 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoT-Seg: Rethinking Segmentation with Chain-of-Thought Reasoning and Self-Correction
Jan 24, 2026Existing works of reasoning segmentation often fall short in complex cases, particularly when addressing complicated queries and out-of-domain images. Inspired by the chain-of-thought reasoning, where harder problems require longer thinking steps/time, this paper aims to explore a system that can think step-by-step, look up information if needed, generate results, self-evaluate its own results, and refine the results, in the same way humans approach harder questions. We introduce CoT-Seg, a training-free framework that rethinks reasoning segmentation by combining chain-of-thought reasoning with self-correction. Instead of fine-tuning, CoT-Seg leverages the inherent reasoning ability of pre-trained MLLMs (GPT-4o) to decompose queries into meta-instructions, extract fine-grained semantics from images, and identify target objects even under implicit or complex prompts. Moreover, CoT-Seg incorporates a self-correction stage: the model evaluates its own segmentation against the original query and reasoning trace, identifies mismatches, and iteratively refines the mask. This tight integration of reasoning and correction significantly improves reliability and robustness, especially in ambiguous or error-prone cases. Furthermore, our CoT-Seg framework allows easy incorporation of retrieval-augmented reasoning, enabling the system to access external knowledge when the input lacks sufficient information. To showcase CoT-Seg's ability to handle very challenging cases ,we introduce a new dataset ReasonSeg-Hard. Our results highlight that combining chain-of-thought reasoning, self-correction, offers a powerful paradigm for vision-language integration driven segmentation.
ContextAnyone: Context-Aware Diffusion for Character-Consistent Text-to-Video Generation
Dec 08, 2025



Text-to-video (T2V) generation has advanced rapidly, yet maintaining consistent character identities across scenes remains a major challenge. Existing personalization methods often focus on facial identity but fail to preserve broader contextual cues such as hairstyle, outfit, and body shape, which are critical for visual coherence. We propose \textbf{ContextAnyone}, a context-aware diffusion framework that achieves character-consistent video generation from text and a single reference image. Our method jointly reconstructs the reference image and generates new video frames, enabling the model to fully perceive and utilize reference information. Reference information is effectively integrated into a DiT-based diffusion backbone through a novel Emphasize-Attention module that selectively reinforces reference-aware features and prevents identity drift across frames. A dual-guidance loss combines diffusion and reference reconstruction objectives to enhance appearance fidelity, while the proposed Gap-RoPE positional embedding separates reference and video tokens to stabilize temporal modeling. Experiments demonstrate that ContextAnyone outperforms existing reference-to-video methods in identity consistency and visual quality, generating coherent and context-preserving character videos across diverse motions and scenes. Project page: \href{https://github.com/ziyang1106/ContextAnyone}{https://github.com/ziyang1106/ContextAnyone}.
SmartAvatar: Text- and Image-Guided Human Avatar Generation with VLM AI Agents
Jun 05, 2025



SmartAvatar is a vision-language-agent-driven framework for generating fully rigged, animation-ready 3D human avatars from a single photo or textual prompt. While diffusion-based methods have made progress in general 3D object generation, they continue to struggle with precise control over human identity, body shape, and animation readiness. In contrast, SmartAvatar leverages the commonsense reasoning capabilities of large vision-language models (VLMs) in combination with off-the-shelf parametric human generators to deliver high-quality, customizable avatars. A key innovation is an autonomous verification loop, where the agent renders draft avatars, evaluates facial similarity, anatomical plausibility, and prompt alignment, and iteratively adjusts generation parameters for convergence. This interactive, AI-guided refinement process promotes fine-grained control over both facial and body features, enabling users to iteratively refine their avatars via natural-language conversations. Unlike diffusion models that rely on static pre-trained datasets and offer limited flexibility, SmartAvatar brings users into the modeling loop and ensures continuous improvement through an LLM-driven procedural generation and verification system. The generated avatars are fully rigged and support pose manipulation with consistent identity and appearance, making them suitable for downstream animation and interactive applications. Quantitative benchmarks and user studies demonstrate that SmartAvatar outperforms recent text- and image-driven avatar generation systems in terms of reconstructed mesh quality, identity fidelity, attribute accuracy, and animation readiness, making it a versatile tool for realistic, customizable avatar creation on consumer-grade hardware.
MA-RAG: Multi-Agent Retrieval-Augmented Generation via Collaborative Chain-of-Thought Reasoning
May 26, 2025We present MA-RAG, a Multi-Agent framework for Retrieval-Augmented Generation (RAG) that addresses the inherent ambiguities and reasoning challenges in complex information-seeking tasks. Unlike conventional RAG methods that rely on either end-to-end fine-tuning or isolated component enhancements, MA-RAG orchestrates a collaborative set of specialized AI agents: Planner, Step Definer, Extractor, and QA Agents, to tackle each stage of the RAG pipeline with task-aware reasoning. Ambiguities may arise from underspecified queries, sparse or indirect evidence in retrieved documents, or the need to integrate information scattered across multiple sources. MA-RAG mitigates these challenges by decomposing the problem into subtasks, such as query disambiguation, evidence extraction, and answer synthesis, and dispatching them to dedicated agents equipped with chain-of-thought prompting. These agents communicate intermediate reasoning and progressively refine the retrieval and synthesis process. Our design allows fine-grained control over information flow without any model fine-tuning. Crucially, agents are invoked on demand, enabling a dynamic and efficient workflow that avoids unnecessary computation. This modular and reasoning-driven architecture enables MA-RAG to deliver robust, interpretable results. Experiments on multi-hop and ambiguous QA benchmarks demonstrate that MA-RAG outperforms state-of-the-art training-free baselines and rivals fine-tuned systems, validating the effectiveness of collaborative agent-based reasoning in RAG.
Agentic 3D Scene Generation with Spatially Contextualized VLMs
May 26, 2025Despite recent advances in multimodal content generation enabled by vision-language models (VLMs), their ability to reason about and generate structured 3D scenes remains largely underexplored. This limitation constrains their utility in spatially grounded tasks such as embodied AI, immersive simulations, and interactive 3D applications. We introduce a new paradigm that enables VLMs to generate, understand, and edit complex 3D environments by injecting a continually evolving spatial context. Constructed from multimodal input, this context consists of three components: a scene portrait that provides a high-level semantic blueprint, a semantically labeled point cloud capturing object-level geometry, and a scene hypergraph that encodes rich spatial relationships, including unary, binary, and higher-order constraints. Together, these components provide the VLM with a structured, geometry-aware working memory that integrates its inherent multimodal reasoning capabilities with structured 3D understanding for effective spatial reasoning. Building on this foundation, we develop an agentic 3D scene generation pipeline in which the VLM iteratively reads from and updates the spatial context. The pipeline features high-quality asset generation with geometric restoration, environment setup with automatic verification, and ergonomic adjustment guided by the scene hypergraph. Experiments show that our framework can handle diverse and challenging inputs, achieving a level of generalization not observed in prior work. Further results demonstrate that injecting spatial context enables VLMs to perform downstream tasks such as interactive scene editing and path planning, suggesting strong potential for spatially intelligent systems in computer graphics, 3D vision, and embodied applications.
ThinkVideo: High-Quality Reasoning Video Segmentation with Chain of Thoughts
May 24, 2025Reasoning Video Object Segmentation is a challenging task, which generates a mask sequence from an input video and an implicit, complex text query. Existing works probe into the problem by finetuning Multimodal Large Language Models (MLLM) for segmentation-based output, while still falling short in difficult cases on videos given temporally-sensitive queries, primarily due to the failure to integrate temporal and spatial information. In this paper, we propose ThinkVideo, a novel framework which leverages the zero-shot Chain-of-Thought (CoT) capability of MLLM to address these challenges. Specifically, ThinkVideo utilizes the CoT prompts to extract object selectivities associated with particular keyframes, then bridging the reasoning image segmentation model and SAM2 video processor to output mask sequences. The ThinkVideo framework is training-free and compatible with closed-source MLLMs, which can be applied to Reasoning Video Instance Segmentation. We further extend the framework for online video streams, where the CoT is used to update the object of interest when a better target starts to emerge and becomes visible. We conduct extensive experiments on video object segmentation with explicit and implicit queries. The results show that ThinkVideo significantly outperforms previous works in both cases, qualitatively and quantitatively.
FusionSegReID: Advancing Person Re-Identification with Multimodal Retrieval and Precise Segmentation
Mar 27, 2025
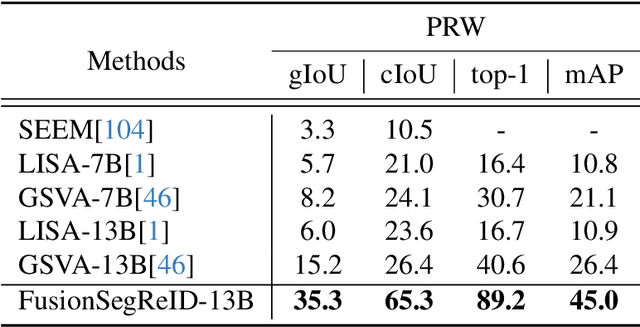
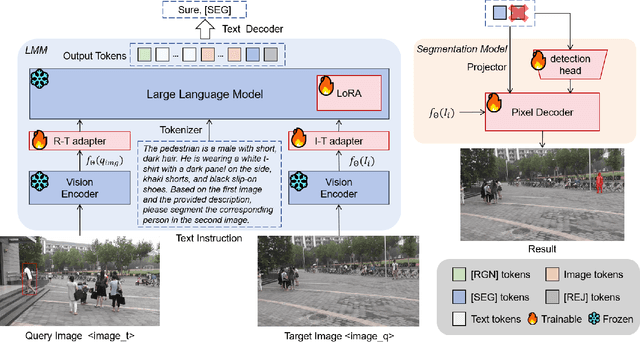
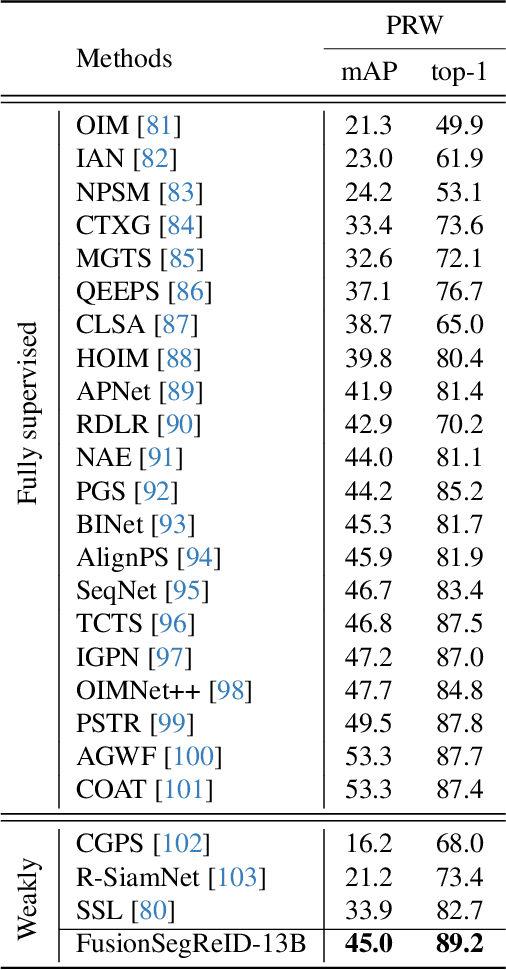
Person re-identification (ReID) plays a critical role in applications like security surveillance and criminal investigations by matching individuals across large image galleries captured by non-overlapping cameras. Traditional ReID methods rely on unimodal inputs, typically images, but face limitations due to challenges like occlusions, lighting changes, and pose variations. While advancements in image-based and text-based ReID systems have been made, the integration of both modalities has remained under-explored. This paper presents FusionSegReID, a multimodal model that combines both image and text inputs for enhanced ReID performance. By leveraging the complementary strengths of these modalities, our model improves matching accuracy and robustness, particularly in complex, real-world scenarios where one modality may struggle. Our experiments show significant improvements in Top-1 accuracy and mean Average Precision (mAP) for ReID, as well as better segmentation results in challenging scenarios like occlusion and low-quality images. Ablation studies further confirm that multimodal fusion and segmentation modules contribute to enhanced re-identification and mask accuracy. The results show that FusionSegReID outperforms traditional unimodal models, offering a more robust and flexible solution for real-world person ReID tasks.
Multimodal Generation of Animatable 3D Human Models with AvatarForge
Mar 11, 2025We introduce AvatarForge, a framework for generating animatable 3D human avatars from text or image inputs using AI-driven procedural generation. While diffusion-based methods have made strides in general 3D object generation, they struggle with high-quality, customizable human avatars due to the complexity and diversity of human body shapes, poses, exacerbated by the scarcity of high-quality data. Additionally, animating these avatars remains a significant challenge for existing methods. AvatarForge overcomes these limitations by combining LLM-based commonsense reasoning with off-the-shelf 3D human generators, enabling fine-grained control over body and facial details. Unlike diffusion models which often rely on pre-trained datasets lacking precise control over individual human features, AvatarForge offers a more flexible approach, bringing humans into the iterative design and modeling loop, with its auto-verification system allowing for continuous refinement of the generated avatars, and thus promoting high accuracy and customization. Our evaluations show that AvatarForge outperforms state-of-the-art methods in both text- and image-to-avatar generation, making it a versatile tool for artistic creation and animation.
ReelWave: A Multi-Agent Framework Toward Professional Movie Sound Generation
Mar 10, 2025



Film production is an important application for generative audio, where richer context is provided through multiple scenes. In ReelWave, we propose a multi-agent framework for audio generation inspired by the professional movie production process. We first capture semantic and temporal synchronized "on-screen" sound by training a prediction model that predicts three interpretable time-varying audio control signals comprising loudness, pitch, and timbre. These three parameters are subsequently specified as conditions by a cross-attention module. Then, our framework infers "off-screen" sound to complement the generation through cooperative interaction between communicative agents. Each agent takes up specific roles similar to the movie production team and is supervised by an agent called the director. Besides, we investigate when the conditional video consists of multiple scenes, a case frequently seen in videos extracted from movies of considerable length. Consequently, our framework can capture a richer context of audio generation conditioned on video clips extracted from movies.
Dynamic Path Navigation for Motion Agents with LLM Reasoning
Mar 10, 2025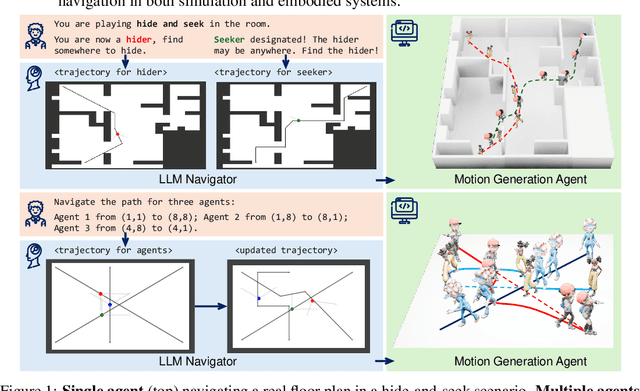
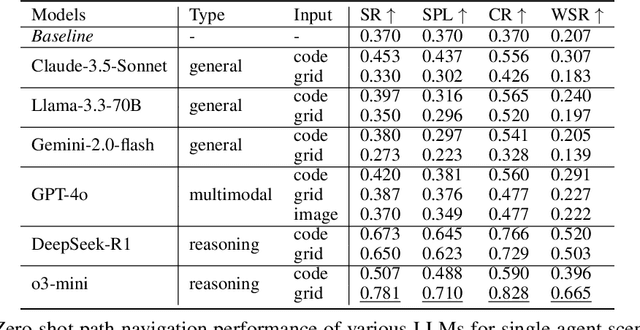
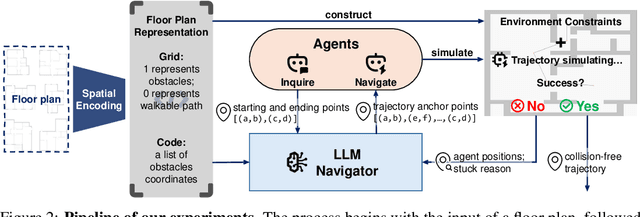
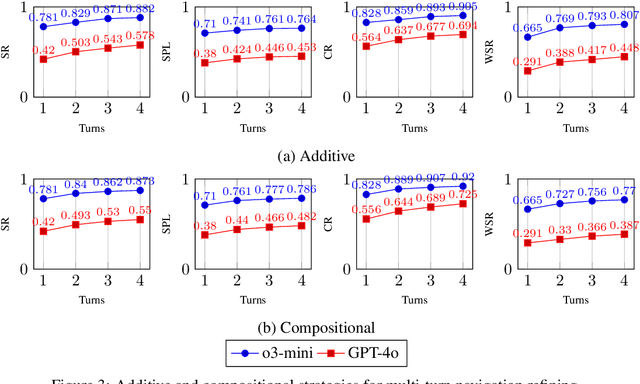
Large Language Models (LLMs) have demonstrated strong generalizable reasoning and planning capabilities. However, their efficacies in spatial path planning and obstacle-free trajectory generation remain underexplored. Leveraging LLMs for navigation holds significant potential, given LLMs' ability to handle unseen scenarios, support user-agent interactions, and provide global control across complex systems, making them well-suited for agentic planning and humanoid motion generation. As one of the first studies in this domain, we explore the zero-shot navigation and path generation capabilities of LLMs by constructing a dataset and proposing an evaluation protocol. Specifically, we represent paths using anchor points connected by straight lines, enabling movement in various directions. This approach offers greater flexibility and practicality compared to previous methods while remaining simple and intuitive for LLMs. We demonstrate that, when tasks are well-structured in this manner, modern LLMs exhibit substantial planning proficiency in avoiding obstacles while autonomously refining navigation with the generated motion to reach the target. Further, this spatial reasoning ability of a single LLM motion agent interacting in a static environment can be seamlessly generalized in multi-motion agents coordination in dynamic environments. Unlike traditional approaches that rely on single-step planning or local policies, our training-free LLM-based method enables global, dynamic, closed-loop planning, and autonomously resolving collision issues.