 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNorEval: A Norwegian Language Understanding and Generation Evaluation Benchmark
Apr 10, 2025This paper introduces NorEval, a new and comprehensive evaluation suite for large-scale standardized benchmarking of Norwegian generative language models (LMs). NorEval consists of 24 high-quality human-created datasets -- of which five are created from scratch. In contrast to existing benchmarks for Norwegian, NorEval covers a broad spectrum of task categories targeting Norwegian language understanding and generation, establishes human baselines, and focuses on both of the official written standards of the Norwegian language: Bokm{\aa}l and Nynorsk. All our datasets and a collection of over 100 human-written prompts are integrated into LM Evaluation Harness, ensuring flexible and reproducible evaluation. We describe the NorEval design and present the results of benchmarking 19 open-source pre-trained and instruction-tuned LMs for Norwegian in various scenarios. Our benchmark, evaluation framework, and annotation materials are publicly available.
REPA: Russian Error Types Annotation for Evaluating Text Generation and Judgment Capabilities
Mar 17, 2025Recent advances in large language models (LLMs) have introduced the novel paradigm of using LLMs as judges, where an LLM evaluates and scores the outputs of another LLM, which often correlates highly with human preferences. However, the use of LLM-as-a-judge has been primarily studied in English. In this paper, we evaluate this framework in Russian by introducing the Russian Error tyPes Annotation dataset (REPA), a dataset of 1k user queries and 2k LLM-generated responses. Human annotators labeled each response pair expressing their preferences across ten specific error types, as well as selecting an overall preference. We rank six generative LLMs across the error types using three rating systems based on human preferences. We also evaluate responses using eight LLM judges in zero-shot and few-shot settings. We describe the results of analyzing the judges and position and length biases. Our findings reveal a notable gap between LLM judge performance in Russian and English. However, rankings based on human and LLM preferences show partial alignment, suggesting that while current LLM judges struggle with fine-grained evaluation in Russian, there is potential for improvement.
An Expanded Massive Multilingual Dataset for High-Performance Language Technologies
Mar 13, 2025


Training state-of-the-art large language models requires vast amounts of clean and diverse textual data. However, building suitable multilingual datasets remains a challenge. In this work, we present HPLT v2, a collection of high-quality multilingual monolingual and parallel corpora. The monolingual portion of the data contains 8T tokens covering 193 languages, while the parallel data contains 380M sentence pairs covering 51 languages. We document the entire data pipeline and release the code to reproduce it. We provide extensive analysis of the quality and characteristics of our data. Finally, we evaluate the performance of language models and machine translation systems trained on HPLT v2, demonstrating its value.
Is Human-Like Text Liked by Humans? Multilingual Human Detection and Preference Against AI
Feb 17, 2025



Prior studies have shown that distinguishing text generated by large language models (LLMs) from human-written one is highly challenging, and often no better than random guessing. To verify the generalizability of this finding across languages and domains, we perform an extensive case study to identify the upper bound of human detection accuracy. Across 16 datasets covering 9 languages and 9 domains, 19 annotators achieved an average detection accuracy of 87.6%, thus challenging previous conclusions. We find that major gaps between human and machine text lie in concreteness, cultural nuances, and diversity. Prompting by explicitly explaining the distinctions in the prompts can partially bridge the gaps in over 50% of the cases. However, we also find that humans do not always prefer human-written text, particularly when they cannot clearly identify its source.
GenAI Content Detection Task 1: English and Multilingual Machine-Generated Text Detection: AI vs. Human
Jan 19, 2025We present the GenAI Content Detection Task~1 -- a shared task on binary machine generated text detection, conducted as a part of the GenAI workshop at COLING 2025. The task consists of two subtasks: Monolingual (English) and Multilingual. The shared task attracted many participants: 36 teams made official submissions to the Monolingual subtask during the test phase and 26 teams -- to the Multilingual. We provide a comprehensive overview of the data, a summary of the results -- including system rankings and performance scores -- detailed descriptions of the participating systems, and an in-depth analysis of submissions. https://github.com/mbzuai-nlp/COLING-2025-Workshop-on-MGT-Detection-Task1
A Collection of Question Answering Datasets for Norwegian
Jan 19, 2025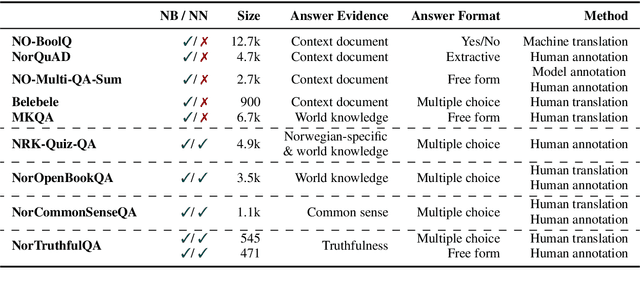
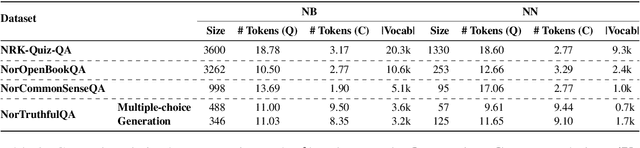
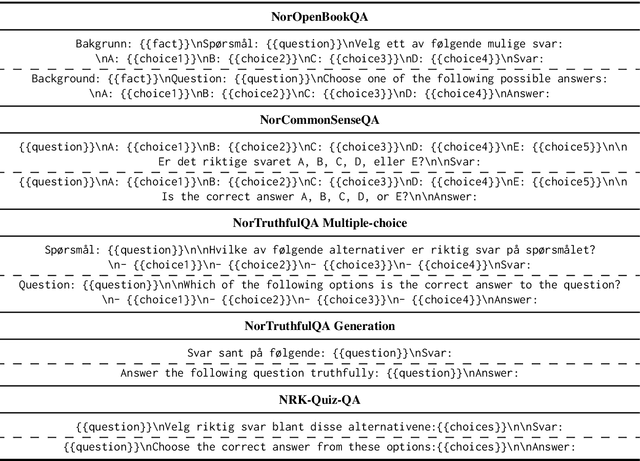
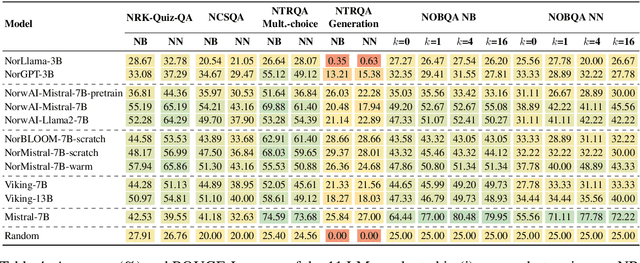
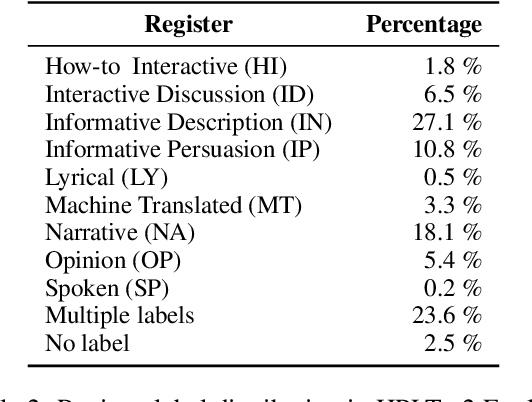
This paper introduces a new suite of question answering datasets for Norwegian; NorOpenBookQA, NorCommonSenseQA, NorTruthfulQA, and NRK-Quiz-QA. The data covers a wide range of skills and knowledge domains, including world knowledge, commonsense reasoning, truthfulness, and knowledge about Norway. Covering both of the written standards of Norwegian - Bokm{\aa}l and Nynorsk - our datasets comprise over 10k question-answer pairs, created by native speakers. We detail our dataset creation approach and present the results of evaluating 11 language models (LMs) in zero- and few-shot regimes. Most LMs perform better in Bokm{\aa}l than Nynorsk, struggle most with commonsense reasoning, and are often untruthful in generating answers to questions. All our datasets and annotation materials are publicly available.
Benchmarking Abstractive Summarisation: A Dataset of Human-authored Summaries of Norwegian News Articles
Jan 13, 2025



We introduce a dataset of high-quality human-authored summaries of news articles in Norwegian. The dataset is intended for benchmarking the abstractive summarisation capabilities of generative language models. Each document in the dataset is provided with three different candidate gold-standard summaries written by native Norwegian speakers, and all summaries are provided in both of the written variants of Norwegian -- Bokm{\aa}l and Nynorsk. The paper describes details on the data creation effort as well as an evaluation of existing open LLMs for Norwegian on the dataset. We also provide insights from a manual human evaluation, comparing human-authored to model-generated summaries. Our results indicate that the dataset provides a challenging LLM benchmark for Norwegian summarisation capabilities
The Impact of Copyrighted Material on Large Language Models: A Norwegian Perspective
Dec 12, 2024



The use of copyrighted materials in training generative language models raises critical legal and ethical questions. This paper presents a framework for and the results of empirically assessing the impact of copyrighted materials on the performance of large language models (LLMs) for Norwegian. We found that both books and newspapers contribute positively when the models are evaluated on a diverse set of Norwegian benchmarks, while fiction works possibly lead to decreased performance. Our experiments could inform the creation of a compensation scheme for authors whose works contribute to AI development.
Small Languages, Big Models: A Study of Continual Training on Languages of Norway
Dec 09, 2024



Training large language models requires vast amounts of data, posing a challenge for less widely spoken languages like Norwegian and even more so for truly low-resource languages like S\'ami. To address this issue, we present a novel three-stage continual training approach. We also experiment with combining causal and masked language modeling to get more flexible models. Based on our findings, we train, evaluate, and openly release a new large generative language model for Norwegian Bokm\r{a}l, Nynorsk, and Northern S\'ami with 11.4 billion parameters: NorMistral-11B.
Beemo: Benchmark of Expert-edited Machine-generated Outputs
Nov 06, 2024The rapid proliferation of large language models (LLMs) has increased the volume of machine-generated texts (MGTs) and blurred text authorship in various domains. However, most existing MGT benchmarks include single-author texts (human-written and machine-generated). This conventional design fails to capture more practical multi-author scenarios, where the user refines the LLM response for natural flow, coherence, and factual correctness. Our paper introduces the Benchmark of Expert-edited Machine-generated Outputs (Beemo), which includes 6.5k texts written by humans, generated by ten instruction-finetuned LLMs, and edited by experts for various use cases, ranging from creative writing to summarization. Beemo additionally comprises 13.1k machine-generated and LLM-edited texts, allowing for diverse MGT detection evaluation across various edit types. We document Beemo's creation protocol and present the results of benchmarking 33 configurations of MGT detectors in different experimental setups. We find that expert-based editing evades MGT detection, while LLM-edited texts are unlikely to be recognized as human-written. Beemo and all materials are publicly available.