 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining LLMs with Fault Tolerant HSDP on 100,000 GPUs
Jan 30, 2026Large-scale training systems typically use synchronous training, requiring all GPUs to be healthy simultaneously. In our experience training on O(100K) GPUs, synchronous training results in a low efficiency due to frequent failures and long recovery time. To address this problem, we propose a novel training paradigm, Fault Tolerant Hybrid-Shared Data Parallelism (FT-HSDP). FT-HSDP uses data parallel replicas as units of fault tolerance. When failures occur, only a single data-parallel replica containing the failed GPU or server is taken offline and restarted, while the other replicas continue training. To realize this idea at scale, FT-HSDP incorporates several techniques: 1) We introduce a Fault Tolerant All Reduce (FTAR) protocol for gradient exchange across data parallel replicas. FTAR relies on the CPU to drive the complex control logic for tasks like adding or removing participants dynamically, and relies on GPU to perform data transfer for best performance. 2) We introduce a non-blocking catch-up protocol, allowing a recovering replica to join training with minimal stall. Compared with fully synchronous training at O(100K) GPUs, FT-HSDP can reduce the stall time due to failure recovery from 10 minutes to 3 minutes, increasing effective training time from 44\% to 80\%. We further demonstrate that FT-HSDP's asynchronous recovery does not bring any meaning degradation to the accuracy of the result model.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Recontextualization Mitigates Specification Gaming without Modifying the Specification
Dec 22, 2025Developers often struggle to specify correct training labels and rewards. Perhaps they don't need to. We propose recontextualization, which reduces how often language models "game" training signals, performing misbehaviors those signals mistakenly reinforce. We show recontextualization prevents models from learning to 1) prioritize evaluation metrics over chat response quality; 2) special-case code to pass incorrect tests; 3) lie to users; and 4) become sycophantic. Our method works by generating completions from prompts discouraging misbehavior and then recontextualizing them as though they were in response to prompts permitting misbehavior. Recontextualization trains language models to resist misbehavior even when instructions permit it. This mitigates the reinforcement of misbehavior from misspecified training signals, reducing specification gaming without improving the supervision signal.
YABLoCo: Yet Another Benchmark for Long Context Code Generation
May 07, 2025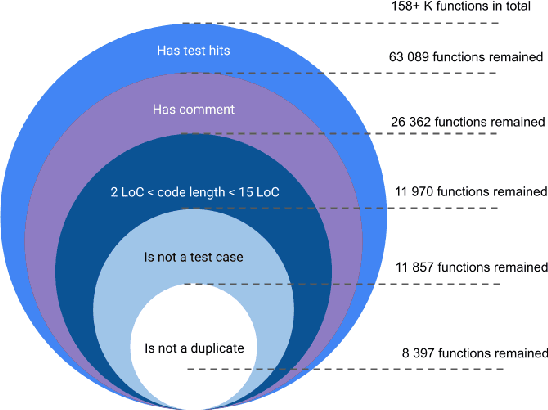
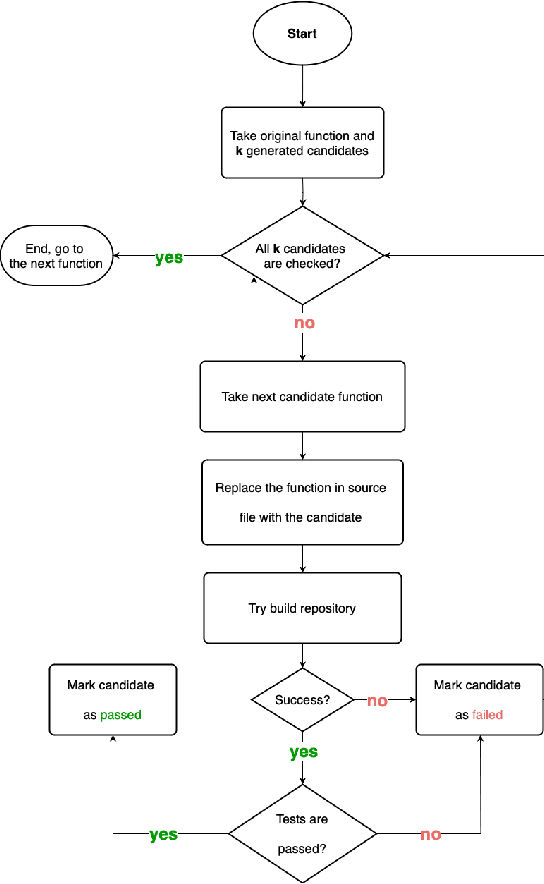
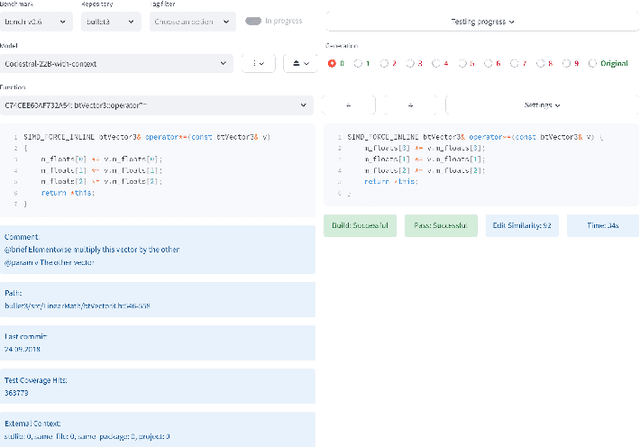
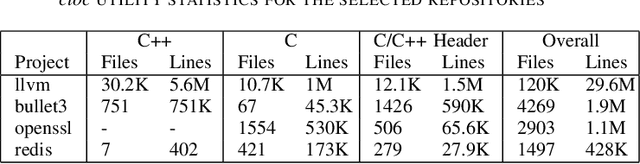
Large Language Models demonstrate the ability to solve various programming tasks, including code generation. Typically, the performance of LLMs is measured on benchmarks with small or medium-sized context windows of thousands of lines of code. At the same time, in real-world software projects, repositories can span up to millions of LoC. This paper closes this gap by contributing to the long context code generation benchmark (YABLoCo). The benchmark featured a test set of 215 functions selected from four large repositories with thousands of functions. The dataset contained metadata of functions, contexts of the functions with different levels of dependencies, docstrings, functions bodies, and call graphs for each repository. This paper presents three key aspects of the contribution. First, the benchmark aims at function body generation in large repositories in C and C++, two languages not covered by previous benchmarks. Second, the benchmark contains large repositories from 200K to 2,000K LoC. Third, we contribute a scalable evaluation pipeline for efficient computing of the target metrics and a tool for visual analysis of generated code. Overall, these three aspects allow for evaluating code generation in large repositories in C and C++.
Code Summarization Beyond Function Level
Feb 23, 2025



Code summarization is a critical task in natural language processing and software engineering, which aims to generate concise descriptions of source code. Recent advancements have improved the quality of these summaries, enhancing code readability and maintainability. However, the content of a repository or a class has not been considered in function code summarization. This study investigated the effectiveness of code summarization models beyond the function level, exploring the impact of class and repository contexts on the summary quality. The study involved revising benchmarks for evaluating models at class and repository levels, assessing baseline models, and evaluating LLMs with in-context learning to determine the enhancement of summary quality with additional context. The findings revealed that the fine-tuned state-of-the-art CodeT5+ base model excelled in code summarization, while incorporating few-shot learning and retrieved code chunks from RAG significantly enhanced the performance of LLMs in this task. Notably, the Deepseek Coder 1.3B and Starcoder2 15B models demonstrated substantial improvements in metrics such as BLEURT, METEOR, and BLEU-4 at both class and repository levels. Repository-level summarization exhibited promising potential but necessitates significant computational resources and gains from the inclusion of structured context. Lastly, we employed the recent SIDE code summarization metric in our evaluation. This study contributes to refining strategies for prompt engineering, few-shot learning, and RAG, addressing gaps in benchmarks for code summarization at various levels. Finally, we publish all study details, code, datasets, and results of evaluation in the GitHub repository available at https://github.com/kilimanj4r0/code-summarization-beyond-function-level.
Leveraging Large Language Models in Code Question Answering: Baselines and Issues
Nov 05, 2024
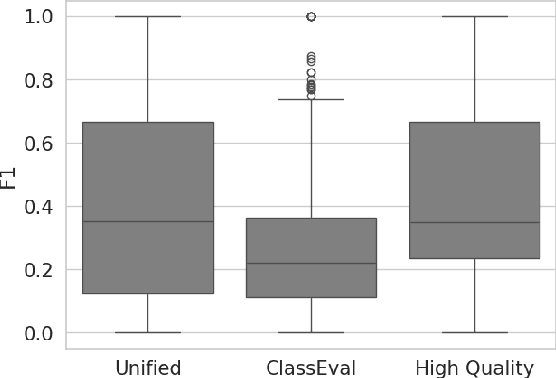
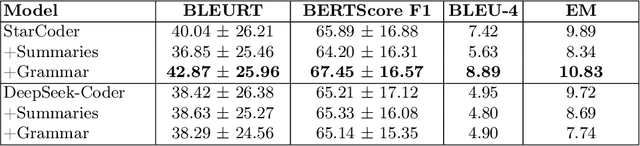
Question answering over source code provides software engineers and project managers with helpful information about the implemented features of a software product. This paper presents a work devoted to using large language models for question answering over source code in Python. The proposed method for implementing a source code question answering system involves fine-tuning a large language model on a unified dataset of questions and answers for Python code. To achieve the highest quality answers, we tested various models trained on datasets preprocessed in different ways: a dataset without grammar correction, a dataset with grammar correction, and a dataset augmented with the generated summaries. The model answers were also analyzed for errors manually. We report BLEU-4, BERTScore F1, BLEURT, and Exact Match metric values, along with the conclusions from the manual error analysis. The obtained experimental results highlight the current problems of the research area, such as poor quality of the public genuine question-answering datasets. In addition, the findings include the positive effect of the grammar correction of the training data on the testing metric values. The addressed findings and issues could be important for other researchers who attempt to improve the quality of source code question answering solutions. The training and evaluation code is publicly available at https://github.com/IU-AES-AI4Code/CodeQuestionAnswering.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Sparse Concept Bottleneck Models: Gumbel Tricks in Contrastive Learning
Apr 04, 2024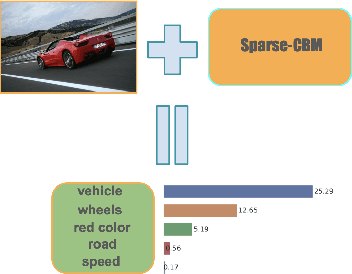

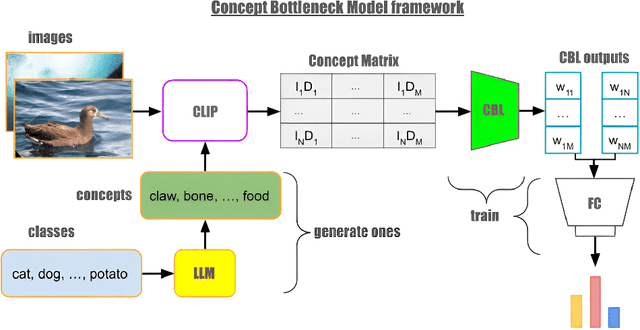

We propose a novel architecture and method of explainable classification with Concept Bottleneck Models (CBMs). While SOTA approaches to Image Classification task work as a black box, there is a growing demand for models that would provide interpreted results. Such a models often learn to predict the distribution over class labels using additional description of this target instances, called concepts. However, existing Bottleneck methods have a number of limitations: their accuracy is lower than that of a standard model and CBMs require an additional set of concepts to leverage. We provide a framework for creating Concept Bottleneck Model from pre-trained multi-modal encoder and new CLIP-like architectures. By introducing a new type of layers known as Concept Bottleneck Layers, we outline three methods for training them: with $\ell_1$-loss, contrastive loss and loss function based on Gumbel-Softmax distribution (Sparse-CBM), while final FC layer is still trained with Cross-Entropy. We show a significant increase in accuracy using sparse hidden layers in CLIP-based bottleneck models. Which means that sparse representation of concepts activation vector is meaningful in Concept Bottleneck Models. Moreover, with our Concept Matrix Search algorithm we can improve CLIP predictions on complex datasets without any additional training or fine-tuning. The code is available at: https://github.com/Andron00e/SparseCBM.
Cross-Modal Conceptualization in Bottleneck Models
Oct 23, 2023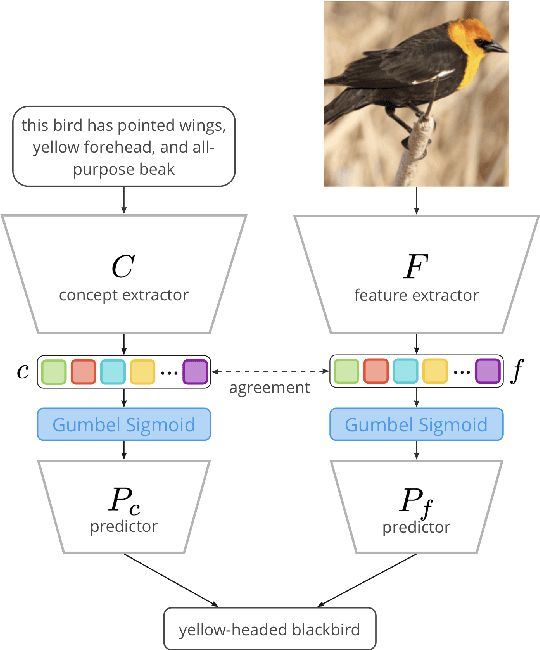
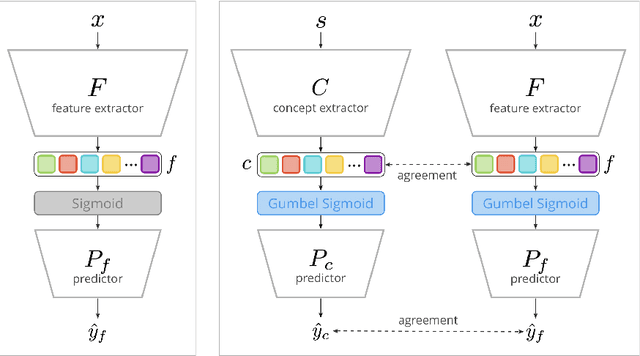
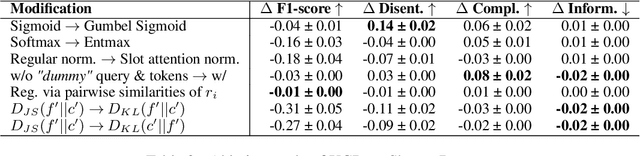
Concept Bottleneck Models (CBMs) assume that training examples (e.g., x-ray images) are annotated with high-level concepts (e.g., types of abnormalities), and perform classification by first predicting the concepts, followed by predicting the label relying on these concepts. The main difficulty in using CBMs comes from having to choose concepts that are predictive of the label and then having to label training examples with these concepts. In our approach, we adopt a more moderate assumption and instead use text descriptions (e.g., radiology reports), accompanying the images in training, to guide the induction of concepts. Our cross-modal approach treats concepts as discrete latent variables and promotes concepts that (1) are predictive of the label, and (2) can be predicted reliably from both the image and text. Through experiments conducted on datasets ranging from synthetic datasets (e.g., synthetic images with generated descriptions) to realistic medical imaging datasets, we demonstrate that cross-modal learning encourages the induction of interpretable concepts while also facilitating disentanglement. Our results also suggest that this guidance leads to increased robustness by suppressing the reliance on shortcut features.
Automatic generation of a large dictionary with concreteness/abstractness ratings based on a small human dictionary
Jun 13, 2022
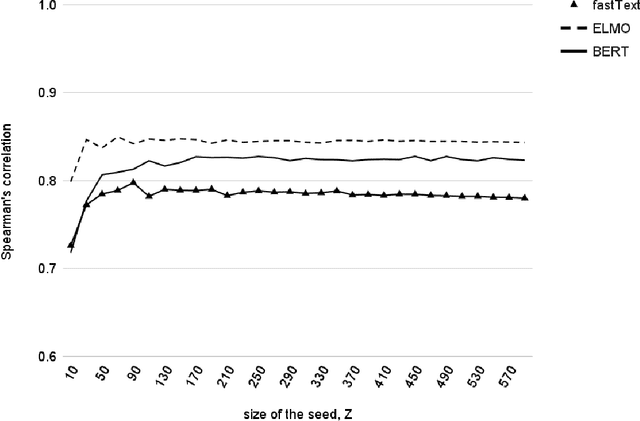

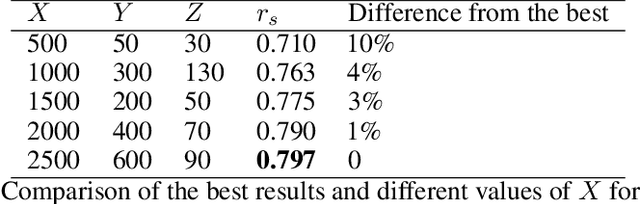
Concrete/abstract words are used in a growing number of psychological and neurophysiological research. For a few languages, large dictionaries have been created manually. This is a very time-consuming and costly process. To generate large high-quality dictionaries of concrete/abstract words automatically one needs extrapolating the expert assessments obtained on smaller samples. The research question that arises is how small such samples should be to do a good enough extrapolation. In this paper, we present a method for automatic ranking concreteness of words and propose an approach to significantly decrease amount of expert assessment. The method has been evaluated on a large test set for English. The quality of the constructed dictionaries is comparable to the expert ones. The correlation between predicted and expert ratings is higher comparing to the state-of-the-art methods.