 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREPA: Russian Error Types Annotation for Evaluating Text Generation and Judgment Capabilities
Mar 17, 2025Recent advances in large language models (LLMs) have introduced the novel paradigm of using LLMs as judges, where an LLM evaluates and scores the outputs of another LLM, which often correlates highly with human preferences. However, the use of LLM-as-a-judge has been primarily studied in English. In this paper, we evaluate this framework in Russian by introducing the Russian Error tyPes Annotation dataset (REPA), a dataset of 1k user queries and 2k LLM-generated responses. Human annotators labeled each response pair expressing their preferences across ten specific error types, as well as selecting an overall preference. We rank six generative LLMs across the error types using three rating systems based on human preferences. We also evaluate responses using eight LLM judges in zero-shot and few-shot settings. We describe the results of analyzing the judges and position and length biases. Our findings reveal a notable gap between LLM judge performance in Russian and English. However, rankings based on human and LLM preferences show partial alignment, suggesting that while current LLM judges struggle with fine-grained evaluation in Russian, there is potential for improvement.
NEREL: A Russian Dataset with Nested Named Entities, Relations and Events
Sep 03, 2021
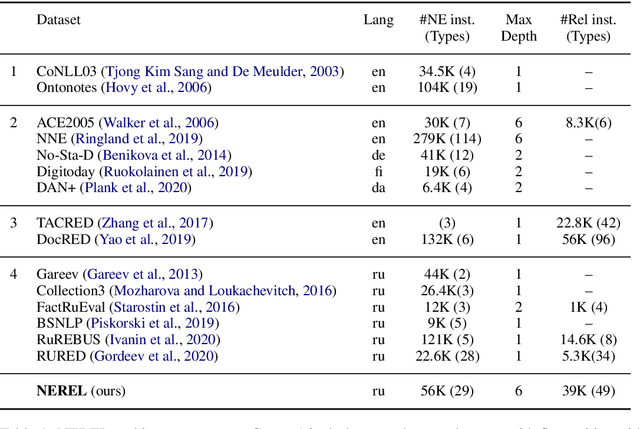
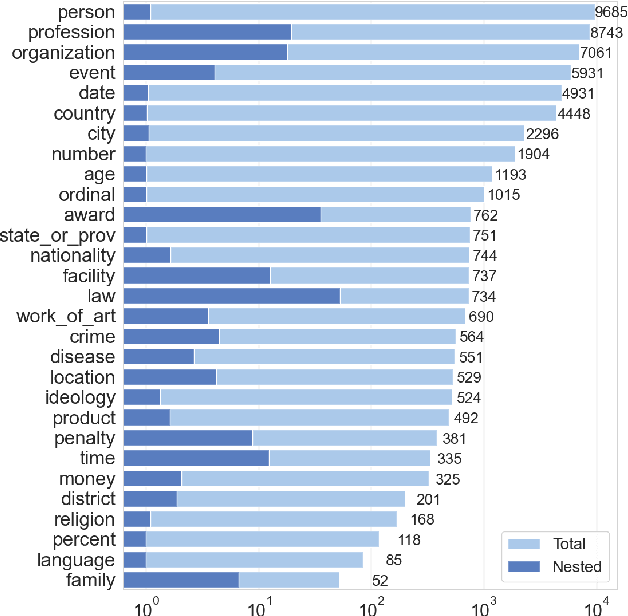
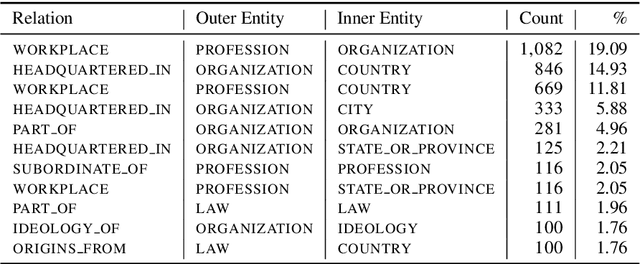
In this paper, we present NEREL, a Russian dataset for named entity recognition and relation extraction. NEREL is significantly larger than existing Russian datasets: to date it contains 56K annotated named entities and 39K annotated relations. Its important difference from previous datasets is annotation of nested named entities, as well as relations within nested entities and at the discourse level. NEREL can facilitate development of novel models that can extract relations between nested named entities, as well as relations on both sentence and document levels. NEREL also contains the annotation of events involving named entities and their roles in the events. The NEREL collection is available via https://github.com/nerel-ds/NEREL.
Sentence Embeddings for Russian NLU
Oct 29, 2019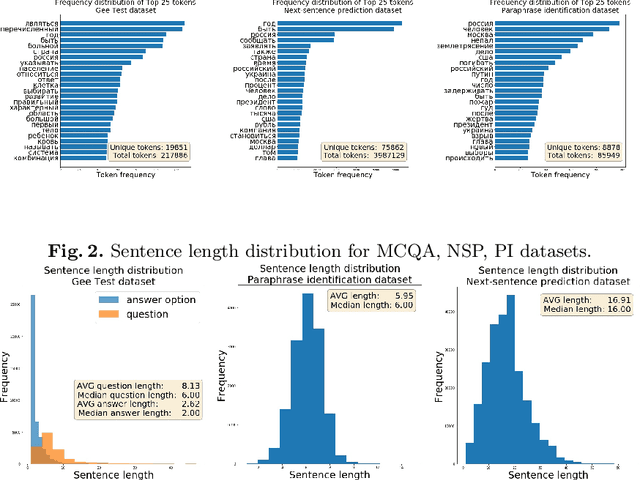
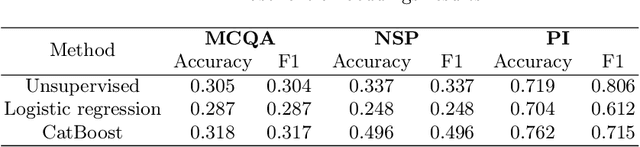
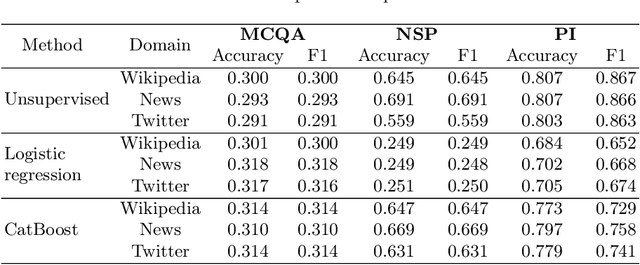
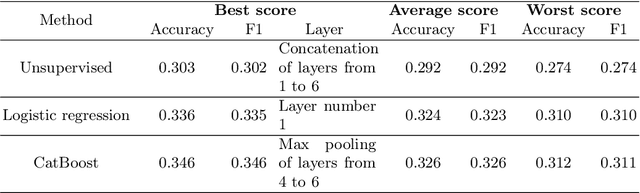
We investigate the performance of sentence embeddings models on several tasks for the Russian language. In our comparison, we include such tasks as multiple choice question answering, next sentence prediction, and paraphrase identification. We employ FastText embeddings as a baseline and compare it to ELMo and BERT embeddings. We conduct two series of experiments, using both unsupervised (i.e., based on similarity measure only) and supervised approaches for the tasks. Finally, we present datasets for multiple choice question answering and next sentence prediction in Russian.