 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Clipping Improves AdaGrad when the Noise Is Heavy-Tailed
Jun 06, 2024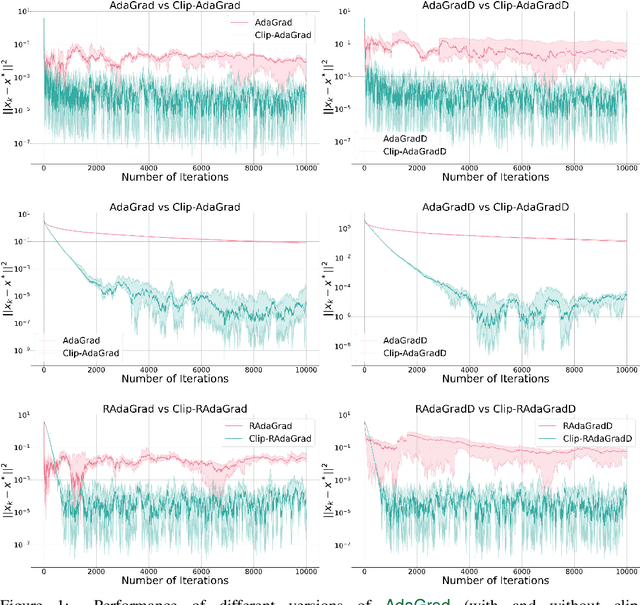
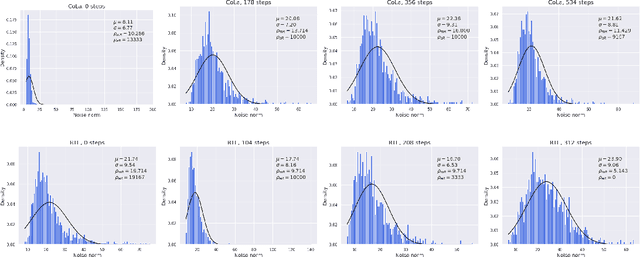
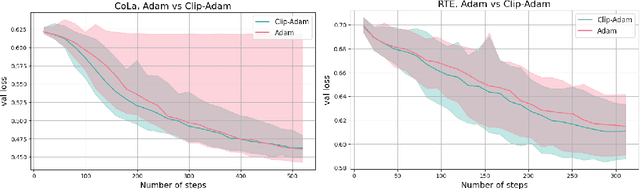
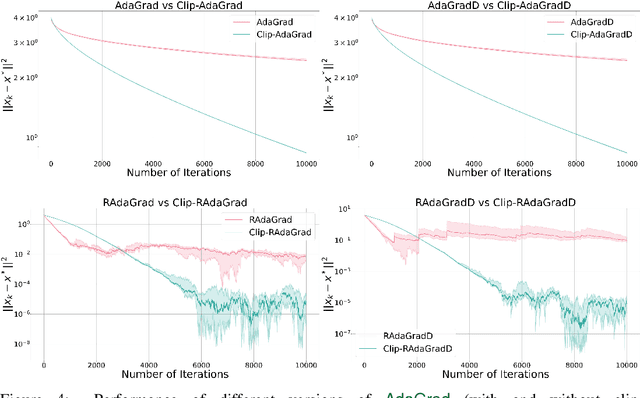
Methods with adaptive stepsizes, such as AdaGrad and Adam, are essential for training modern Deep Learning models, especially Large Language Models. Typically, the noise in the stochastic gradients is heavy-tailed for the later ones. Gradient clipping provably helps to achieve good high-probability convergence for such noises. However, despite the similarity between AdaGrad/Adam and Clip-SGD, the high-probability convergence of AdaGrad/Adam has not been studied in this case. In this work, we prove that AdaGrad (and its delayed version) can have provably bad high-probability convergence if the noise is heavy-tailed. To fix this issue, we propose a new version of AdaGrad called Clip-RAdaGradD (Clipped Reweighted AdaGrad with Delay) and prove its high-probability convergence bounds with polylogarithmic dependence on the confidence level for smooth convex/non-convex stochastic optimization with heavy-tailed noise. Our empirical evaluations, including NLP model fine-tuning, highlight the superiority of clipped versions of AdaGrad/Adam in handling the heavy-tailed noise.