like benchmark, eSASRec resides on the Pareto frontier in terms of the accuracy-coverage tradeoff (alongside the recent industrial models HSTU and FuXi. As the modifications compared to the original SASRec are relatively straightforward and no extra features are needed (such as timestamps in HSTU), we believe that eSASRec can be easily integrated into existing recommendation pipelines and can can serve as a strong yet very simple baseline for emerging complicated algorithms. To facilitate this, we provide the open-source implementations for our models and benchmarks in repository https://github.com/blondered/transformer_benchmark
Gradient-Normalized Smoothness for Optimization with Approximate Hessians
Jun 16, 2025



In this work, we develop new optimization algorithms that use approximate second-order information combined with the gradient regularization technique to achieve fast global convergence rates for both convex and non-convex objectives. The key innovation of our analysis is a novel notion called Gradient-Normalized Smoothness, which characterizes the maximum radius of a ball around the current point that yields a good relative approximation of the gradient field. Our theory establishes a natural intrinsic connection between Hessian approximation and the linearization of the gradient. Importantly, Gradient-Normalized Smoothness does not depend on the specific problem class of the objective functions, while effectively translating local information about the gradient field and Hessian approximation into the global behavior of the method. This new concept equips approximate second-order algorithms with universal global convergence guarantees, recovering state-of-the-art rates for functions with H\"older-continuous Hessians and third derivatives, quasi-self-concordant functions, as well as smooth classes in first-order optimization. These rates are achieved automatically and extend to broader classes, such as generalized self-concordant functions. We demonstrate direct applications of our results for global linear rates in logistic regression and softmax problems with approximate Hessians, as well as in non-convex optimization using Fisher and Gauss-Newton approximations.
Sign Operator for Coping with Heavy-Tailed Noise: High Probability Convergence Bounds with Extensions to Distributed Optimization and Comparison Oracle
Feb 11, 2025



The growing popularity of AI optimization problems involving severely corrupted data has increased the demand for methods capable of handling heavy-tailed noise, i.e., noise with bounded $\kappa$-th moment, $\kappa \in (1,2]$. For the widely used clipping technique, effectiveness heavily depends on the careful tuning of clipping levels throughout training. In this paper, we demonstrate that using only the sign of the input, without introducing additional hyperparameters, is sufficient to cope with heavy-tailed noise effectively. For smooth non-convex functions, we prove that SignSGD achieves optimal sample complexity $\tilde{O}\left(\varepsilon^{-\frac{3\kappa - 2}{\kappa - 1}}\right)$ with high probability for attaining an average gradient norm accuracy of $\varepsilon$. Under the assumption of symmetric noise, we use SignSGD with Majority Voting to extend this bound to the distributed optimization or reduce the sample complexity to $\tilde{O}(\varepsilon^{-4})$ in the case of a single worker with arbitrary parameters. Furthermore, we explore the application of the sign operator in zeroth-order optimization with an oracle that can only compare function values at two different points. We propose a novel method, MajorityVote-CompsSGD, and provide the first-known high-probability bound $\tilde{O}(\varepsilon^{-6})$ for the number of comparisons under symmetric noise assumption. Our theoretical findings are supported by the superior performance of sign-based methods in training Large Language Models.
Just a Simple Transformation is Enough for Data Protection in Vertical Federated Learning
Dec 16, 2024Vertical Federated Learning (VFL) aims to enable collaborative training of deep learning models while maintaining privacy protection. However, the VFL procedure still has components that are vulnerable to attacks by malicious parties. In our work, we consider feature reconstruction attacks, a common risk targeting input data compromise. We theoretically claim that feature reconstruction attacks cannot succeed without knowledge of the prior distribution on data. Consequently, we demonstrate that even simple model architecture transformations can significantly impact the protection of input data during VFL. Confirming these findings with experimental results, we show that MLP-based models are resistant to state-of-the-art feature reconstruction attacks.
Mixed Newton Method for Optimization in Complex Spaces
Jul 29, 2024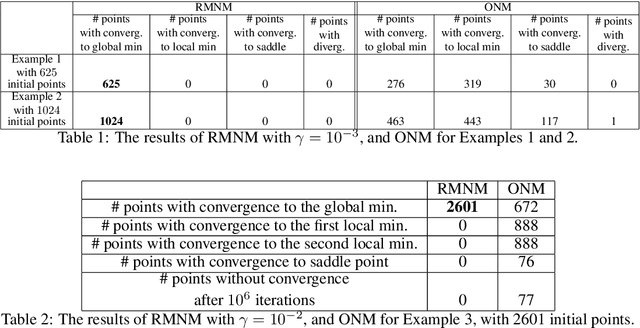
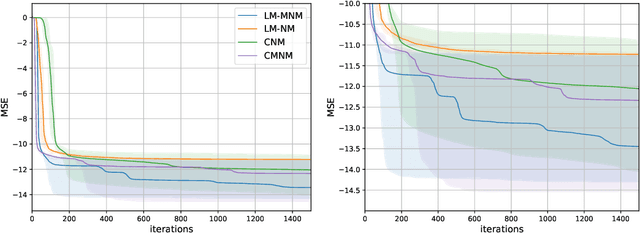
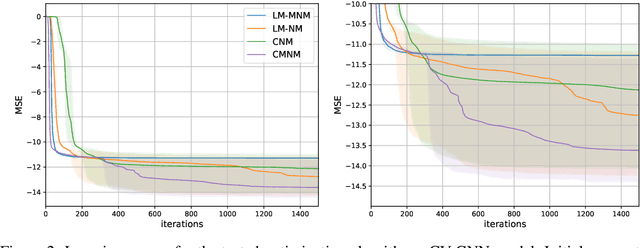
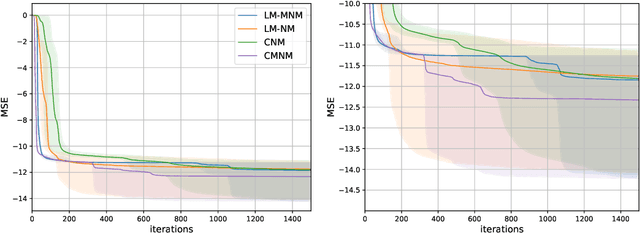
In this paper, we modify and apply the recently introduced Mixed Newton Method, which is originally designed for minimizing real-valued functions of complex variables, to the minimization of real-valued functions of real variables by extending the functions to complex space. We show that arbitrary regularizations preserve the favorable local convergence properties of the method, and construct a special type of regularization used to prevent convergence to complex minima. We compare several variants of the method applied to training neural networks with real and complex parameters.
Gradient Clipping Improves AdaGrad when the Noise Is Heavy-Tailed
Jun 06, 2024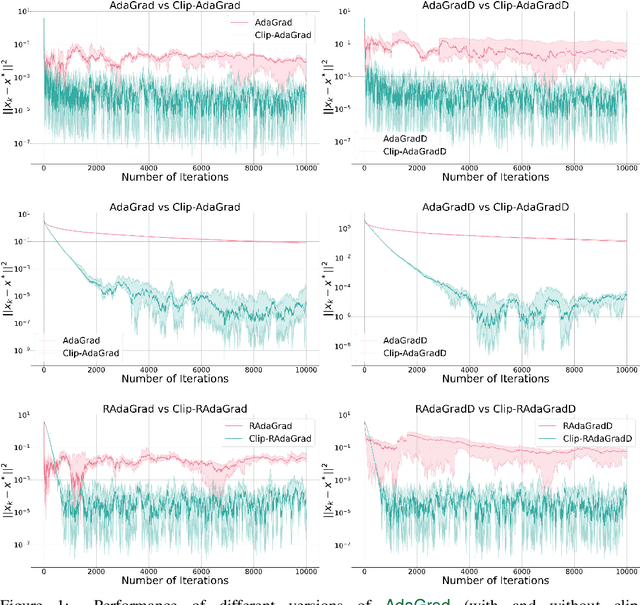
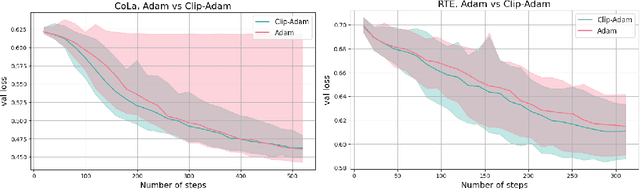
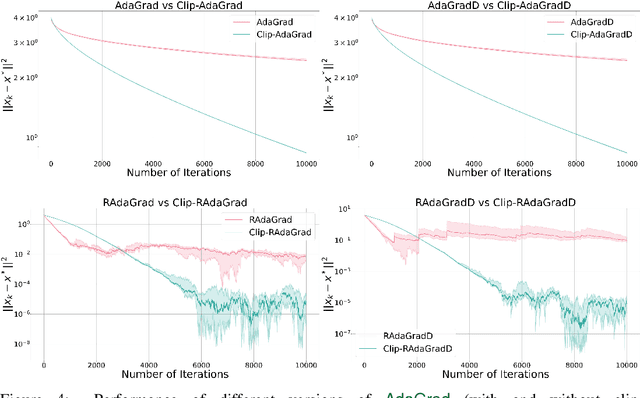
Methods with adaptive stepsizes, such as AdaGrad and Adam, are essential for training modern Deep Learning models, especially Large Language Models. Typically, the noise in the stochastic gradients is heavy-tailed for the later ones. Gradient clipping provably helps to achieve good high-probability convergence for such noises. However, despite the similarity between AdaGrad/Adam and Clip-SGD, the high-probability convergence of AdaGrad/Adam has not been studied in this case. In this work, we prove that AdaGrad (and its delayed version) can have provably bad high-probability convergence if the noise is heavy-tailed. To fix this issue, we propose a new version of AdaGrad called Clip-RAdaGradD (Clipped Reweighted AdaGrad with Delay) and prove its high-probability convergence bounds with polylogarithmic dependence on the confidence level for smooth convex/non-convex stochastic optimization with heavy-tailed noise. Our empirical evaluations, including NLP model fine-tuning, highlight the superiority of clipped versions of AdaGrad/Adam in handling the heavy-tailed noise.
Sparse Concept Bottleneck Models: Gumbel Tricks in Contrastive Learning
Apr 04, 2024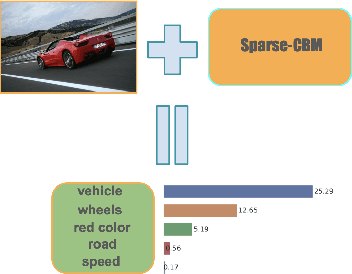

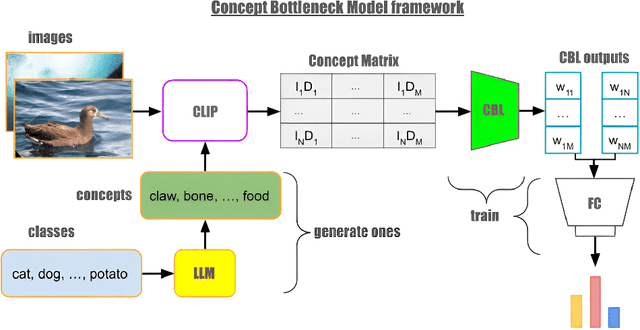

We propose a novel architecture and method of explainable classification with Concept Bottleneck Models (CBMs). While SOTA approaches to Image Classification task work as a black box, there is a growing demand for models that would provide interpreted results. Such a models often learn to predict the distribution over class labels using additional description of this target instances, called concepts. However, existing Bottleneck methods have a number of limitations: their accuracy is lower than that of a standard model and CBMs require an additional set of concepts to leverage. We provide a framework for creating Concept Bottleneck Model from pre-trained multi-modal encoder and new CLIP-like architectures. By introducing a new type of layers known as Concept Bottleneck Layers, we outline three methods for training them: with $\ell_1$-loss, contrastive loss and loss function based on Gumbel-Softmax distribution (Sparse-CBM), while final FC layer is still trained with Cross-Entropy. We show a significant increase in accuracy using sparse hidden layers in CLIP-based bottleneck models. Which means that sparse representation of concepts activation vector is meaningful in Concept Bottleneck Models. Moreover, with our Concept Matrix Search algorithm we can improve CLIP predictions on complex datasets without any additional training or fine-tuning. The code is available at: https://github.com/Andron00e/SparseCBM.