 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign of A Low-Latency and Parallelizable SVD Dataflow Architecture on FPGA
Nov 18, 2025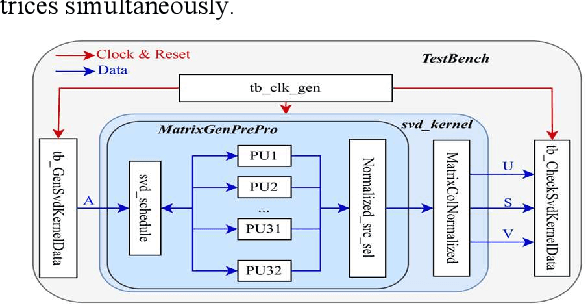
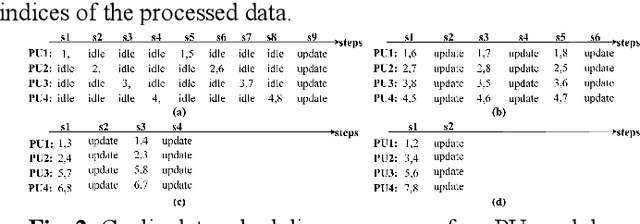
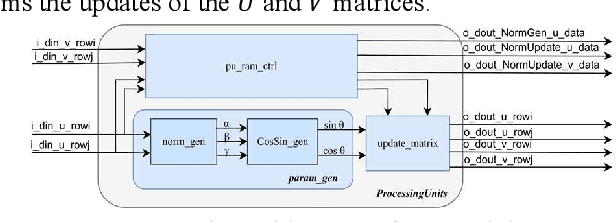
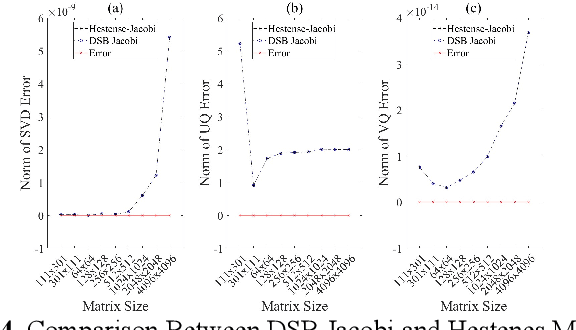
Singular value decomposition (SVD) is widely used for dimensionality reduction and noise suppression, and it plays a pivotal role in numerous scientific and engineering applications. As the dimensions of the matrix grow rapidly, the computational cost increases significantly, posing a serious challenge to the efficiency of data analysis and signal processing systems,especially in time-sensitive scenarios with large-scale datasets. Although various dedicated hardware architectures have been proposed to accelerate the computation of intensive SVD, many of these designs suffer from limited scalability and high consumption of on-chip memory resources. Moreover, they typically overlook the computational and data transfer challenges associated with SVD, enabling them unsuitable for real-time processing of large-scale data stream matrices in embedded systems. In this express, we propose a Data Stream-Based SVD processing algorithm (DSB Jacobi), which significantly reduces on-chip BRAM usage while improving computational speed, offering a practical solution for real-time SVD computation of large-scale data streams. Compared with previous works, our experimental results indicate that the proposed method reduces on-chip RAM consumption by 41.5 percent and improves computational efficiency by 23 times.
EPIC: Efficient Prompt Interaction for Text-Image Classification
Jul 10, 2025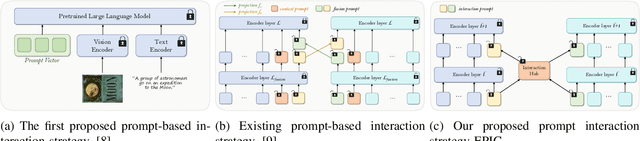
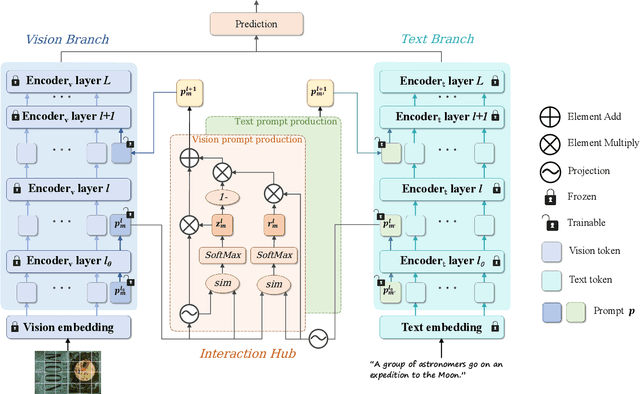
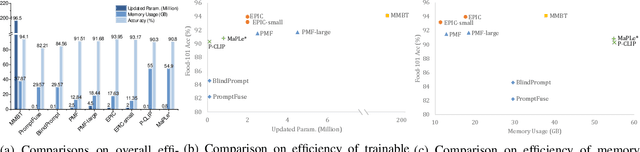

In recent years, large-scale pre-trained multimodal models (LMMs) generally emerge to integrate the vision and language modalities, achieving considerable success in multimodal tasks, such as text-image classification. The growing size of LMMs, however, results in a significant computational cost for fine-tuning these models for downstream tasks. Hence, prompt-based interaction strategy is studied to align modalities more efficiently. In this context, we propose a novel efficient prompt-based multimodal interaction strategy, namely Efficient Prompt Interaction for text-image Classification (EPIC). Specifically, we utilize temporal prompts on intermediate layers, and integrate different modalities with similarity-based prompt interaction, to leverage sufficient information exchange between modalities. Utilizing this approach, our method achieves reduced computational resource consumption and fewer trainable parameters (about 1\% of the foundation model) compared to other fine-tuning strategies. Furthermore, it demonstrates superior performance on the UPMC-Food101 and SNLI-VE datasets, while achieving comparable performance on the MM-IMDB dataset.
Accelerating Diffusion-based Super-Resolution with Dynamic Time-Spatial Sampling
May 17, 2025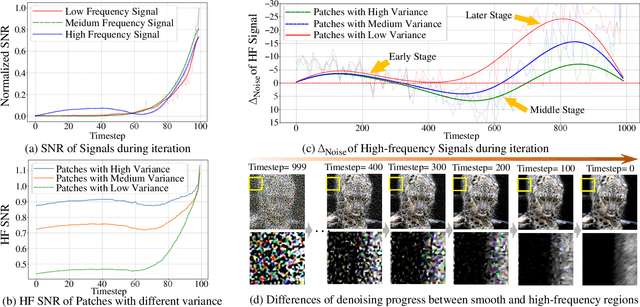
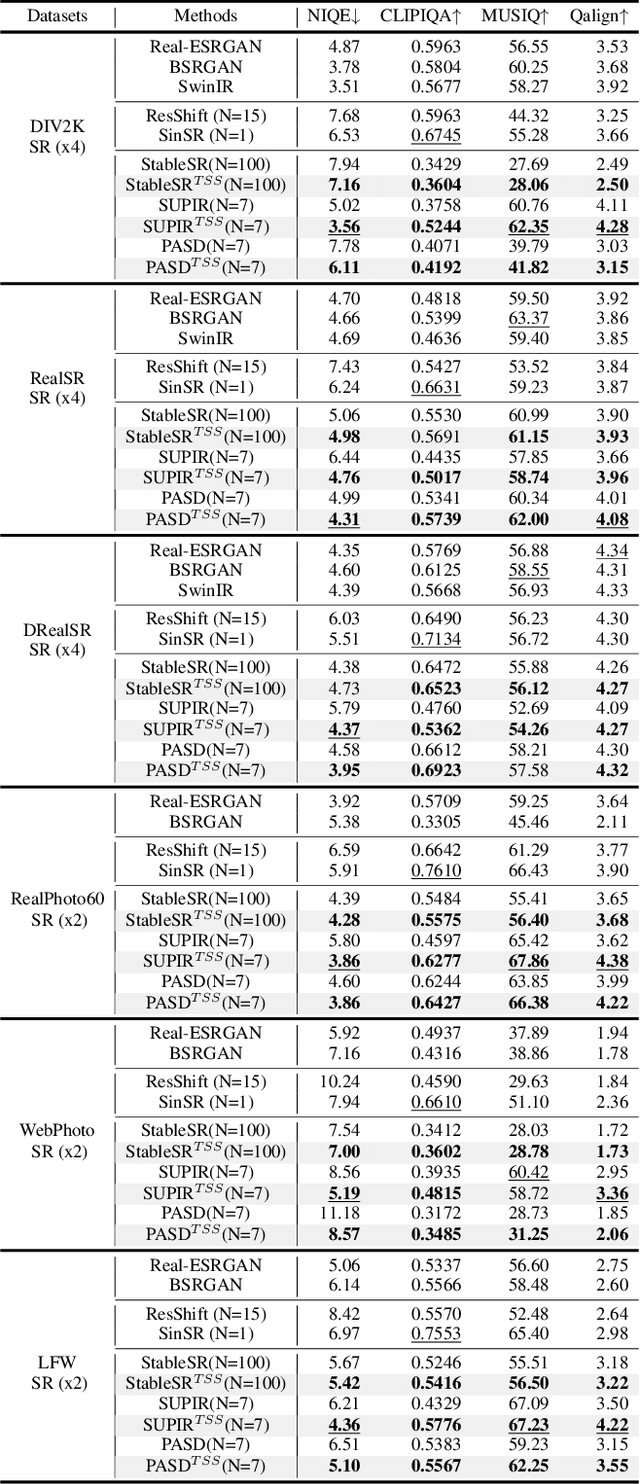
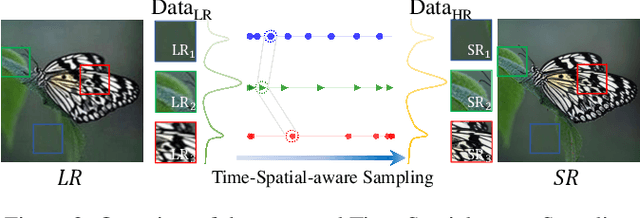
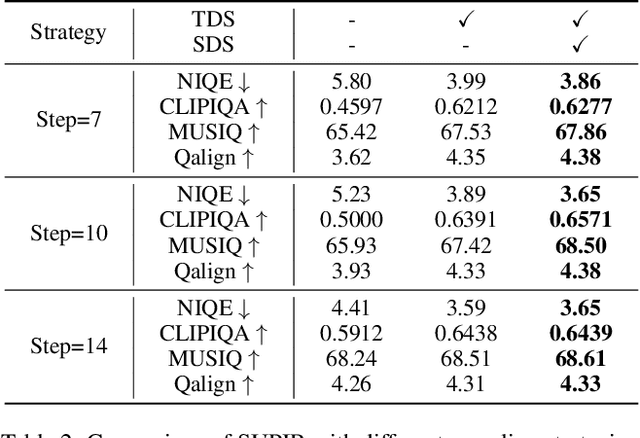
Diffusion models have gained attention for their success in modeling complex distributions, achieving impressive perceptual quality in SR tasks. However, existing diffusion-based SR methods often suffer from high computational costs, requiring numerous iterative steps for training and inference. Existing acceleration techniques, such as distillation and solver optimization, are generally task-agnostic and do not fully leverage the specific characteristics of low-level tasks like super-resolution (SR). In this study, we analyze the frequency- and spatial-domain properties of diffusion-based SR methods, revealing key insights into the temporal and spatial dependencies of high-frequency signal recovery. Specifically, high-frequency details benefit from concentrated optimization during early and late diffusion iterations, while spatially textured regions demand adaptive denoising strategies. Building on these observations, we propose the Time-Spatial-aware Sampling strategy (TSS) for the acceleration of Diffusion SR without any extra training cost. TSS combines Time Dynamic Sampling (TDS), which allocates more iterations to refining textures, and Spatial Dynamic Sampling (SDS), which dynamically adjusts strategies based on image content. Extensive evaluations across multiple benchmarks demonstrate that TSS achieves state-of-the-art (SOTA) performance with significantly fewer iterations, improving MUSIQ scores by 0.2 - 3.0 and outperforming the current acceleration methods with only half the number of steps.
CoordField: Coordination Field for Agentic UAV Task Allocation In Low-altitude Urban Scenarios
Apr 30, 2025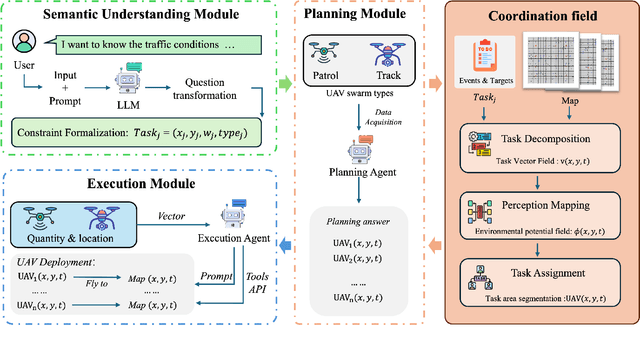
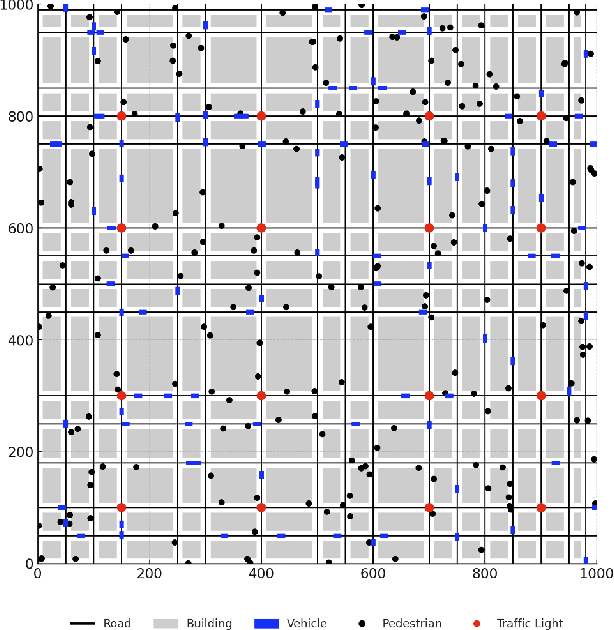
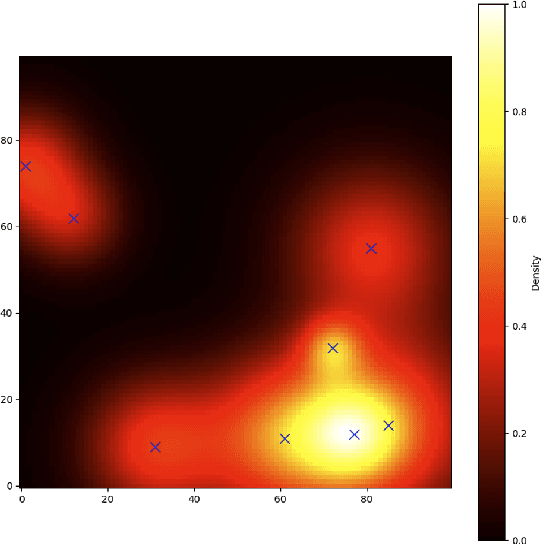
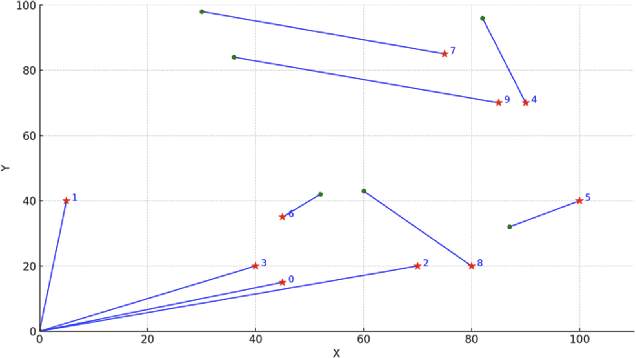
With the increasing demand for heterogeneous Unmanned Aerial Vehicle (UAV) swarms to perform complex tasks in urban environments, system design now faces major challenges, including efficient semantic understanding, flexible task planning, and the ability to dynamically adjust coordination strategies in response to evolving environmental conditions and continuously changing task requirements. To address the limitations of existing approaches, this paper proposes coordination field agentic system for coordinating heterogeneous UAV swarms in complex urban scenarios. In this system, large language models (LLMs) is responsible for interpreting high-level human instructions and converting them into executable commands for the UAV swarms, such as patrol and target tracking. Subsequently, a Coordination field mechanism is proposed to guide UAV motion and task selection, enabling decentralized and adaptive allocation of emergent tasks. A total of 50 rounds of comparative testing were conducted across different models in a 2D simulation space to evaluate their performance. Experimental results demonstrate that the proposed system achieves superior performance in terms of task coverage, response time, and adaptability to dynamic changes.
Semantic Hierarchical Prompt Tuning for Parameter-Efficient Fine-Tuning
Dec 24, 2024



As the scale of vision models continues to grow, Visual Prompt Tuning (VPT) has emerged as a parameter-efficient transfer learning technique, noted for its superior performance compared to full fine-tuning. However, indiscriminately applying prompts to every layer without considering their inherent correlations, can cause significant disturbances, leading to suboptimal transferability. Additionally, VPT disrupts the original self-attention structure, affecting the aggregation of visual features, and lacks a mechanism for explicitly mining discriminative visual features, which are crucial for classification. To address these issues, we propose a Semantic Hierarchical Prompt (SHIP) fine-tuning strategy. We adaptively construct semantic hierarchies and use semantic-independent and semantic-shared prompts to learn hierarchical representations. We also integrate attribute prompts and a prompt matching loss to enhance feature discrimination and employ decoupled attention for robustness and reduced inference costs. SHIP significantly improves performance, achieving a 4.9% gain in accuracy over VPT with a ViT-B/16 backbone on VTAB-1k tasks. Our code is available at https://github.com/haoweiz23/SHIP.
A New Dataset and Framework for Real-World Blurred Images Super-Resolution
Jul 20, 2024



Recent Blind Image Super-Resolution (BSR) methods have shown proficiency in general images. However, we find that the efficacy of recent methods obviously diminishes when employed on image data with blur, while image data with intentional blur constitute a substantial proportion of general data. To further investigate and address this issue, we developed a new super-resolution dataset specifically tailored for blur images, named the Real-world Blur-kept Super-Resolution (ReBlurSR) dataset, which consists of nearly 3000 defocus and motion blur image samples with diverse blur sizes and varying blur intensities. Furthermore, we propose a new BSR framework for blur images called Perceptual-Blur-adaptive Super-Resolution (PBaSR), which comprises two main modules: the Cross Disentanglement Module (CDM) and the Cross Fusion Module (CFM). The CDM utilizes a dual-branch parallelism to isolate conflicting blur and general data during optimization. The CFM fuses the well-optimized prior from these distinct domains cost-effectively and efficiently based on model interpolation. By integrating these two modules, PBaSR achieves commendable performance on both general and blur data without any additional inference and deployment cost and is generalizable across multiple model architectures. Rich experiments show that PBaSR achieves state-of-the-art performance across various metrics without incurring extra inference costs. Within the widely adopted LPIPS metrics, PBaSR achieves an improvement range of approximately 0.02-0.10 with diverse anchor methods and blur types, across both the ReBlurSR and multiple common general BSR benchmarks. Code here: https://github.com/Imalne/PBaSR.
Token-Mol 1.0: Tokenized drug design with large language model
Jul 10, 2024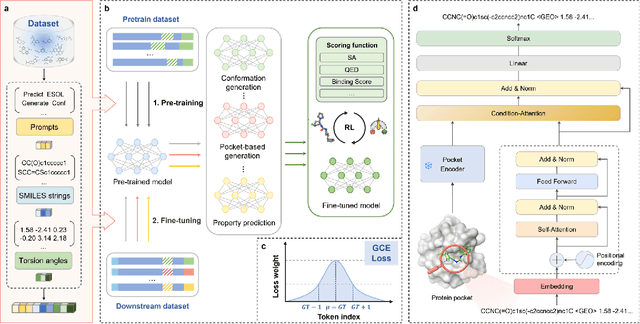

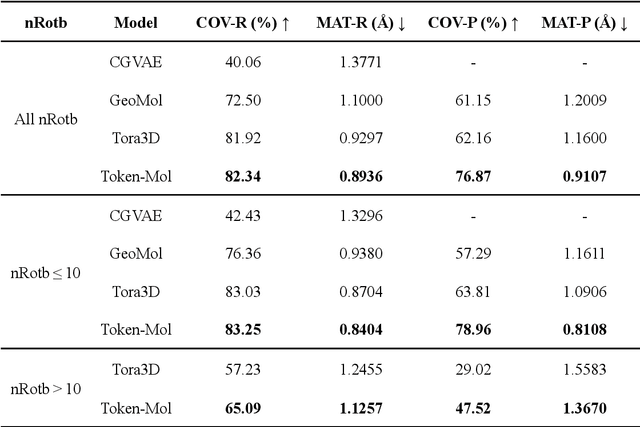
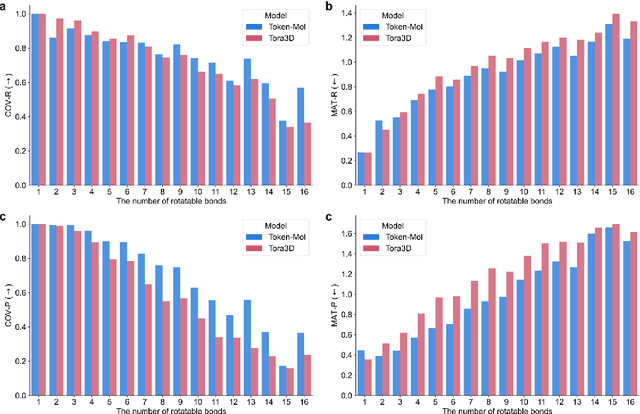
Significant interests have recently risen in leveraging sequence-based large language models (LLMs) for drug design. However, most current applications of LLMs in drug discovery lack the ability to comprehend three-dimensional (3D) structures, thereby limiting their effectiveness in tasks that explicitly involve molecular conformations. In this study, we introduced Token-Mol, a token-only 3D drug design model. This model encodes all molecular information, including 2D and 3D structures, as well as molecular property data, into tokens, which transforms classification and regression tasks in drug discovery into probabilistic prediction problems, thereby enabling learning through a unified paradigm. Token-Mol is built on the transformer decoder architecture and trained using random causal masking techniques. Additionally, we proposed the Gaussian cross-entropy (GCE) loss function to overcome the challenges in regression tasks, significantly enhancing the capacity of LLMs to learn continuous numerical values. Through a combination of fine-tuning and reinforcement learning (RL), Token-Mol achieves performance comparable to or surpassing existing task-specific methods across various downstream tasks, including pocket-based molecular generation, conformation generation, and molecular property prediction. Compared to existing molecular pre-trained models, Token-Mol exhibits superior proficiency in handling a wider range of downstream tasks essential for drug design. Notably, our approach improves regression task accuracy by approximately 30% compared to similar token-only methods. Token-Mol overcomes the precision limitations of token-only models and has the potential to integrate seamlessly with general models such as ChatGPT, paving the way for the development of a universal artificial intelligence drug design model that facilitates rapid and high-quality drug design by experts.
Memory-Inspired Temporal Prompt Interaction for Text-Image Classification
Jan 26, 2024In recent years, large-scale pre-trained multimodal models (LMM) generally emerge to integrate the vision and language modalities, achieving considerable success in various natural language processing and computer vision tasks. The growing size of LMMs, however, results in a significant computational cost for fine-tuning these models for downstream tasks. Hence, prompt-based interaction strategy is studied to align modalities more efficiently. In this contex, we propose a novel prompt-based multimodal interaction strategy inspired by human memory strategy, namely Memory-Inspired Temporal Prompt Interaction (MITP). Our proposed method involves in two stages as in human memory strategy: the acquiring stage, and the consolidation and activation stage. We utilize temporal prompts on intermediate layers to imitate the acquiring stage, leverage similarity-based prompt interaction to imitate memory consolidation, and employ prompt generation strategy to imitate memory activation. The main strength of our paper is that we interact the prompt vectors on intermediate layers to leverage sufficient information exchange between modalities, with compressed trainable parameters and memory usage. We achieve competitive results on several datasets with relatively small memory usage and 2.0M of trainable parameters (about 1% of the pre-trained foundation model).
Blind Image Super-resolution with Rich Texture-Aware Codebooks
Oct 26, 2023Blind super-resolution (BSR) methods based on high-resolution (HR) reconstruction codebooks have achieved promising results in recent years. However, we find that a codebook based on HR reconstruction may not effectively capture the complex correlations between low-resolution (LR) and HR images. In detail, multiple HR images may produce similar LR versions due to complex blind degradations, causing the HR-dependent only codebooks having limited texture diversity when faced with confusing LR inputs. To alleviate this problem, we propose the Rich Texture-aware Codebook-based Network (RTCNet), which consists of the Degradation-robust Texture Prior Module (DTPM) and the Patch-aware Texture Prior Module (PTPM). DTPM effectively mines the cross-resolution correlation of textures between LR and HR images by exploiting the cross-resolution correspondence of textures. PTPM uses patch-wise semantic pre-training to correct the misperception of texture similarity in the high-level semantic regularization. By taking advantage of this, RTCNet effectively gets rid of the misalignment of confusing textures between HR and LR in the BSR scenarios. Experiments show that RTCNet outperforms state-of-the-art methods on various benchmarks by up to 0.16 ~ 0.46dB.
Scene Text Image Super-Resolution via Content Perceptual Loss and Criss-Cross Transformer Blocks
Oct 13, 2022

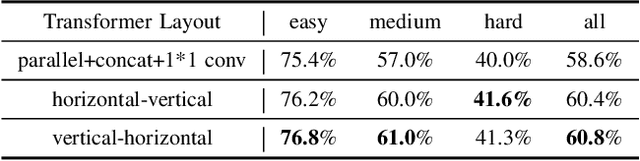

Text image super-resolution is a unique and important task to enhance readability of text images to humans. It is widely used as pre-processing in scene text recognition. However, due to the complex degradation in natural scenes, recovering high-resolution texts from the low-resolution inputs is ambiguous and challenging. Existing methods mainly leverage deep neural networks trained with pixel-wise losses designed for natural image reconstruction, which ignore the unique character characteristics of texts. A few works proposed content-based losses. However, they only focus on text recognizers' accuracy, while the reconstructed images may still be ambiguous to humans. Further, they often have weak generalizability to handle cross languages. To this end, we present TATSR, a Text-Aware Text Super-Resolution framework, which effectively learns the unique text characteristics using Criss-Cross Transformer Blocks (CCTBs) and a novel Content Perceptual (CP) Loss. The CCTB extracts vertical and horizontal content information from text images by two orthogonal transformers, respectively. The CP Loss supervises the text reconstruction with content semantics by multi-scale text recognition features, which effectively incorporates content awareness into the framework. Extensive experiments on various language datasets demonstrate that TATSR outperforms state-of-the-art methods in terms of both recognition accuracy and human perception.