 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEuroGEST: Investigating gender stereotypes in multilingual language models
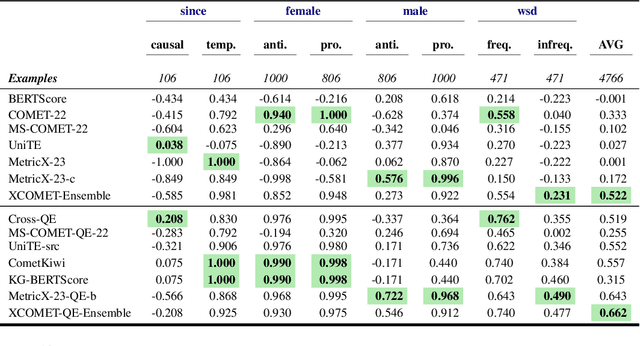
Jun 04, 2025Large language models increasingly support multiple languages, yet most benchmarks for gender bias remain English-centric. We introduce EuroGEST, a dataset designed to measure gender-stereotypical reasoning in LLMs across English and 29 European languages. EuroGEST builds on an existing expert-informed benchmark covering 16 gender stereotypes, expanded in this work using translation tools, quality estimation metrics, and morphological heuristics. Human evaluations confirm that our data generation method results in high accuracy of both translations and gender labels across languages. We use EuroGEST to evaluate 24 multilingual language models from six model families, demonstrating that the strongest stereotypes in all models across all languages are that women are 'beautiful', 'empathetic' and 'neat' and men are 'leaders', 'strong, tough' and 'professional'. We also show that larger models encode gendered stereotypes more strongly and that instruction finetuning does not consistently reduce gendered stereotypes. Our work highlights the need for more multilingual studies of fairness in LLMs and offers scalable methods and resources to audit gender bias across languages.
Can LLMs Detect Intrinsic Hallucinations in Paraphrasing and Machine Translation?
Apr 29, 2025A frequently observed problem with LLMs is their tendency to generate output that is nonsensical, illogical, or factually incorrect, often referred to broadly as hallucination. Building on the recently proposed HalluciGen task for hallucination detection and generation, we evaluate a suite of open-access LLMs on their ability to detect intrinsic hallucinations in two conditional generation tasks: translation and paraphrasing. We study how model performance varies across tasks and language and we investigate the impact of model size, instruction tuning, and prompt choice. We find that performance varies across models but is consistent across prompts. Finally, we find that NLI models perform comparably well, suggesting that LLM-based detectors are not the only viable option for this specific task.
SemEval-2025 Task 3: Mu-SHROOM, the Multilingual Shared Task on Hallucinations and Related Observable Overgeneration Mistakes
Apr 16, 2025We present the Mu-SHROOM shared task which is focused on detecting hallucinations and other overgeneration mistakes in the output of instruction-tuned large language models (LLMs). Mu-SHROOM addresses general-purpose LLMs in 14 languages, and frames the hallucination detection problem as a span-labeling task. We received 2,618 submissions from 43 participating teams employing diverse methodologies. The large number of submissions underscores the interest of the community in hallucination detection. We present the results of the participating systems and conduct an empirical analysis to identify key factors contributing to strong performance in this task. We also emphasize relevant current challenges, notably the varying degree of hallucinations across languages and the high annotator disagreement when labeling hallucination spans.
An Expanded Massive Multilingual Dataset for High-Performance Language Technologies
Mar 13, 2025


Training state-of-the-art large language models requires vast amounts of clean and diverse textual data. However, building suitable multilingual datasets remains a challenge. In this work, we present HPLT v2, a collection of high-quality multilingual monolingual and parallel corpora. The monolingual portion of the data contains 8T tokens covering 193 languages, while the parallel data contains 380M sentence pairs covering 51 languages. We document the entire data pipeline and release the code to reproduce it. We provide extensive analysis of the quality and characteristics of our data. Finally, we evaluate the performance of language models and machine translation systems trained on HPLT v2, demonstrating its value.
Machine Translation Meta Evaluation through Translation Accuracy Challenge Sets
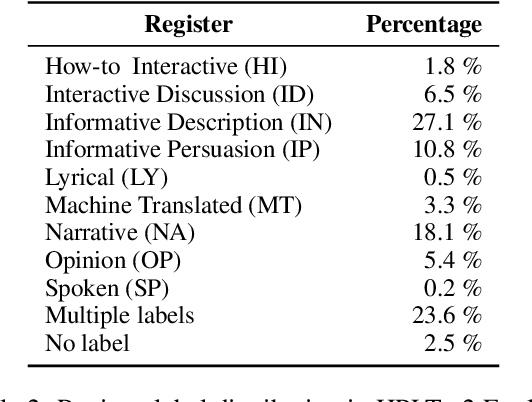
Jan 29, 2024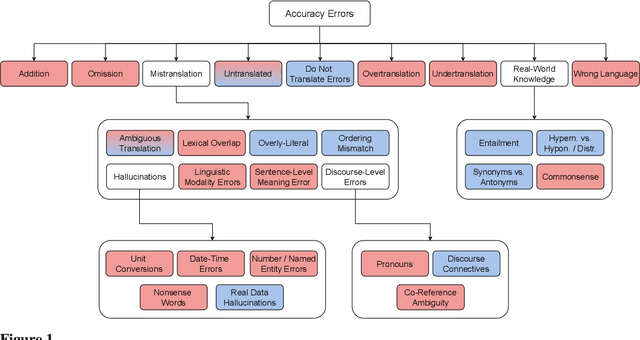

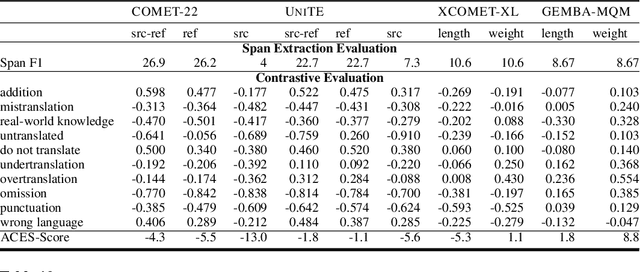
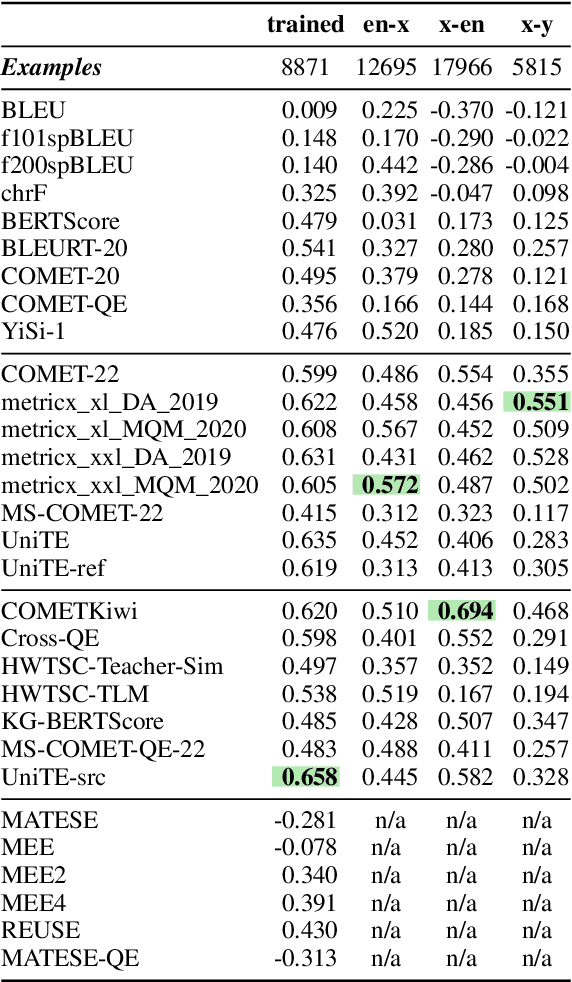
Recent machine translation (MT) metrics calibrate their effectiveness by correlating with human judgement but without any insights about their behaviour across different error types. Challenge sets are used to probe specific dimensions of metric behaviour but there are very few such datasets and they either focus on a limited number of phenomena or a limited number of language pairs. We introduce ACES, a contrastive challenge set spanning 146 language pairs, aimed at discovering whether metrics can identify 68 translation accuracy errors. These phenomena range from simple alterations at the word/character level to more complex errors based on discourse and real-world knowledge. We conduct a large-scale study by benchmarking ACES on 50 metrics submitted to the WMT 2022 and 2023 metrics shared tasks. We benchmark metric performance, assess their incremental performance over successive campaigns, and measure their sensitivity to a range of linguistic phenomena. We also investigate claims that Large Language Models (LLMs) are effective as MT evaluators by evaluating on ACES. Our results demonstrate that different metric families struggle with different phenomena and that LLM-based methods fail to demonstrate reliable performance. Our analyses indicate that most metrics ignore the source sentence, tend to prefer surface-level overlap and end up incorporating properties of base models which are not always beneficial. We expand ACES to include error span annotations, denoted as SPAN-ACES and we use this dataset to evaluate span-based error metrics showing these metrics also need considerable improvement. Finally, we provide a set of recommendations for building better MT metrics, including focusing on error labels instead of scores, ensembling, designing strategies to explicitly focus on the source sentence, focusing on semantic content and choosing the right base model for representations.
ACES: Translation Accuracy Challenge Sets at WMT 2023
Nov 02, 2023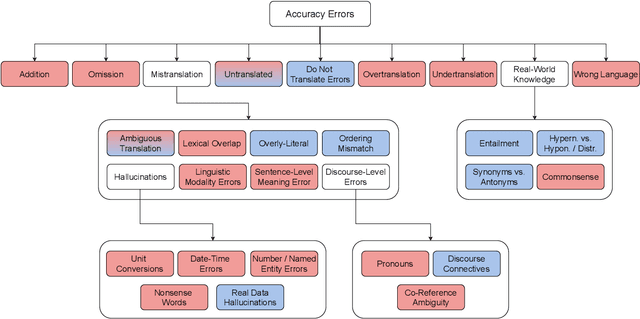


We benchmark the performance of segmentlevel metrics submitted to WMT 2023 using the ACES Challenge Set (Amrhein et al., 2022). The challenge set consists of 36K examples representing challenges from 68 phenomena and covering 146 language pairs. The phenomena range from simple perturbations at the word/character level to more complex errors based on discourse and real-world knowledge. For each metric, we provide a detailed profile of performance over a range of error categories as well as an overall ACES-Score for quick comparison. We also measure the incremental performance of the metrics submitted to both WMT 2023 and 2022. We find that 1) there is no clear winner among the metrics submitted to WMT 2023, and 2) performance change between the 2023 and 2022 versions of the metrics is highly variable. Our recommendations are similar to those from WMT 2022. Metric developers should focus on: building ensembles of metrics from different design families, developing metrics that pay more attention to the source and rely less on surface-level overlap, and carefully determining the influence of multilingual embeddings on MT evaluation.
MULTI3NLU++: A Multilingual, Multi-Intent, Multi-Domain Dataset for Natural Language Understanding in Task-Oriented Dialogue
Dec 20, 2022



Task-oriented dialogue (TOD) systems have been applied in a range of domains to support human users to achieve specific goals. Systems are typically constructed for a single domain or language and do not generalise well beyond this. Their extension to other languages in particular is restricted by the lack of available training data for many of the world's languages. To support work on Natural Language Understanding (NLU) in TOD across multiple languages and domains simultaneously, we constructed MULTI3NLU++, a multilingual, multi-intent, multi-domain dataset. MULTI3NLU++ extends the English-only NLU++ dataset to include manual translations into a range of high, medium and low resource languages (Spanish, Marathi, Turkish and Amharic), in two domains (banking and hotels). MULTI3NLU++ inherits the multi-intent property of NLU++, where an utterance may be labelled with multiple intents, providing a more realistic representation of a user's goals and aligning with the more complex tasks that commercial systems aim to model. We use MULTI3NLU++ to benchmark state-of-the-art multilingual language models as well as Machine Translation and Question Answering systems for the NLU task of intent detection for TOD systems in the multilingual setting. The results demonstrate the challenging nature of the dataset, particularly in the low-resource language setting.
ACES: Translation Accuracy Challenge Sets for Evaluating Machine Translation Metrics
Oct 27, 2022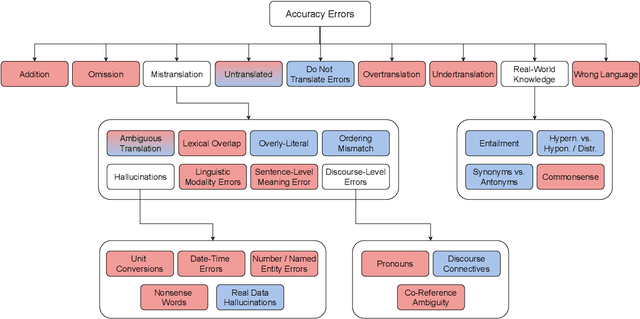
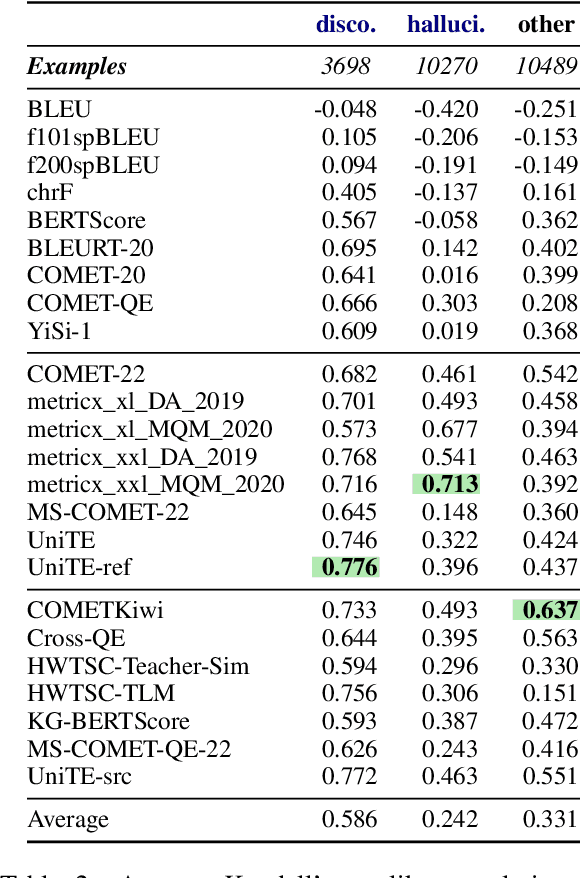
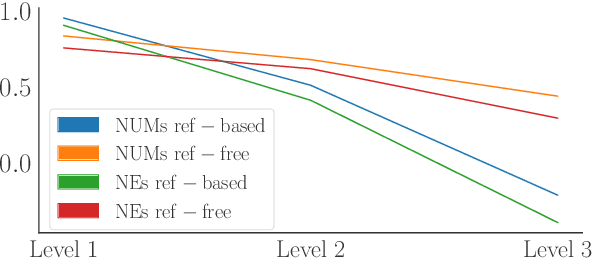
As machine translation (MT) metrics improve their correlation with human judgement every year, it is crucial to understand the limitations of such metrics at the segment level. Specifically, it is important to investigate metric behaviour when facing accuracy errors in MT because these can have dangerous consequences in certain contexts (e.g., legal, medical). We curate ACES, a translation accuracy challenge set, consisting of 68 phenomena ranging from simple perturbations at the word/character level to more complex errors based on discourse and real-world knowledge. We use ACES to evaluate a wide range of MT metrics including the submissions to the WMT 2022 metrics shared task and perform several analyses leading to general recommendations for metric developers. We recommend: a) combining metrics with different strengths, b) developing metrics that give more weight to the source and less to surface-level overlap with the reference and c) explicitly modelling additional language-specific information beyond what is available via multilingual embeddings.
Investigating the use of Paraphrase Generation for Question Reformulation in the FRANK QA system
Jun 06, 2022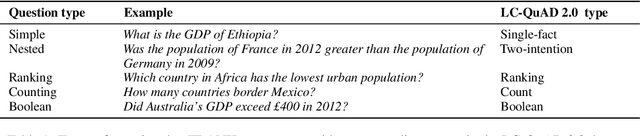
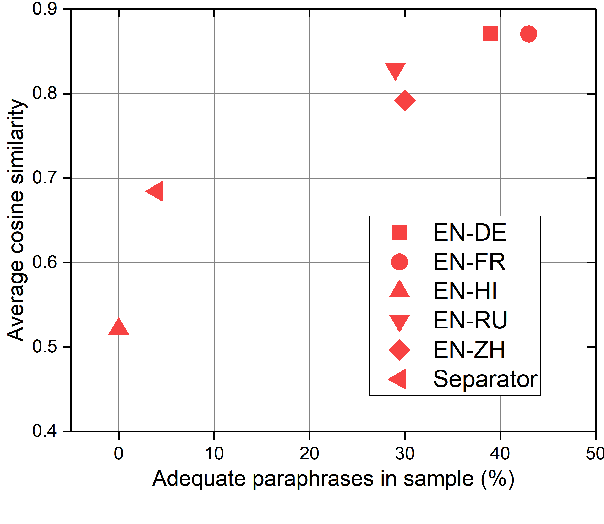

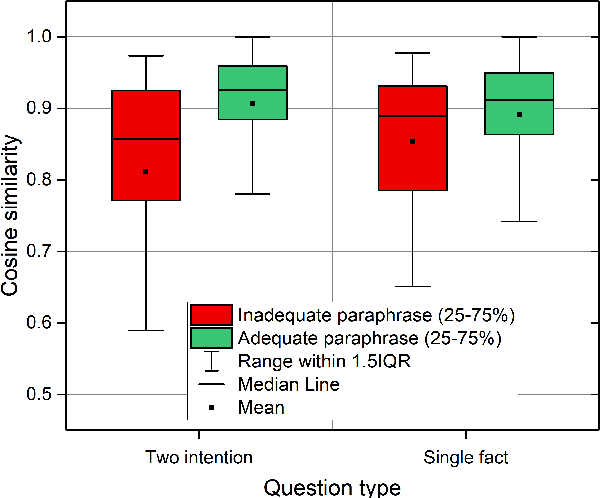
We present a study into the ability of paraphrase generation methods to increase the variety of natural language questions that the FRANK Question Answering system can answer. We first evaluate paraphrase generation methods on the LC-QuAD 2.0 dataset using both automatic metrics and human judgement, and discuss their correlation. Error analysis on the dataset is also performed using both automatic and manual approaches, and we discuss how paraphrase generation and evaluation is affected by data points which contain error. We then simulate an implementation of the best performing paraphrase generation method (an English-French backtranslation) into FRANK in order to test our original hypothesis, using a small challenge dataset. Our two main conclusions are that cleaning of LC-QuAD 2.0 is required as the errors present can affect evaluation; and that, due to limitations of FRANK's parser, paraphrase generation is not a method which we can rely on to improve the variety of natural language questions that FRANK can answer.
Cross-lingual Inference with A Chinese Entailment Graph
Mar 11, 2022
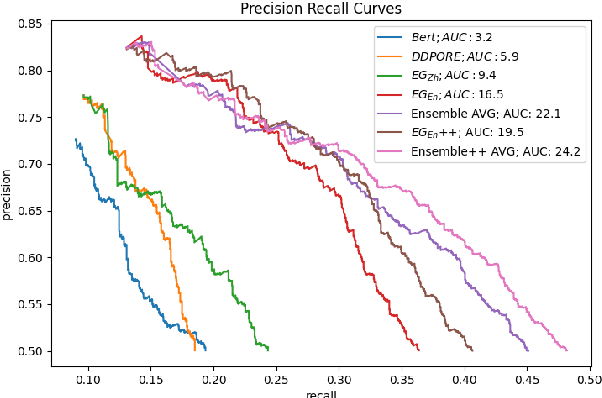
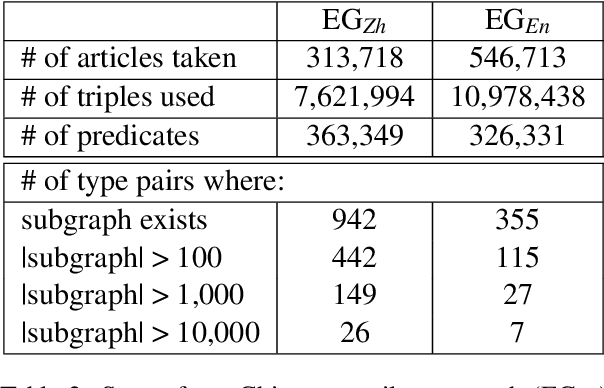
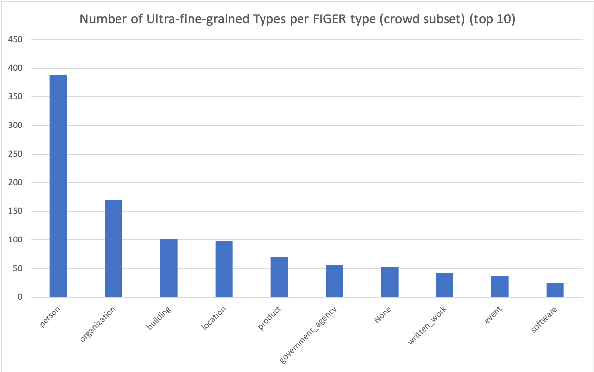
Predicate entailment detection is a crucial task for question-answering from text, where previous work has explored unsupervised learning of entailment graphs from typed open relation triples. In this paper, we present the first pipeline for building Chinese entailment graphs, which involves a novel high-recall open relation extraction (ORE) method and the first Chinese fine-grained entity typing dataset under the FIGER type ontology. Through experiments on the Levy-Holt dataset, we verify the strength of our Chinese entailment graph, and reveal the cross-lingual complementarity: on the parallel Levy-Holt dataset, an ensemble of Chinese and English entailment graphs outperforms both monolingual graphs, and raises unsupervised SOTA by 4.7 AUC points.