 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentence Embeddings for Russian NLU
Oct 29, 2019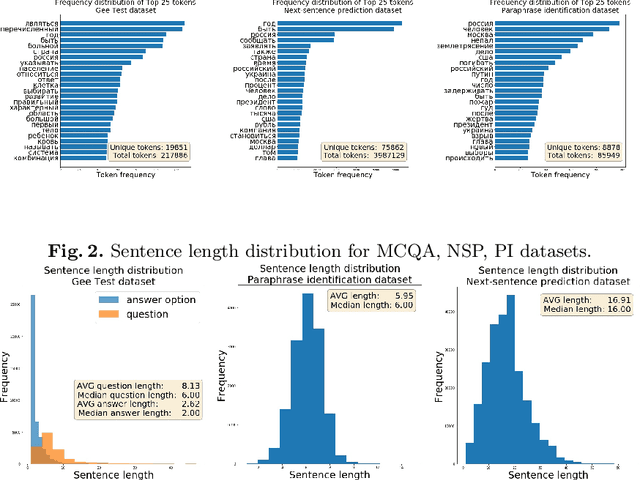
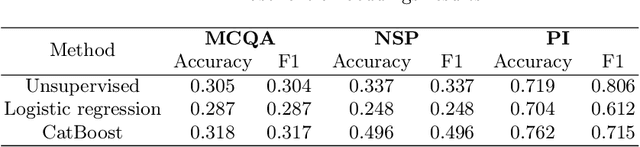
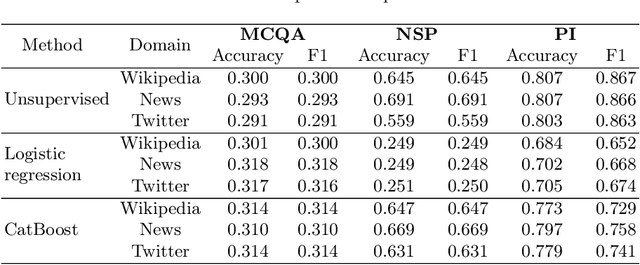
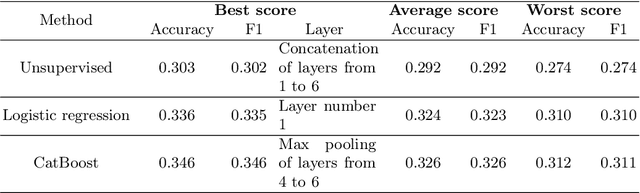
We investigate the performance of sentence embeddings models on several tasks for the Russian language. In our comparison, we include such tasks as multiple choice question answering, next sentence prediction, and paraphrase identification. We employ FastText embeddings as a baseline and compare it to ELMo and BERT embeddings. We conduct two series of experiments, using both unsupervised (i.e., based on similarity measure only) and supervised approaches for the tasks. Finally, we present datasets for multiple choice question answering and next sentence prediction in Russian.
Foreign English Accent Adjustment by Learning Phonetic Patterns
Jul 09, 2018
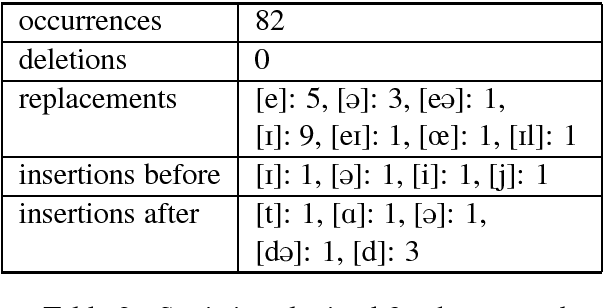
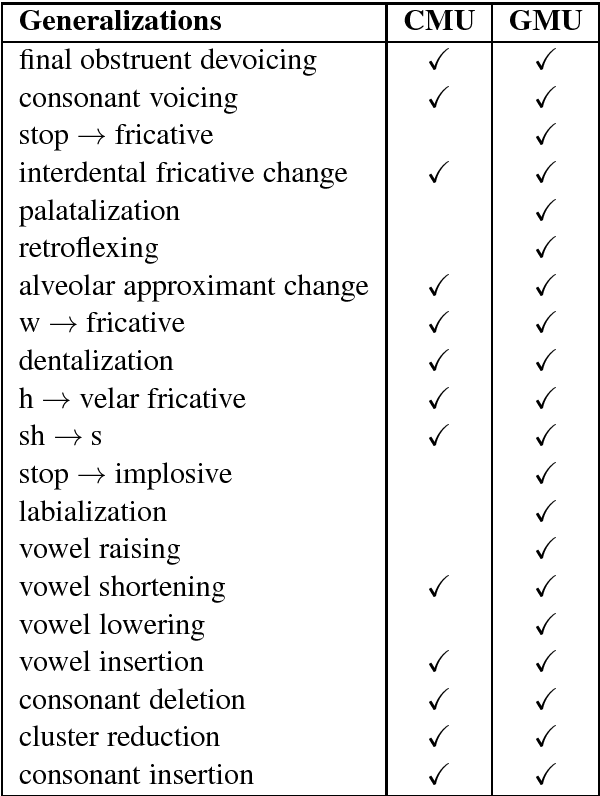
State-of-the-art automatic speech recognition (ASR) systems struggle with the lack of data for rare accents. For sufficiently large datasets, neural engines tend to outshine statistical models in most natural language processing problems. However, a speech accent remains a challenge for both approaches. Phonologists manually create general rules describing a speaker's accent, but their results remain underutilized. In this paper, we propose a model that automatically retrieves phonological generalizations from a small dataset. This method leverages the difference in pronunciation between a particular dialect and General American English (GAE) and creates new accented samples of words. The proposed model is able to learn all generalizations that previously were manually obtained by phonologists. We use this statistical method to generate a million phonological variations of words from the CMU Pronouncing Dictionary and train a sequence-to-sequence RNN to recognize accented words with 59% accuracy.