 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIETA: A Decoder-only transformer-based model for Italian-English machine TrAnslation
Jan 25, 2026In this paper, we present DIETA, a small, decoder-only Transformer model with 0.5 billion parameters, specifically designed and trained for Italian-English machine translation. We collect and curate a large parallel corpus consisting of approximately 207 million Italian-English sentence pairs across diverse domains, including parliamentary proceedings, legal texts, web-crawled content, subtitles, news, literature and 352 million back-translated data using pretrained models. Additionally, we create and release a new small-scale evaluation set, consisting of 450 sentences, based on 2025 WikiNews articles, enabling assessment of translation quality on contemporary text. Comprehensive evaluations show that DIETA achieves competitive performance on multiple Italian-English benchmarks, consistently ranking in the second quartile of a 32-system leaderboard and outperforming most other sub-3B models on four out of five test suites. The training script, trained models, curated corpus, and newly introduced evaluation set are made publicly available, facilitating further research and development in specialized Italian-English machine translation. https://github.com/pkasela/DIETA-Machine-Translation
Investigating Task Arithmetic for Zero-Shot Information Retrieval
May 01, 2025Large Language Models (LLMs) have shown impressive zero-shot performance across a variety of Natural Language Processing tasks, including document re-ranking. However, their effectiveness degrades on unseen tasks and domains, largely due to shifts in vocabulary and word distributions. In this paper, we investigate Task Arithmetic, a technique that combines the weights of LLMs pre-trained on different tasks or domains via simple mathematical operations, such as addition or subtraction, to adapt retrieval models without requiring additional fine-tuning. Our method is able to synthesize diverse tasks and domain knowledge into a single model, enabling effective zero-shot adaptation in different retrieval contexts. Extensive experiments on publicly available scientific, biomedical, and multilingual datasets show that our method improves state-of-the-art re-ranking performance by up to 18% in NDCG@10 and 15% in P@10. In addition to these empirical gains, our analysis provides insights into the strengths and limitations of Task Arithmetic as a practical strategy for zero-shot learning and model adaptation. We make our code publicly available at https://github.com/DetectiveMB/Task-Arithmetic-for-ZS-IR.
Reasoning Capabilities and Invariability of Large Language Models
May 01, 2025Large Language Models (LLMs) have shown remarkable capabilities in manipulating natural language across multiple applications, but their ability to handle simple reasoning tasks is often questioned. In this work, we aim to provide a comprehensive analysis of LLMs' reasoning competence, specifically focusing on their prompt dependency. In particular, we introduce a new benchmark dataset with a series of simple reasoning questions demanding shallow logical reasoning. Aligned with cognitive psychology standards, the questions are confined to a basic domain revolving around geometric figures, ensuring that responses are independent of any pre-existing intuition about the world and rely solely on deduction. An empirical analysis involving zero-shot and few-shot prompting across 24 LLMs of different sizes reveals that, while LLMs with over 70 billion parameters perform better in the zero-shot setting, there is still a large room for improvement. An additional test with chain-of-thought prompting over 22 LLMs shows that this additional prompt can aid or damage the performance of models, depending on whether the rationale is required before or after the answer.
SemEval-2025 Task 3: Mu-SHROOM, the Multilingual Shared Task on Hallucinations and Related Observable Overgeneration Mistakes
Apr 16, 2025We present the Mu-SHROOM shared task which is focused on detecting hallucinations and other overgeneration mistakes in the output of instruction-tuned large language models (LLMs). Mu-SHROOM addresses general-purpose LLMs in 14 languages, and frames the hallucination detection problem as a span-labeling task. We received 2,618 submissions from 43 participating teams employing diverse methodologies. The large number of submissions underscores the interest of the community in hallucination detection. We present the results of the participating systems and conduct an empirical analysis to identify key factors contributing to strong performance in this task. We also emphasize relevant current challenges, notably the varying degree of hallucinations across languages and the high annotator disagreement when labeling hallucination spans.
How to Blend Concepts in Diffusion Models
Jul 19, 2024For the last decade, there has been a push to use multi-dimensional (latent) spaces to represent concepts; and yet how to manipulate these concepts or reason with them remains largely unclear. Some recent methods exploit multiple latent representations and their connection, making this research question even more entangled. Our goal is to understand how operations in the latent space affect the underlying concepts. To that end, we explore the task of concept blending through diffusion models. Diffusion models are based on a connection between a latent representation of textual prompts and a latent space that enables image reconstruction and generation. This task allows us to try different text-based combination strategies, and evaluate easily through a visual analysis. Our conclusion is that concept blending through space manipulation is possible, although the best strategy depends on the context of the blend.
SemEval-2024 Shared Task 6: SHROOM, a Shared-task on Hallucinations and Related Observable Overgeneration Mistakes
Mar 20, 2024This paper presents the results of the SHROOM, a shared task focused on detecting hallucinations: outputs from natural language generation (NLG) systems that are fluent, yet inaccurate. Such cases of overgeneration put in jeopardy many NLG applications, where correctness is often mission-critical. The shared task was conducted with a newly constructed dataset of 4000 model outputs labeled by 5 annotators each, spanning 3 NLP tasks: machine translation, paraphrase generation and definition modeling. The shared task was tackled by a total of 58 different users grouped in 42 teams, out of which 27 elected to write a system description paper; collectively, they submitted over 300 prediction sets on both tracks of the shared task. We observe a number of key trends in how this approach was tackled -- many participants rely on a handful of model, and often rely either on synthetic data for fine-tuning or zero-shot prompting strategies. While a majority of the teams did outperform our proposed baseline system, the performances of top-scoring systems are still consistent with a random handling of the more challenging items.
MAMMOTH: Massively Multilingual Modular Open Translation @ Helsinki
Mar 12, 2024



NLP in the age of monolithic large language models is approaching its limits in terms of size and information that can be handled. The trend goes to modularization, a necessary step into the direction of designing smaller sub-networks and components with specialized functionality. In this paper, we present the MAMMOTH toolkit: a framework designed for training massively multilingual modular machine translation systems at scale, initially derived from OpenNMT-py and then adapted to ensure efficient training across computation clusters. We showcase its efficiency across clusters of A100 and V100 NVIDIA GPUs, and discuss our design philosophy and plans for future information. The toolkit is publicly available online.
Democratizing Machine Translation with OPUS-MT
Dec 04, 2022This paper presents the OPUS ecosystem with a focus on the development of open machine translation models and tools, and their integration into end-user applications, development platforms and professional workflows. We discuss our on-going mission of increasing language coverage and translation quality, and also describe on-going work on the development of modular translation models and speed-optimized compact solutions for real-time translation on regular desktops and small devices.
XL-WiC: A Multilingual Benchmark for Evaluating Semantic Contextualization
Oct 13, 2020
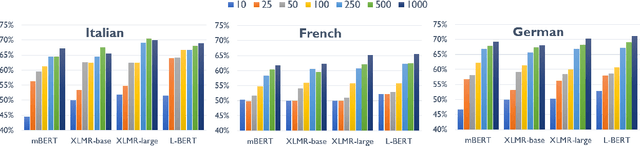

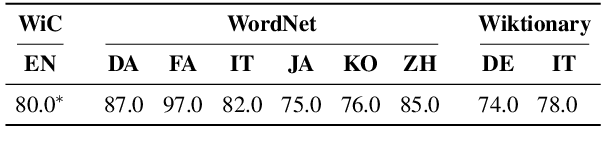
The ability to correctly model distinct meanings of a word is crucial for the effectiveness of semantic representation techniques. However, most existing evaluation benchmarks for assessing this criterion are tied to sense inventories (usually WordNet), restricting their usage to a small subset of knowledge-based representation techniques. The Word-in-Context dataset (WiC) addresses the dependence on sense inventories by reformulating the standard disambiguation task as a binary classification problem; but, it is limited to the English language. We put forward a large multilingual benchmark, XL-WiC, featuring gold standards in 12 new languages from varied language families and with different degrees of resource availability, opening room for evaluation scenarios such as zero-shot cross-lingual transfer. We perform a series of experiments to determine the reliability of the datasets and to set performance baselines for several recent contextualized multilingual models. Experimental results show that even when no tagged instances are available for a target language, models trained solely on the English data can attain competitive performance in the task of distinguishing different meanings of a word, even for distant languages. XL-WiC is available at https://pilehvar.github.io/xlwic/.
Fixed Encoder Self-Attention Patterns in Transformer-Based Machine Translation
Feb 24, 2020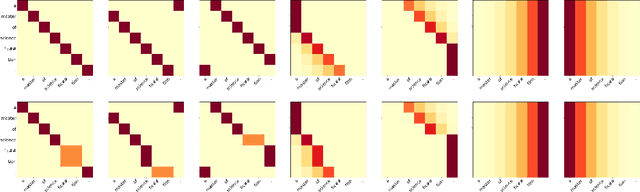

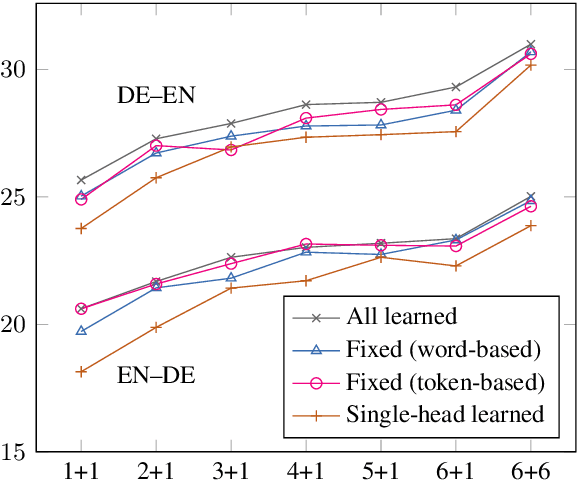

Transformer-based models have brought a radical change to neural machine translation. A key feature of the Transformer architecture is the so-called multi-head attention mechanism, which allows the model to focus simultaneously on different parts of the input. However, recent works have shown that attention heads learn simple positional patterns which are often redundant. In this paper, we propose to replace all but one attention head of each encoder layer with fixed -- non-learnable -- attentive patterns that are solely based on position and do not require any external knowledge. Our experiments show that fixing the attention heads on the encoder side of the Transformer at training time does not impact the translation quality and even increases BLEU scores by up to 3 points in low-resource scenarios.