 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Do More Experts Fail? A Theoretical Analysis of Model Merging
May 27, 2025


Model merging dramatically reduces storage and computational resources by combining multiple expert models into a single multi-task model. Although recent model merging methods have shown promising results, they struggle to maintain performance gains as the number of merged models increases. In this paper, we investigate the key obstacles that limit the scalability of model merging when integrating a large number of expert models. First, we prove that there is an upper bound on model merging. Further theoretical analysis reveals that the limited effective parameter space imposes a strict constraint on the number of models that can be successfully merged. Gaussian Width shows that the marginal benefit of merging additional models diminishes according to a strictly concave function. This implies that the effective parameter space becomes rapidly saturated as the number of merged models increases. Furthermore, using Approximate Kinematics Theory, we prove the existence of a unique optimal threshold beyond which adding more models does not yield significant performance improvements. At the same time, we introduce a straightforward Reparameterized Heavy-Tailed method (RHT) to extend the coverage of the merged model, thereby enhancing its performance. Empirical results on 12 benchmarks, including both knowledge-intensive and general-purpose tasks, validate our theoretical analysis. We believe that these results spark further research beyond the current scope of model merging. The source code is in the anonymous Github repository https://github.com/wzj1718/ModelMergingAnalysis.
GlotEval: A Test Suite for Massively Multilingual Evaluation of Large Language Models
Apr 05, 2025Large language models (LLMs) are advancing at an unprecedented pace globally, with regions increasingly adopting these models for applications in their primary language. Evaluation of these models in diverse linguistic environments, especially in low-resource languages, has become a major challenge for academia and industry. Existing evaluation frameworks are disproportionately focused on English and a handful of high-resource languages, thereby overlooking the realistic performance of LLMs in multilingual and lower-resource scenarios. To address this gap, we introduce GlotEval, a lightweight framework designed for massively multilingual evaluation. Supporting seven key tasks (machine translation, text classification, summarization, open-ended generation, reading comprehension, sequence labeling, and intrinsic evaluation), spanning over dozens to hundreds of languages, GlotEval highlights consistent multilingual benchmarking, language-specific prompt templates, and non-English-centric machine translation. This enables a precise diagnosis of model strengths and weaknesses in diverse linguistic contexts. A multilingual translation case study demonstrates GlotEval's applicability for multilingual and language-specific evaluations.
Understanding In-Context Machine Translation for Low-Resource Languages: A Case Study on Manchu
Feb 17, 2025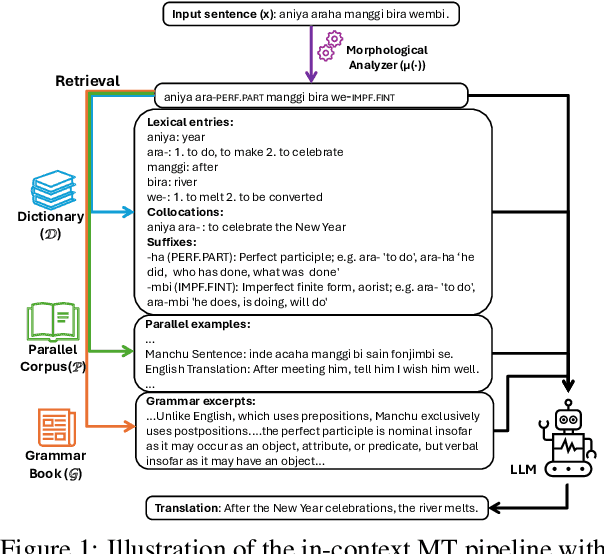
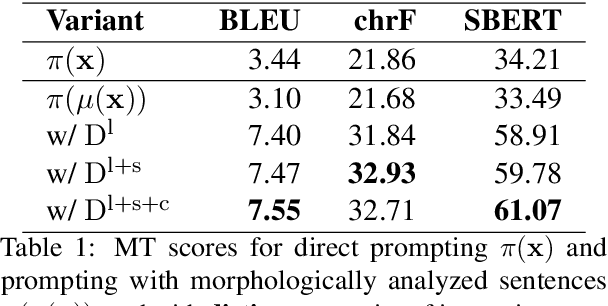
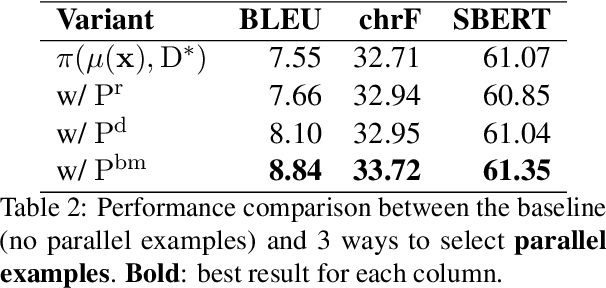
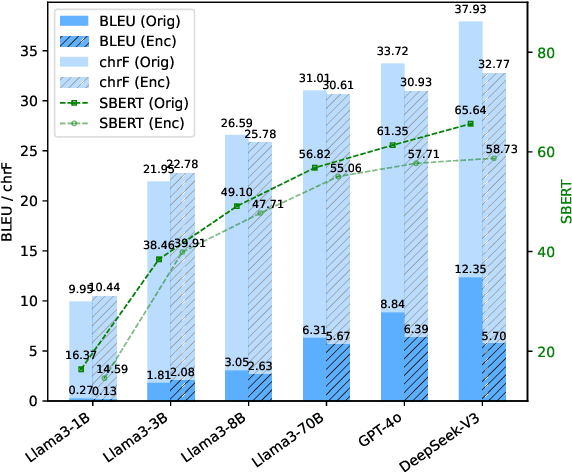
In-context machine translation (MT) with large language models (LLMs) is a promising approach for low-resource MT, as it can readily take advantage of linguistic resources such as grammar books and dictionaries. Such resources are usually selectively integrated into the prompt so that LLMs can directly perform translation without any specific training, via their in-context learning capability (ICL). However, the relative importance of each type of resource e.g., dictionary, grammar book, and retrieved parallel examples, is not entirely clear. To address this gap, this study systematically investigates how each resource and its quality affects the translation performance, with the Manchu language as our case study. To remove any prior knowledge of Manchu encoded in the LLM parameters and single out the effect of ICL, we also experiment with an encrypted version of Manchu texts. Our results indicate that high-quality dictionaries and good parallel examples are very helpful, while grammars hardly help. In a follow-up study, we showcase a promising application of in-context MT: parallel data augmentation as a way to bootstrap the conventional MT model. When monolingual data abound, generating synthetic parallel data through in-context MT offers a pathway to mitigate data scarcity and build effective and efficient low-resource neural MT systems.
SSMLoRA: Enhancing Low-Rank Adaptation with State Space Model
Feb 07, 2025Fine-tuning is a key approach for adapting language models to specific downstream tasks, but updating all model parameters becomes impractical as model sizes increase. Parameter-Efficient Fine-Tuning (PEFT) methods, such as Low-Rank Adaptation (LoRA), address this challenge by introducing additional adaptation parameters into pre-trained weight matrices. However, LoRA's performance varies across different insertion points within the model, highlighting potential parameter inefficiency due to unnecessary insertions. To this end, we propose SSMLoRA (State Space Model Low-Rank Adaptation), an extension of LoRA that incorporates a State Space Model (SSM) to interconnect low-rank matrices. SSMLoRA ensures that performance is maintained even with sparser insertions. SSMLoRA allows the model to not only map inputs to a low-rank space for better feature extraction but also leverage the computations from the previous low-rank space. Our method achieves comparable performance to LoRA on the General Language Understanding Evaluation (GLUE) benchmark while using only half the parameters. Additionally, due to its structure, SSMLoRA shows promise in handling tasks with longer input sequences. .You can find our code here:https://github.com/yuhkalhic/SSMLoRA.
EMMA-500: Enhancing Massively Multilingual Adaptation of Large Language Models
Sep 26, 2024



In this work, we introduce EMMA-500, a large-scale multilingual language model continue-trained on texts across 546 languages designed for enhanced multilingual performance, focusing on improving language coverage for low-resource languages. To facilitate continual pre-training, we compile the MaLA corpus, a comprehensive multilingual dataset enriched with curated datasets across diverse domains. Leveraging this corpus, we conduct extensive continual pre-training of the Llama 2 7B model, resulting in EMMA-500, which demonstrates robust performance across a wide collection of benchmarks, including a comprehensive set of multilingual tasks and PolyWrite, an open-ended generation benchmark developed in this study. Our results highlight the effectiveness of continual pre-training in expanding large language models' language capacity, particularly for underrepresented languages, demonstrating significant gains in cross-lingual transfer, task generalization, and language adaptability.
A Recipe of Parallel Corpora Exploitation for Multilingual Large Language Models
Jun 29, 2024Recent studies have highlighted the potential of exploiting parallel corpora to enhance multilingual large language models, improving performance in both bilingual tasks, e.g., machine translation, and general-purpose tasks, e.g., text classification. Building upon these findings, our comprehensive study aims to identify the most effective strategies for leveraging parallel corpora. We investigate the impact of parallel corpora quality and quantity, training objectives, and model size on the performance of multilingual large language models enhanced with parallel corpora across diverse languages and tasks. Our analysis reveals several key insights: (i) filtering noisy translations is essential for effectively exploiting parallel corpora, while language identification and short sentence filtering have little effect; (ii) even a corpus containing just 10K parallel sentences can yield results comparable to those obtained from much larger datasets; (iii) employing only the machine translation objective yields the best results among various training objectives and their combinations; (iv) larger multilingual language models benefit more from parallel corpora than smaller models due to their stronger capacity for cross-task transfer. Our study offers valuable insights into the optimal utilization of parallel corpora to enhance multilingual large language models, extending the generalizability of previous findings from limited languages and tasks to a broader range of scenarios.
XAMPLER: Learning to Retrieve Cross-Lingual In-Context Examples
May 08, 2024Recent studies have shown that leveraging off-the-shelf or fine-tuned retrievers, capable of retrieving high-quality in-context examples, significantly improves in-context learning of English. However, adapting these methods to other languages, especially low-resource ones, presents challenges due to the scarcity of available cross-lingual retrievers and annotated data. In this paper, we introduce XAMPLER: Cross-Lingual Example Retrieval, a method tailored to tackle the challenge of cross-lingual in-context learning using only annotated English data. XAMPLER first trains a retriever with positive/negative English samples, which are constructed based on the predictions of the multilingual large language model for in-context learning. Then, the trained retriever is directly employed to retrieve English examples as few-shot examples for in-context learning of target languages. Experiments on the massively multilingual text classification benchmark of SIB200 with 176 languages demonstrate that XAMPLER substantially improves the in-context learning performance across languages. Our code is available at https://github.com/cisnlp/XAMPLER.
MaLA-500: Massive Language Adaptation of Large Language Models
Jan 24, 2024Large language models have advanced the state of the art in natural language processing. However, their predominant design for English or a limited set of languages creates a substantial gap in their effectiveness for low-resource languages. To bridge this gap, we introduce MaLA-500, a novel large language model designed to cover an extensive range of 534 languages. To train MaLA-500, we employ vocabulary extension and continued pretraining on LLaMA 2 with Glot500-c. Our experiments on SIB-200 show that MaLA-500 achieves state-of-the-art in-context learning results. We release MaLA-500 at https://huggingface.co/MaLA-LM
OFA: A Framework of Initializing Unseen Subword Embeddings for Efficient Large-scale Multilingual Continued Pretraining
Nov 15, 2023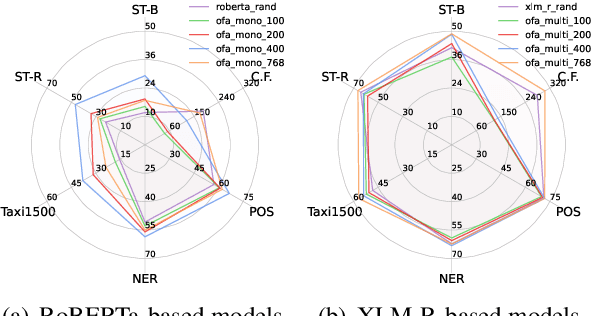
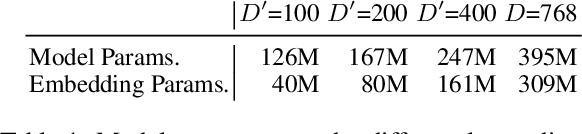
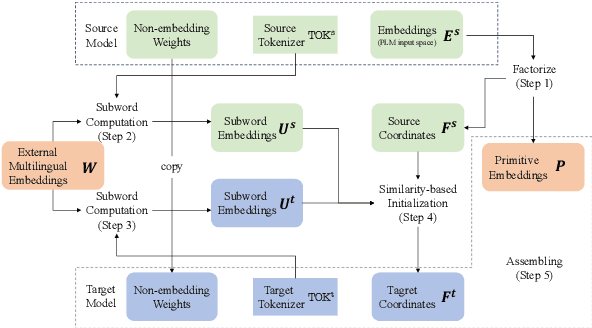
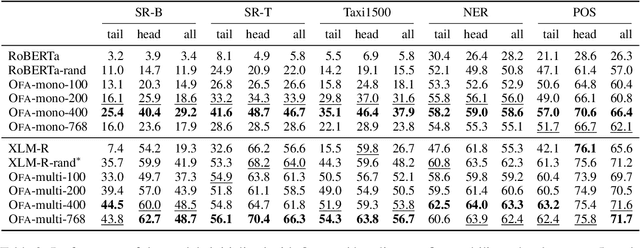
Pretraining multilingual language models from scratch requires considerable computational resources and substantial training data. Therefore, a more efficient method is to adapt existing pretrained language models (PLMs) to new languages via vocabulary extension and continued pretraining. However, this method usually randomly initializes the embeddings of new subwords and introduces substantially more embedding parameters to the language model, thus weakening the efficiency. To address these issues, we propose a novel framework: \textbf{O}ne \textbf{F}or \textbf{A}ll (\textbf{\textsc{Ofa}}), which wisely initializes the embeddings of unseen subwords from target languages and thus can adapt a PLM to multiple languages efficiently and effectively. \textsc{Ofa} takes advantage of external well-aligned multilingual word embeddings and injects the alignment knowledge into the new embeddings. In addition, \textsc{Ofa} applies matrix factorization and replaces the cumbersome embeddings with two lower-dimensional matrices, which significantly reduces the number of parameters while not sacrificing the performance. Through extensive experiments, we show models initialized by \textsc{Ofa} are efficient and outperform several baselines. \textsc{Ofa} not only accelerates the convergence of continued pretraining, which is friendly to a limited computation budget, but also improves the zero-shot crosslingual transfer on a wide range of downstream tasks. We make our code and models publicly available.
Universal NER: A Gold-Standard Multilingual Named Entity Recognition Benchmark
Nov 15, 2023
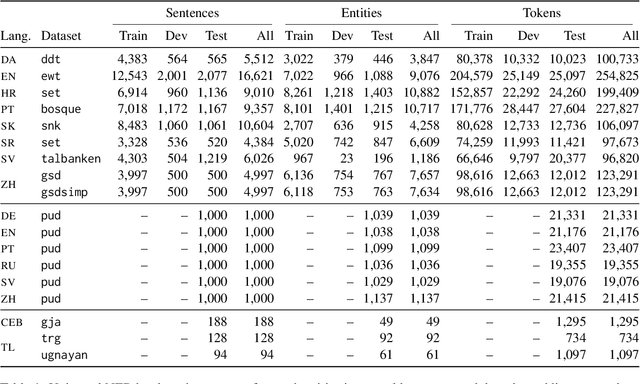


We introduce Universal NER (UNER), an open, community-driven project to develop gold-standard NER benchmarks in many languages. The overarching goal of UNER is to provide high-quality, cross-lingually consistent annotations to facilitate and standardize multilingual NER research. UNER v1 contains 18 datasets annotated with named entities in a cross-lingual consistent schema across 12 diverse languages. In this paper, we detail the dataset creation and composition of UNER; we also provide initial modeling baselines on both in-language and cross-lingual learning settings. We release the data, code, and fitted models to the public.