 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenLID-v3: Improving the Precision of Closely Related Language Identification -- An Experience Report
Feb 13, 2026Language identification (LID) is an essential step in building high-quality multilingual datasets from web data. Existing LID tools (such as OpenLID or GlotLID) often struggle to identify closely related languages and to distinguish valid natural language from noise, which contaminates language-specific subsets, especially for low-resource languages. In this work we extend the OpenLID classifier by adding more training data, merging problematic language variant clusters, and introducing a special label for marking noise. We call this extended system OpenLID-v3 and evaluate it against GlotLID on multiple benchmarks. During development, we focus on three groups of closely related languages (Bosnian, Croatian, and Serbian; Romance varieties of Northern Italy and Southern France; and Scandinavian languages) and contribute new evaluation datasets where existing ones are inadequate. We find that ensemble approaches improve precision but also substantially reduce coverage for low-resource languages. OpenLID-v3 is available on https://huggingface.co/HPLT/OpenLID-v3.
An Expanded Massive Multilingual Dataset for High-Performance Language Technologies
Mar 13, 2025


Training state-of-the-art large language models requires vast amounts of clean and diverse textual data. However, building suitable multilingual datasets remains a challenge. In this work, we present HPLT v2, a collection of high-quality multilingual monolingual and parallel corpora. The monolingual portion of the data contains 8T tokens covering 193 languages, while the parallel data contains 380M sentence pairs covering 51 languages. We document the entire data pipeline and release the code to reproduce it. We provide extensive analysis of the quality and characteristics of our data. Finally, we evaluate the performance of language models and machine translation systems trained on HPLT v2, demonstrating its value.
Deep-change at AXOLOTL-24: Orchestrating WSD and WSI Models for Semantic Change Modeling
Aug 09, 2024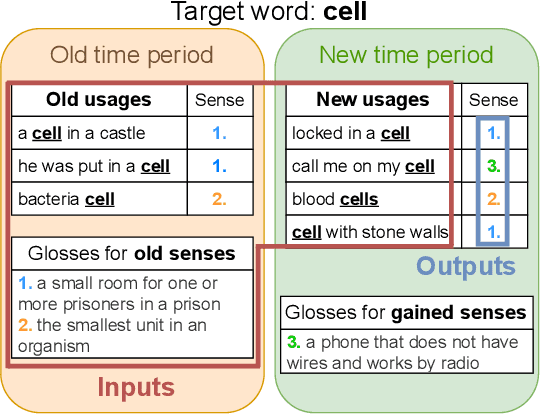

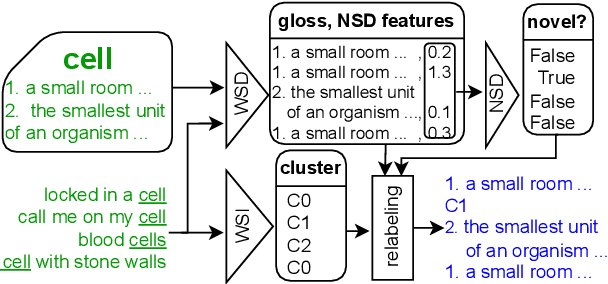
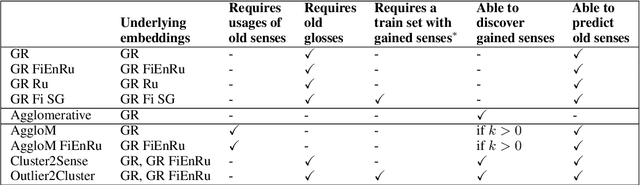
This paper describes our solution of the first subtask from the AXOLOTL-24 shared task on Semantic Change Modeling. The goal of this subtask is to distribute a given set of usages of a polysemous word from a newer time period between senses of this word from an older time period and clusters representing gained senses of this word. We propose and experiment with three new methods solving this task. Our methods achieve SOTA results according to both official metrics of the first substask. Additionally, we develop a model that can tell if a given word usage is not described by any of the provided sense definitions. This model serves as a component in one of our methods, but can potentially be useful on its own.
Multilingual Substitution-based Word Sense Induction
May 17, 2024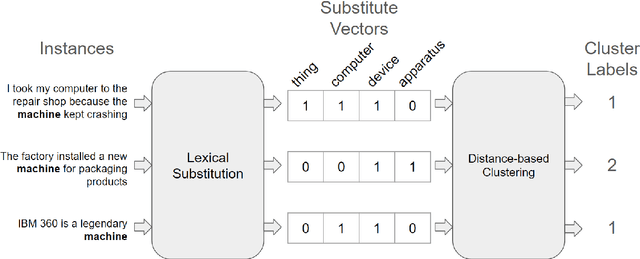
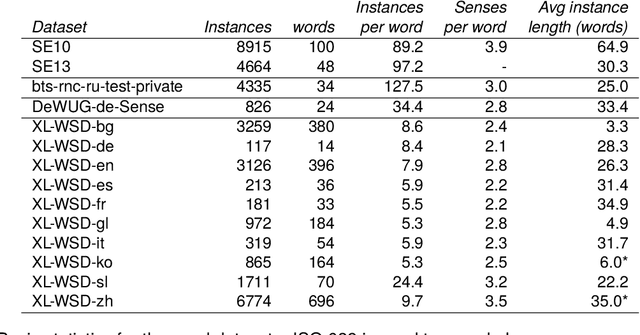
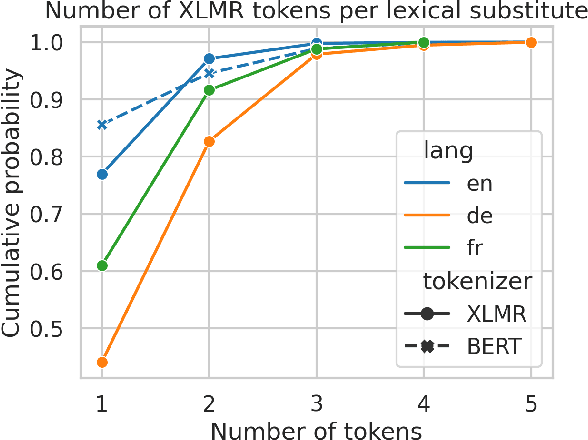
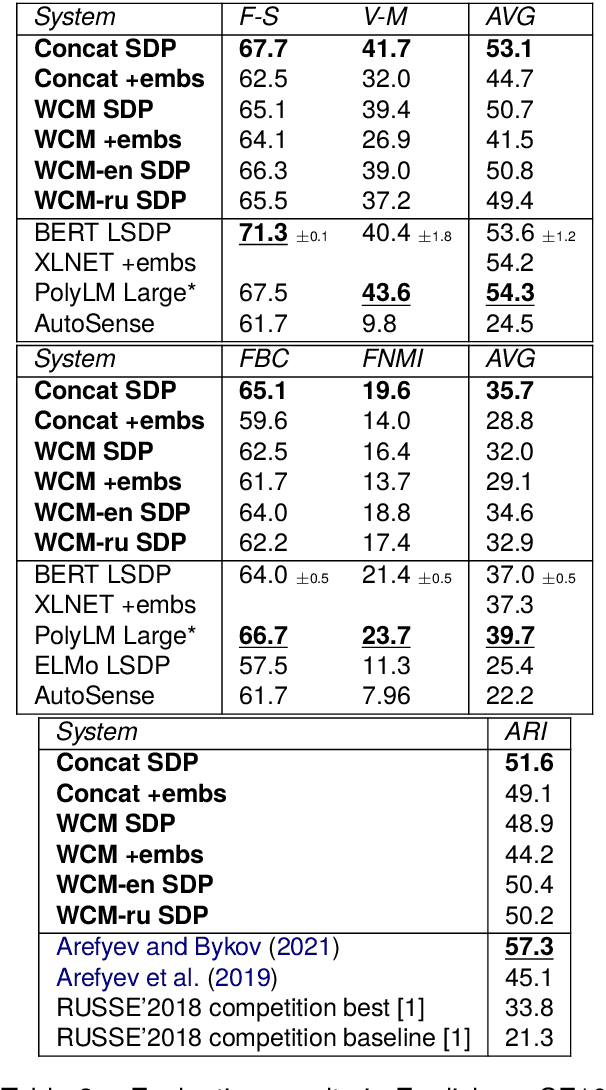
Word Sense Induction (WSI) is the task of discovering senses of an ambiguous word by grouping usages of this word into clusters corresponding to these senses. Many approaches were proposed to solve WSI in English and a few other languages, but these approaches are not easily adaptable to new languages. We present multilingual substitution-based WSI methods that support any of 100 languages covered by the underlying multilingual language model with minimal to no adaptation required. Despite the multilingual capabilities, our methods perform on par with the existing monolingual approaches on popular English WSI datasets. At the same time, they will be most useful for lower-resourced languages which miss lexical resources available for English, thus, have higher demand for unsupervised methods like WSI.
The LSCD Benchmark: a Testbed for Diachronic Word Meaning Tasks
Mar 29, 2024


Lexical Semantic Change Detection (LSCD) is a complex, lemma-level task, which is usually operationalized based on two subsequently applied usage-level tasks: First, Word-in-Context (WiC) labels are derived for pairs of usages. Then, these labels are represented in a graph on which Word Sense Induction (WSI) is applied to derive sense clusters. Finally, LSCD labels are derived by comparing sense clusters over time. This modularity is reflected in most LSCD datasets and models. It also leads to a large heterogeneity in modeling options and task definitions, which is exacerbated by a variety of dataset versions, preprocessing options and evaluation metrics. This heterogeneity makes it difficult to evaluate models under comparable conditions, to choose optimal model combinations or to reproduce results. Hence, we provide a benchmark repository standardizing LSCD evaluation. Through transparent implementation results become easily reproducible and by standardization different components can be freely combined. The repository reflects the task's modularity by allowing model evaluation for WiC, WSI and LSCD. This allows for careful evaluation of increasingly complex model components providing new ways of model optimization.
Enriching Word Usage Graphs with Cluster Definitions
Mar 26, 2024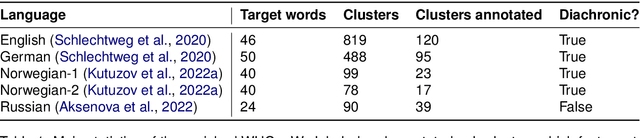
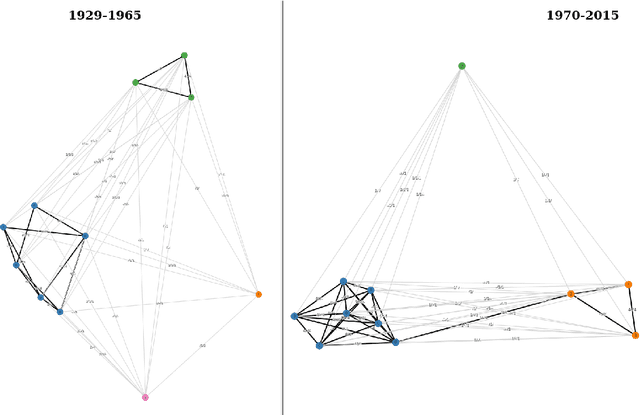


We present a dataset of word usage graphs (WUGs), where the existing WUGs for multiple languages are enriched with cluster labels functioning as sense definitions. They are generated from scratch by fine-tuned encoder-decoder language models. The conducted human evaluation has shown that these definitions match the existing clusters in WUGs better than the definitions chosen from WordNet by two baseline systems. At the same time, the method is straightforward to use and easy to extend to new languages. The resulting enriched datasets can be extremely helpful for moving on to explainable semantic change modeling.
A New Massive Multilingual Dataset for High-Performance Language Technologies
Mar 20, 2024We present the HPLT (High Performance Language Technologies) language resources, a new massive multilingual dataset including both monolingual and bilingual corpora extracted from CommonCrawl and previously unused web crawls from the Internet Archive. We describe our methods for data acquisition, management and processing of large corpora, which rely on open-source software tools and high-performance computing. Our monolingual collection focuses on low- to medium-resourced languages and covers 75 languages and a total of ~5.6 trillion word tokens de-duplicated on the document level. Our English-centric parallel corpus is derived from its monolingual counterpart and covers 18 language pairs and more than 96 million aligned sentence pairs with roughly 1.4 billion English tokens. The HPLT language resources are one of the largest open text corpora ever released, providing a great resource for language modeling and machine translation training. We publicly release the corpora, the software, and the tools used in this work.
Always Keep your Target in Mind: Studying Semantics and Improving Performance of Neural Lexical Substitution
Jun 07, 2022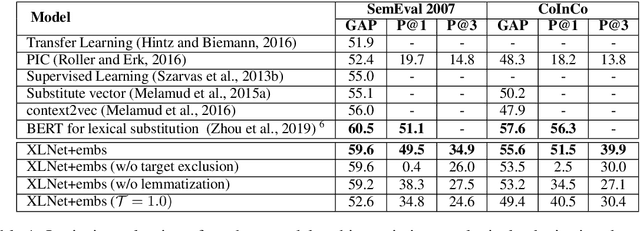
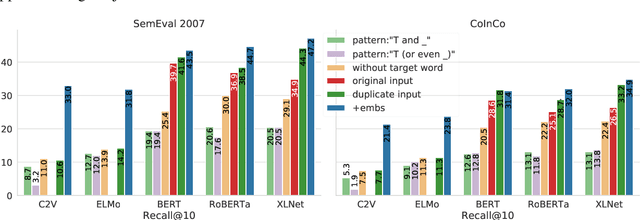
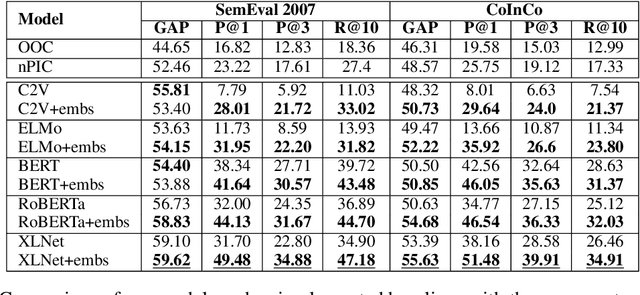
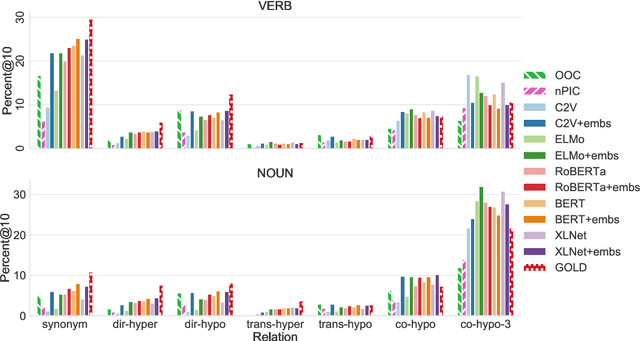
Lexical substitution, i.e. generation of plausible words that can replace a particular target word in a given context, is an extremely powerful technology that can be used as a backbone of various NLP applications, including word sense induction and disambiguation, lexical relation extraction, data augmentation, etc. In this paper, we present a large-scale comparative study of lexical substitution methods employing both rather old and most recent language and masked language models (LMs and MLMs), such as context2vec, ELMo, BERT, RoBERTa, XLNet. We show that already competitive results achieved by SOTA LMs/MLMs can be further substantially improved if information about the target word is injected properly. Several existing and new target word injection methods are compared for each LM/MLM using both intrinsic evaluation on lexical substitution datasets and extrinsic evaluation on word sense induction (WSI) datasets. On two WSI datasets we obtain new SOTA results. Besides, we analyze the types of semantic relations between target words and their substitutes generated by different models or given by annotators.
* arXiv admin note: text overlap with arXiv:2006.00031
BOS at LSCDiscovery: Lexical Substitution for Interpretable Lexical Semantic Change Detection
Jun 07, 2022
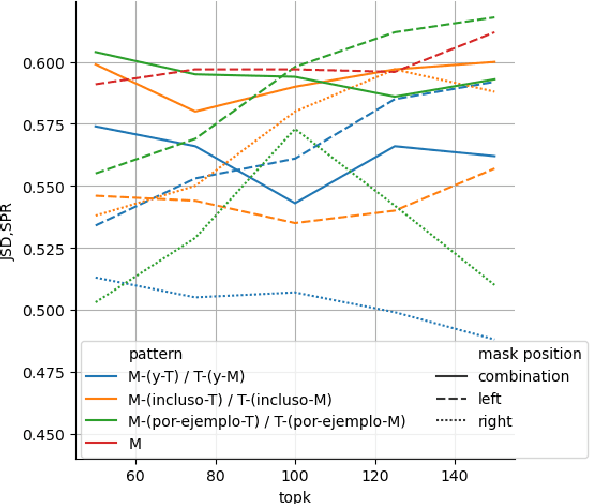


We propose a solution for the LSCDiscovery shared task on Lexical Semantic Change Detection in Spanish. Our approach is based on generating lexical substitutes that describe old and new senses of a given word. This approach achieves the second best result in sense loss and sense gain detection subtasks. By observing those substitutes that are specific for only one time period, one can understand which senses were obtained or lost. This allows providing more detailed information about semantic change to the user and makes our method interpretable.
The Document Vectors Using Cosine Similarity Revisited
May 26, 2022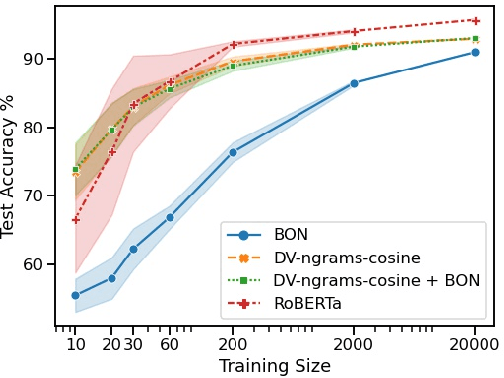

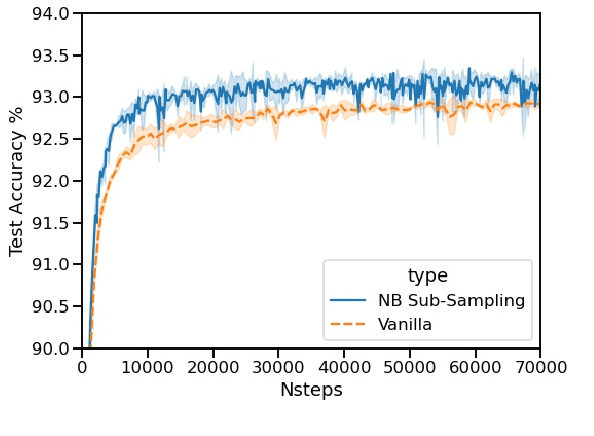
The current state-of-the-art test accuracy (97.42\%) on the IMDB movie reviews dataset was reported by \citet{thongtan-phienthrakul-2019-sentiment} and achieved by the logistic regression classifier trained on the Document Vectors using Cosine Similarity (DV-ngrams-cosine) proposed in their paper and the Bag-of-N-grams (BON) vectors scaled by Naive Bayesian weights. While large pre-trained Transformer-based models have shown SOTA results across many datasets and tasks, the aforementioned model has not been surpassed by them, despite being much simpler and pre-trained on the IMDB dataset only. In this paper, we describe an error in the evaluation procedure of this model, which was found when we were trying to analyze its excellent performance on the IMDB dataset. We further show that the previously reported test accuracy of 97.42\% is invalid and should be corrected to 93.68\%. We also analyze the model performance with different amounts of training data (subsets of the IMDB dataset) and compare it to the Transformer-based RoBERTa model. The results show that while RoBERTa has a clear advantage for larger training sets, the DV-ngrams-cosine performs better than RoBERTa when the labelled training set is very small (10 or 20 documents). Finally, we introduce a sub-sampling scheme based on Naive Bayesian weights for the training process of the DV-ngrams-cosine, which leads to faster training and better quality.