 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the limited utility of parallel data for learning shared multilingual representations
Mar 30, 2026Shared multilingual representations are essential for cross-lingual tasks and knowledge transfer across languages. This study looks at the impact of parallel data, i.e. translated sentences, in pretraining as a signal to trigger representations that are aligned across languages. We train reference models with different proportions of parallel data and show that parallel data seem to have only a minimal effect on the cross-lingual alignment. Based on multiple evaluation methods, we find that the effect is limited to potentially accelerating the representation sharing in the early phases of pretraining, and to decreasing the amount of language-specific neurons in the model. Cross-lingual alignment seems to emerge on similar levels even without the explicit signal from parallel data.
Life Cycle-Aware Evaluation of Knowledge Distillation for Machine Translation: Environmental Impact and Translation Quality Trade-offs
Feb 10, 2026Knowledge distillation (KD) is a tool to compress a larger system (teacher) into a smaller one (student). In machine translation, studies typically report only the translation quality of the student and omit the computational complexity of performing KD, making it difficult to select among the many available KD choices under compute-induced constraints. In this study, we evaluate representative KD methods by considering both translation quality and computational cost. We express computational cost as a carbon footprint using the machine learning life cycle assessment (MLCA) tool. This assessment accounts for runtime operational emissions and amortized hardware production costs throughout the KD model life cycle (teacher training, distillation, and inference). We find that (i) distillation overhead dominates the total footprint at small deployment volumes, (ii) inference dominates at scale, making KD beneficial only beyond a task-dependent usage threshold, and (iii) word-level distillation typically offers more favorable footprint-quality trade-offs than sequence-level distillation. Our protocol provides reproducible guidance for selecting KD methods under explicit quality and compute-induced constraints.
Scaling Low-Resource MT via Synthetic Data Generation with LLMs
May 20, 2025



We investigate the potential of LLM-generated synthetic data for improving low-resource machine translation (MT). Focusing on seven diverse target languages, we construct a document-level synthetic corpus from English Europarl, and extend it via pivoting to 147 additional language pairs. Automatic and human evaluation confirm its high overall quality. We study its practical application by (i) identifying effective training regimes, (ii) comparing our data with the HPLT dataset, and (iii) testing its utility beyond English-centric MT. Finally, we introduce SynOPUS, a public repository for synthetic parallel datasets. Our findings show that LLM-generated synthetic data, even when noisy, can substantially improve MT performance for low-resource languages.
SemEval-2025 Task 3: Mu-SHROOM, the Multilingual Shared Task on Hallucinations and Related Observable Overgeneration Mistakes
Apr 16, 2025We present the Mu-SHROOM shared task which is focused on detecting hallucinations and other overgeneration mistakes in the output of instruction-tuned large language models (LLMs). Mu-SHROOM addresses general-purpose LLMs in 14 languages, and frames the hallucination detection problem as a span-labeling task. We received 2,618 submissions from 43 participating teams employing diverse methodologies. The large number of submissions underscores the interest of the community in hallucination detection. We present the results of the participating systems and conduct an empirical analysis to identify key factors contributing to strong performance in this task. We also emphasize relevant current challenges, notably the varying degree of hallucinations across languages and the high annotator disagreement when labeling hallucination spans.
GlotEval: A Test Suite for Massively Multilingual Evaluation of Large Language Models
Apr 05, 2025Large language models (LLMs) are advancing at an unprecedented pace globally, with regions increasingly adopting these models for applications in their primary language. Evaluation of these models in diverse linguistic environments, especially in low-resource languages, has become a major challenge for academia and industry. Existing evaluation frameworks are disproportionately focused on English and a handful of high-resource languages, thereby overlooking the realistic performance of LLMs in multilingual and lower-resource scenarios. To address this gap, we introduce GlotEval, a lightweight framework designed for massively multilingual evaluation. Supporting seven key tasks (machine translation, text classification, summarization, open-ended generation, reading comprehension, sequence labeling, and intrinsic evaluation), spanning over dozens to hundreds of languages, GlotEval highlights consistent multilingual benchmarking, language-specific prompt templates, and non-English-centric machine translation. This enables a precise diagnosis of model strengths and weaknesses in diverse linguistic contexts. A multilingual translation case study demonstrates GlotEval's applicability for multilingual and language-specific evaluations.
Rethinking Multilingual Continual Pretraining: Data Mixing for Adapting LLMs Across Languages and Resources
Apr 05, 2025Large Language Models (LLMs) exhibit significant disparities in performance across languages, primarily benefiting high-resource languages while marginalizing underrepresented ones. Continual Pretraining (CPT) has emerged as a promising approach to address this imbalance, although the relative effectiveness of monolingual, bilingual, and code-augmented data strategies remains unclear. This study systematically evaluates 36 CPT configurations involving three multilingual base models, across 30+ languages categorized as altruistic, selfish, and stagnant, spanning various resource levels. Our findings reveal three major insights: (1) Bilingual CPT improves multilingual classification but often causes language mixing issues during generation. (2) Including programming code data during CPT consistently enhances multilingual classification accuracy, particularly benefiting low-resource languages, but introduces a trade-off by slightly degrading generation quality. (3) Contrary to prior work, we observe substantial deviations from language classifications according to their impact on cross-lingual transfer: Languages classified as altruistic often negatively affect related languages, selfish languages show conditional and configuration-dependent behavior, and stagnant languages demonstrate surprising adaptability under certain CPT conditions. These nuanced interactions emphasize the complexity of multilingual representation learning, underscoring the importance of systematic studies on generalizable language classification to inform future multilingual CPT strategies.
EMMA-500: Enhancing Massively Multilingual Adaptation of Large Language Models
Sep 26, 2024



In this work, we introduce EMMA-500, a large-scale multilingual language model continue-trained on texts across 546 languages designed for enhanced multilingual performance, focusing on improving language coverage for low-resource languages. To facilitate continual pre-training, we compile the MaLA corpus, a comprehensive multilingual dataset enriched with curated datasets across diverse domains. Leveraging this corpus, we conduct extensive continual pre-training of the Llama 2 7B model, resulting in EMMA-500, which demonstrates robust performance across a wide collection of benchmarks, including a comprehensive set of multilingual tasks and PolyWrite, an open-ended generation benchmark developed in this study. Our results highlight the effectiveness of continual pre-training in expanding large language models' language capacity, particularly for underrepresented languages, demonstrating significant gains in cross-lingual transfer, task generalization, and language adaptability.
Two Stacks Are Better Than One: A Comparison of Language Modeling and Translation as Multilingual Pretraining Objectives
Jul 22, 2024



Pretrained language models (PLMs) display impressive performances and have captured the attention of the NLP community. Establishing the best practices in pretraining has therefore become a major point of focus for much of NLP research -- especially since the insights developed for monolingual English models need not carry to more complex multilingual. One significant caveat of the current state of the art is that different works are rarely comparable: they often discuss different parameter counts, training data, and evaluation methodology. This paper proposes a comparison of multilingual pretraining objectives in a controlled methodological environment. We ensure that training data and model architectures are comparable, and discuss the downstream performances across 6 languages that we observe in probing and fine-tuning scenarios. We make two key observations: (1) the architecture dictates which pretraining objective is optimal; (2) multilingual translation is a very effective pre-training objective under the right conditions. We make our code, data, and model weights available at \texttt{\url{https://github.com/Helsinki-NLP/lm-vs-mt}}.
Can Machine Translation Bridge Multilingual Pretraining and Cross-lingual Transfer Learning?
Mar 25, 2024
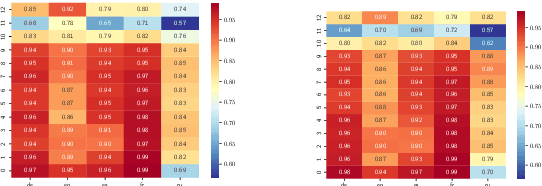

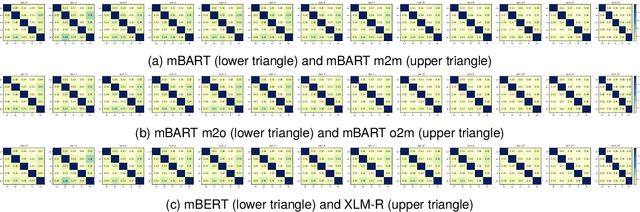
Multilingual pretraining and fine-tuning have remarkably succeeded in various natural language processing tasks. Transferring representations from one language to another is especially crucial for cross-lingual learning. One can expect machine translation objectives to be well suited to fostering such capabilities, as they involve the explicit alignment of semantically equivalent sentences from different languages. This paper investigates the potential benefits of employing machine translation as a continued training objective to enhance language representation learning, bridging multilingual pretraining and cross-lingual applications. We study this question through two lenses: a quantitative evaluation of the performance of existing models and an analysis of their latent representations. Our results show that, contrary to expectations, machine translation as the continued training fails to enhance cross-lingual representation learning in multiple cross-lingual natural language understanding tasks. We conclude that explicit sentence-level alignment in the cross-lingual scenario is detrimental to cross-lingual transfer pretraining, which has important implications for future cross-lingual transfer studies. We furthermore provide evidence through similarity measures and investigation of parameters that this lack of positive influence is due to output separability -- which we argue is of use for machine translation but detrimental elsewhere.
A New Massive Multilingual Dataset for High-Performance Language Technologies
Mar 20, 2024We present the HPLT (High Performance Language Technologies) language resources, a new massive multilingual dataset including both monolingual and bilingual corpora extracted from CommonCrawl and previously unused web crawls from the Internet Archive. We describe our methods for data acquisition, management and processing of large corpora, which rely on open-source software tools and high-performance computing. Our monolingual collection focuses on low- to medium-resourced languages and covers 75 languages and a total of ~5.6 trillion word tokens de-duplicated on the document level. Our English-centric parallel corpus is derived from its monolingual counterpart and covers 18 language pairs and more than 96 million aligned sentence pairs with roughly 1.4 billion English tokens. The HPLT language resources are one of the largest open text corpora ever released, providing a great resource for language modeling and machine translation training. We publicly release the corpora, the software, and the tools used in this work.