 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocate, Steer, and Improve: A Practical Survey of Actionable Mechanistic Interpretability in Large Language Models
Jan 20, 2026Mechanistic Interpretability (MI) has emerged as a vital approach to demystify the opaque decision-making of Large Language Models (LLMs). However, existing reviews primarily treat MI as an observational science, summarizing analytical insights while lacking a systematic framework for actionable intervention. To bridge this gap, we present a practical survey structured around the pipeline: "Locate, Steer, and Improve." We formally categorize Localizing (diagnosis) and Steering (intervention) methods based on specific Interpretable Objects to establish a rigorous intervention protocol. Furthermore, we demonstrate how this framework enables tangible improvements in Alignment, Capability, and Efficiency, effectively operationalizing MI as an actionable methodology for model optimization. The curated paper list of this work is available at https://github.com/rattlesnakey/Awesome-Actionable-MI-Survey.
SAD: A Large-Scale Strategic Argumentative Dialogue Dataset
Jan 12, 2026Argumentation generation has attracted substantial research interest due to its central role in human reasoning and decision-making. However, most existing argumentative corpora focus on non-interactive, single-turn settings, either generating arguments from a given topic or refuting an existing argument. In practice, however, argumentation is often realized as multi-turn dialogue, where speakers defend their stances and employ diverse argumentative strategies to strengthen persuasiveness. To support deeper modeling of argumentation dialogue, we present the first large-scale \textbf{S}trategic \textbf{A}rgumentative \textbf{D}ialogue dataset, SAD, consisting of 392,822 examples. Grounded in argumentation theories, we annotate each utterance with five strategy types, allowing multiple strategies per utterance. Unlike prior datasets, SAD requires models to generate contextually appropriate arguments conditioned on the dialogue history, a specified stance on the topic, and targeted argumentation strategies. We further benchmark a range of pretrained generative models on SAD and present in-depth analysis of strategy usage patterns in argumentation.
PlaM: Training-Free Plateau-Guided Model Merging for Better Visual Grounding in MLLMs
Jan 12, 2026Multimodal Large Language Models (MLLMs) rely on strong linguistic reasoning inherited from their base language models. However, multimodal instruction fine-tuning paradoxically degrades this text's reasoning capability, undermining multimodal performance. To address this issue, we propose a training-free framework to mitigate this degradation. Through layer-wise vision token masking, we reveal a common three-stage pattern in multimodal large language models: early-modal separation, mid-modal alignment, and late-modal degradation. By analyzing the behavior of MLLMs at different stages, we propose a plateau-guided model merging method that selectively injects base language model parameters into MLLMs. Experimental results based on five MLLMs on nine benchmarks demonstrate the effectiveness of our method. Attention-based analysis further reveals that merging shifts attention from diffuse, scattered patterns to focused localization on task-relevant visual regions. Our repository is on https://github.com/wzj1718/PlaM.
HyperVL: An Efficient and Dynamic Multimodal Large Language Model for Edge Devices
Dec 16, 2025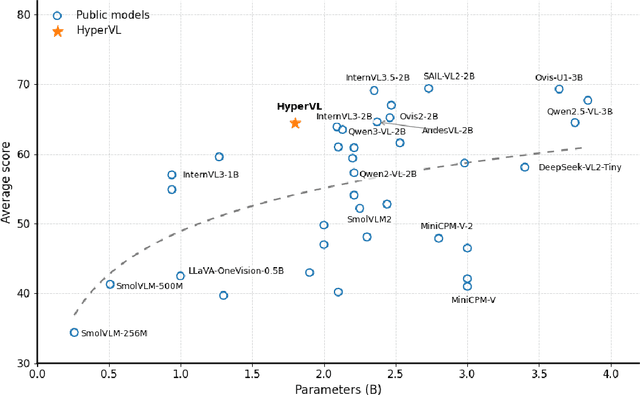

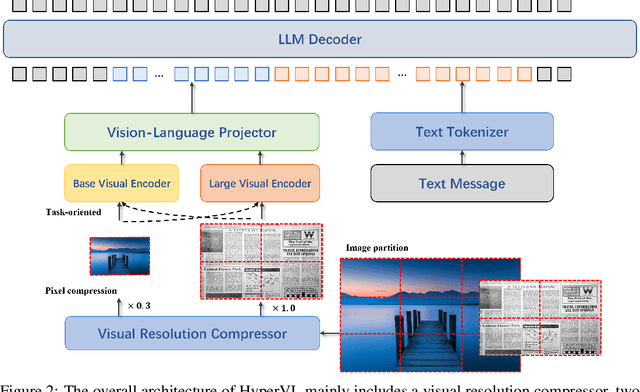

Current multimodal large lanauge models possess strong perceptual and reasoning capabilities, however high computational and memory requirements make them difficult to deploy directly on on-device environments. While small-parameter models are progressively endowed with strong general capabilities, standard Vision Transformer (ViT) encoders remain a critical bottleneck, suffering from excessive latency and memory consumption when processing high-resolution inputs.To address these challenges, we introduce HyperVL, an efficient multimodal large language model tailored for on-device inference. HyperVL adopts an image-tiling strategy to cap peak memory usage and incorporates two novel techniques: (1) a Visual Resolution Compressor (VRC) that adaptively predicts optimal encoding resolutions to eliminate redundant computation, and (2) Dual Consistency Learning (DCL), which aligns multi-scale ViT encoders within a unified framework, enabling dynamic switching between visual branches under a shared LLM. Extensive experiments demonstrate that HyperVL achieves state-of-the-art performance among models of comparable size across multiple benchmarks. Furthermore, it significantly significantly reduces latency and power consumption on real mobile devices, demonstrating its practicality for on-device multimodal inference.
Reactive Aerobatic Flight via Reinforcement Learning
May 30, 2025Quadrotors have demonstrated remarkable versatility, yet their full aerobatic potential remains largely untapped due to inherent underactuation and the complexity of aggressive maneuvers. Traditional approaches, separating trajectory optimization and tracking control, suffer from tracking inaccuracies, computational latency, and sensitivity to initial conditions, limiting their effectiveness in dynamic, high-agility scenarios. Inspired by recent breakthroughs in data-driven methods, we propose a reinforcement learning-based framework that directly maps drone states and aerobatic intentions to control commands, eliminating modular separation to enable quadrotors to perform end-to-end policy optimization for extreme aerobatic maneuvers. To ensure efficient and stable training, we introduce an automated curriculum learning strategy that dynamically adjusts aerobatic task difficulty. Enabled by domain randomization for robust zero-shot sim-to-real transfer, our approach is validated in demanding real-world experiments, including the first demonstration of a drone autonomously performing continuous inverted flight while reactively navigating a moving gate, showcasing unprecedented agility.
Refusal Direction is Universal Across Safety-Aligned Languages
May 22, 2025Refusal mechanisms in large language models (LLMs) are essential for ensuring safety. Recent research has revealed that refusal behavior can be mediated by a single direction in activation space, enabling targeted interventions to bypass refusals. While this is primarily demonstrated in an English-centric context, appropriate refusal behavior is important for any language, but poorly understood. In this paper, we investigate the refusal behavior in LLMs across 14 languages using PolyRefuse, a multilingual safety dataset created by translating malicious and benign English prompts into these languages. We uncover the surprising cross-lingual universality of the refusal direction: a vector extracted from English can bypass refusals in other languages with near-perfect effectiveness, without any additional fine-tuning. Even more remarkably, refusal directions derived from any safety-aligned language transfer seamlessly to others. We attribute this transferability to the parallelism of refusal vectors across languages in the embedding space and identify the underlying mechanism behind cross-lingual jailbreaks. These findings provide actionable insights for building more robust multilingual safety defenses and pave the way for a deeper mechanistic understanding of cross-lingual vulnerabilities in LLMs.
Language Mixing in Reasoning Language Models: Patterns, Impact, and Internal Causes
May 20, 2025Reasoning language models (RLMs) excel at complex tasks by leveraging a chain-of-thought process to generate structured intermediate steps. However, language mixing, i.e., reasoning steps containing tokens from languages other than the prompt, has been observed in their outputs and shown to affect performance, though its impact remains debated. We present the first systematic study of language mixing in RLMs, examining its patterns, impact, and internal causes across 15 languages, 7 task difficulty levels, and 18 subject areas, and show how all three factors influence language mixing. Moreover, we demonstrate that the choice of reasoning language significantly affects performance: forcing models to reason in Latin or Han scripts via constrained decoding notably improves accuracy. Finally, we show that the script composition of reasoning traces closely aligns with that of the model's internal representations, indicating that language mixing reflects latent processing preferences in RLMs. Our findings provide actionable insights for optimizing multilingual reasoning and open new directions for controlling reasoning languages to build more interpretable and adaptable RLMs.
Through a Compressed Lens: Investigating the Impact of Quantization on LLM Explainability and Interpretability
May 20, 2025Quantization methods are widely used to accelerate inference and streamline the deployment of large language models (LLMs). While prior research has extensively investigated the degradation of various LLM capabilities due to quantization, its effects on model explainability and interpretability, which are crucial for understanding decision-making processes, remain unexplored. To address this gap, we conduct comprehensive experiments using three common quantization techniques at distinct bit widths, in conjunction with two explainability methods, counterfactual examples and natural language explanations, as well as two interpretability approaches, knowledge memorization analysis and latent multi-hop reasoning analysis. We complement our analysis with a thorough user study, evaluating selected explainability methods. Our findings reveal that, depending on the configuration, quantization can significantly impact model explainability and interpretability. Notably, the direction of this effect is not consistent, as it strongly depends on (1) the quantization method, (2) the explainability or interpretability approach, and (3) the evaluation protocol. In some settings, human evaluation shows that quantization degrades explainability, while in others, it even leads to improvements. Our work serves as a cautionary tale, demonstrating that quantization can unpredictably affect model transparency. This insight has important implications for deploying LLMs in applications where transparency is a critical requirement.
Tracing Multilingual Factual Knowledge Acquisition in Pretraining
May 20, 2025Large Language Models (LLMs) are capable of recalling multilingual factual knowledge present in their pretraining data. However, most studies evaluate only the final model, leaving the development of factual recall and crosslingual consistency throughout pretraining largely unexplored. In this work, we trace how factual recall and crosslingual consistency evolve during pretraining, focusing on OLMo-7B as a case study. We find that both accuracy and consistency improve over time for most languages. We show that this improvement is primarily driven by the fact frequency in the pretraining corpus: more frequent facts are more likely to be recalled correctly, regardless of language. Yet, some low-frequency facts in non-English languages can still be correctly recalled. Our analysis reveals that these instances largely benefit from crosslingual transfer of their English counterparts -- an effect that emerges predominantly in the early stages of pretraining. We pinpoint two distinct pathways through which multilingual factual knowledge acquisition occurs: (1) frequency-driven learning, which is dominant and language-agnostic, and (2) crosslingual transfer, which is limited in scale and typically constrained to relation types involving named entities. We release our code and data to facilitate further research at https://github.com/cisnlp/multilingual-fact-tracing.
Real-Time Spatial Reasoning by Mobile Robots for Reconstruction and Navigation in Dynamic LiDAR Scenes
May 18, 2025



Our brain has an inner global positioning system which enables us to sense and navigate 3D spaces in real time. Can mobile robots replicate such a biological feat in a dynamic environment? We introduce the first spatial reasoning framework for real-time surface reconstruction and navigation that is designed for outdoor LiDAR scanning data captured by ground mobile robots and capable of handling moving objects such as pedestrians. Our reconstruction-based approach is well aligned with the critical cellular functions performed by the border vector cells (BVCs) over all layers of the medial entorhinal cortex (MEC) for surface sensing and tracking. To address the challenges arising from blurred boundaries resulting from sparse single-frame LiDAR points and outdated data due to object movements, we integrate real-time single-frame mesh reconstruction, via visibility reasoning, with robot navigation assistance through on-the-fly 3D free space determination. This enables continuous and incremental updates of the scene and free space across multiple frames. Key to our method is the utilization of line-of-sight (LoS) vectors from LiDAR, which enable real-time surface normal estimation, as well as robust and instantaneous per-voxel free space updates. We showcase two practical applications: real-time 3D scene reconstruction and autonomous outdoor robot navigation in real-world conditions. Comprehensive experiments on both synthetic and real scenes highlight our method's superiority in speed and quality over existing real-time LiDAR processing approaches.