 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionSegReID: Advancing Person Re-Identification with Multimodal Retrieval and Precise Segmentation
Mar 27, 2025
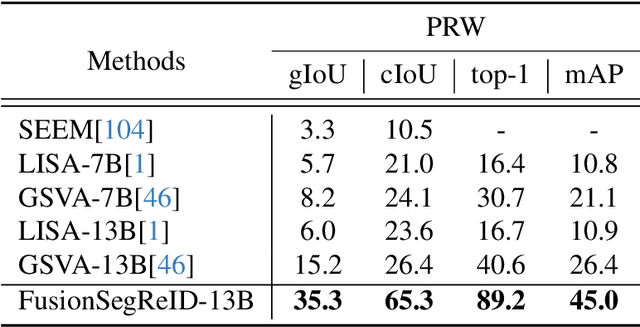
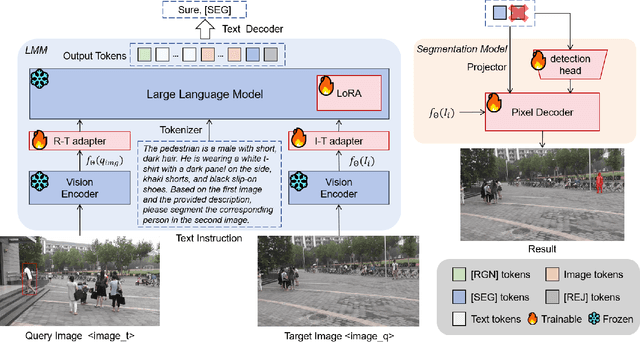
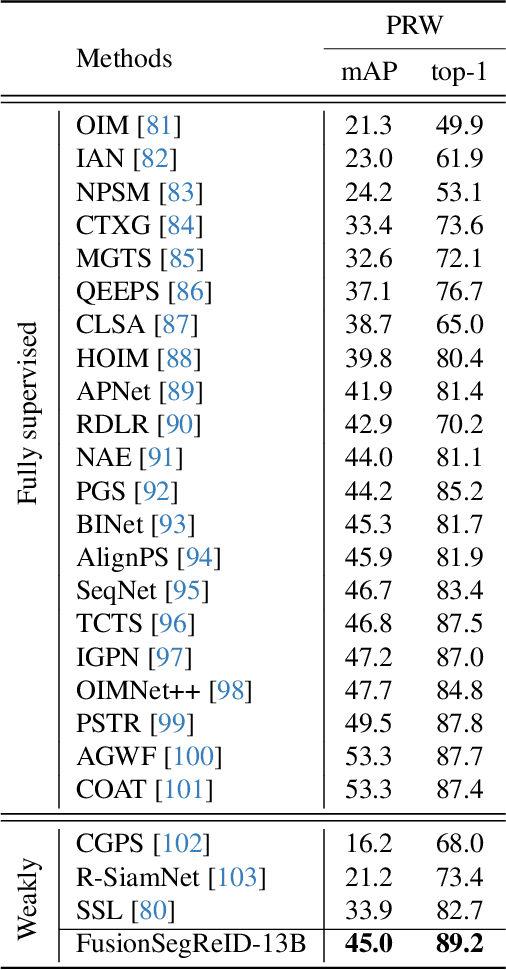
Person re-identification (ReID) plays a critical role in applications like security surveillance and criminal investigations by matching individuals across large image galleries captured by non-overlapping cameras. Traditional ReID methods rely on unimodal inputs, typically images, but face limitations due to challenges like occlusions, lighting changes, and pose variations. While advancements in image-based and text-based ReID systems have been made, the integration of both modalities has remained under-explored. This paper presents FusionSegReID, a multimodal model that combines both image and text inputs for enhanced ReID performance. By leveraging the complementary strengths of these modalities, our model improves matching accuracy and robustness, particularly in complex, real-world scenarios where one modality may struggle. Our experiments show significant improvements in Top-1 accuracy and mean Average Precision (mAP) for ReID, as well as better segmentation results in challenging scenarios like occlusion and low-quality images. Ablation studies further confirm that multimodal fusion and segmentation modules contribute to enhanced re-identification and mask accuracy. The results show that FusionSegReID outperforms traditional unimodal models, offering a more robust and flexible solution for real-world person ReID tasks.
Car-1000: A New Large Scale Fine-Grained Visual Categorization Dataset
Mar 16, 2025



Fine-grained visual categorization (FGVC) is a challenging but significant task in computer vision, which aims to recognize different sub-categories of birds, cars, airplanes, etc. Among them, recognizing models of different cars has significant application value in autonomous driving, traffic surveillance and scene understanding, which has received considerable attention in the past few years. However, Stanford-Car, the most widely used fine-grained dataset for car recognition, only has 196 different categories and only includes vehicle models produced earlier than 2013. Due to the rapid advancements in the automotive industry during recent years, the appearances of various car models have become increasingly intricate and sophisticated. Consequently, the previous Stanford-Car dataset fails to capture this evolving landscape and cannot satisfy the requirements of automotive industry. To address these challenges, in our paper, we introduce Car-1000, a large-scale dataset designed specifically for fine-grained visual categorization of diverse car models. Car-1000 encompasses vehicles from 165 different automakers, spanning a wide range of 1000 distinct car models. Additionally, we have reproduced several state-of-the-art FGVC methods on the Car-1000 dataset, establishing a new benchmark for research in this field. We hope that our work will offer a fresh perspective for future FGVC researchers. Our dataset is available at https://github.com/toggle1995/Car-1000.
Fusion-Mamba for Cross-modality Object Detection
Apr 14, 2024
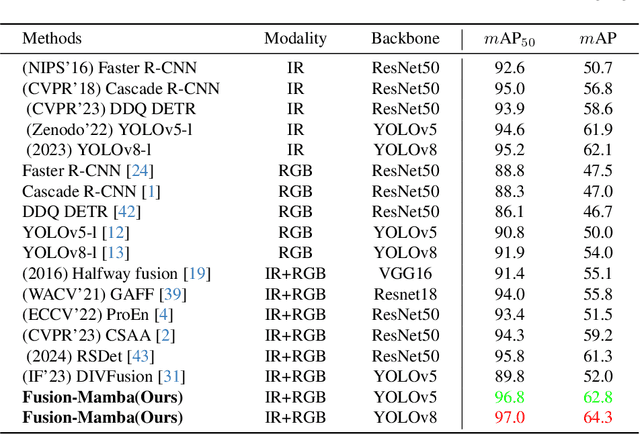
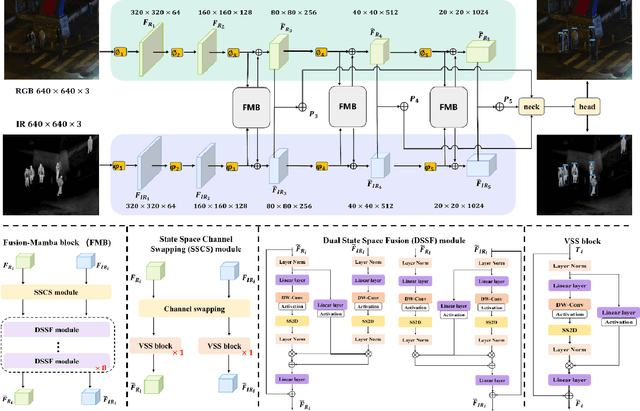
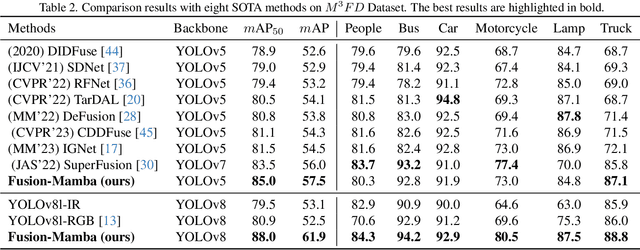
Cross-modality fusing complementary information from different modalities effectively improves object detection performance, making it more useful and robust for a wider range of applications. Existing fusion strategies combine different types of images or merge different backbone features through elaborated neural network modules. However, these methods neglect that modality disparities affect cross-modality fusion performance, as different modalities with different camera focal lengths, placements, and angles are hardly fused. In this paper, we investigate cross-modality fusion by associating cross-modal features in a hidden state space based on an improved Mamba with a gating mechanism. We design a Fusion-Mamba block (FMB) to map cross-modal features into a hidden state space for interaction, thereby reducing disparities between cross-modal features and enhancing the representation consistency of fused features. FMB contains two modules: the State Space Channel Swapping (SSCS) module facilitates shallow feature fusion, and the Dual State Space Fusion (DSSF) enables deep fusion in a hidden state space. Through extensive experiments on public datasets, our proposed approach outperforms the state-of-the-art methods on $m$AP with 5.9% on $M^3FD$ and 4.9% on FLIR-Aligned datasets, demonstrating superior object detection performance. To the best of our knowledge, this is the first work to explore the potential of Mamba for cross-modal fusion and establish a new baseline for cross-modality object detection.
Neural optimal controller for stochastic systems via pathwise HJB operator
Feb 23, 2024



The aim of this work is to develop deep learning-based algorithms for high-dimensional stochastic control problems based on physics-informed learning and dynamic programming. Unlike classical deep learning-based methods relying on a probabilistic representation of the solution to the Hamilton--Jacobi--Bellman (HJB) equation, we introduce a pathwise operator associated with the HJB equation so that we can define a problem of physics-informed learning. According to whether the optimal control has an explicit representation, two numerical methods are proposed to solve the physics-informed learning problem. We provide an error analysis on how the truncation, approximation and optimization errors affect the accuracy of these methods. Numerical results on various applications are presented to illustrate the performance of the proposed algorithms.
GMTalker: Gaussian Mixture based Emotional talking video Portraits
Dec 12, 2023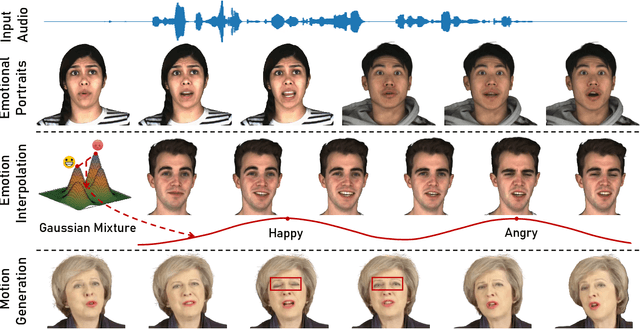
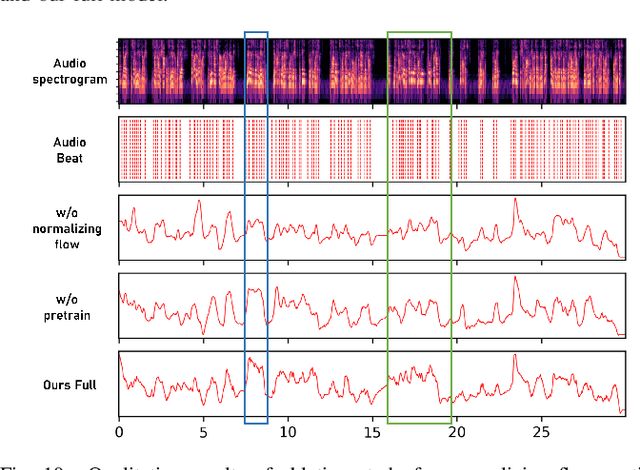

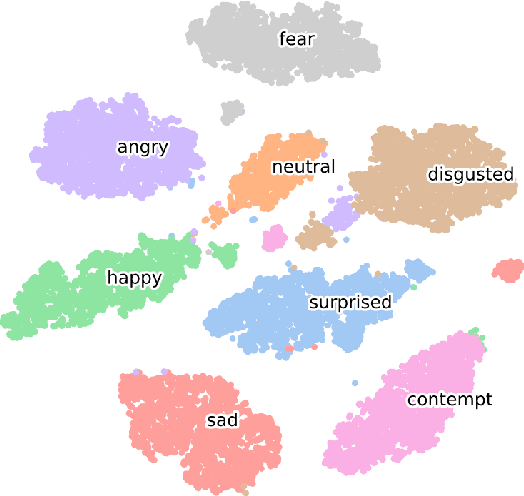
Synthesizing high-fidelity and emotion-controllable talking video portraits, with audio-lip sync, vivid expression, realistic head pose, and eye blink, is an important and challenging task in recent years. Most of the existing methods suffer in achieving personalized precise emotion control or continuously interpolating between different emotions and generating diverse motion. To address these problems, we present GMTalker, a Gaussian mixture based emotional talking portraits generation framework. Specifically, we propose a Gaussian Mixture based Expression Generator (GMEG) which can construct a continuous and multi-modal latent space, achieving more flexible emotion manipulation. Furthermore, we introduce a normalizing flow based motion generator pretrained on the dataset with a wide-range motion to generate diverse motions. Finally, we propose a personalized emotion-guided head generator with an Emotion Mapping Network (EMN) which can synthesize high-fidelity and faithful emotional video portraits. Both quantitative and qualitative experiments demonstrate our method outperforms previous methods in image quality, photo-realism, emotion accuracy and motion diversity.
RT-SRTS: Angle-Agnostic Real-Time Simultaneous 3D Reconstruction and Tumor Segmentation from Single X-Ray Projection
Oct 12, 2023Radiotherapy is one of the primary treatment methods for tumors, but the organ movement caused by respiratory motion limits its accuracy. Recently, 3D imaging from single X-ray projection receives extensive attentions as a promising way to address this issue. However, current methods can only reconstruct 3D image without direct location of the tumor and are only validated for fixed-angle imaging, which fails to fully meet the requirement of motion control in radiotherapy. In this study, we propose a novel imaging method RT-SRTS which integrates 3D imaging and tumor segmentation into one network based on the multi-task learning (MTL) and achieves real-time simultaneous 3D reconstruction and tumor segmentation from single X-ray projection at any angle. Futhermore, we propose the attention enhanced calibrator (AEC) and uncertain-region elaboration (URE) modules to aid feature extraction and improve segmentation accuracy. We evaluated the proposed method on ten patient cases and compared it with two state-of-the-art methods. Our approach not only delivered superior 3D reconstruction but also demonstrated commendable tumor segmentation results. The simultaneous reconstruction and segmentation could be completed in approximately 70 ms, significantly faster than the required time threshold for real-time tumor tracking. The efficacy of both AEC and URE was also validated through ablation studies.
Implicit Diffusion Models for Continuous Super-Resolution
Mar 29, 2023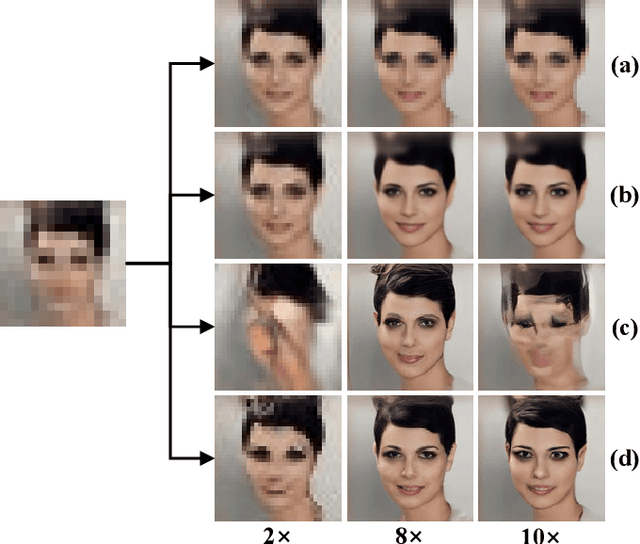


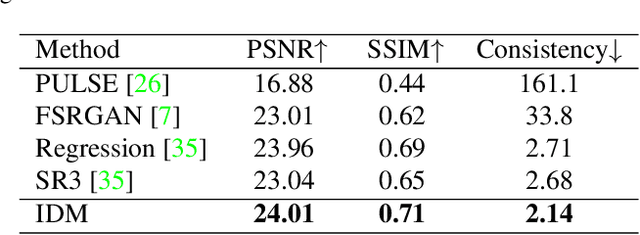
Image super-resolution (SR) has attracted increasing attention due to its wide applications. However, current SR methods generally suffer from over-smoothing and artifacts, and most work only with fixed magnifications. This paper introduces an Implicit Diffusion Model (IDM) for high-fidelity continuous image super-resolution. IDM integrates an implicit neural representation and a denoising diffusion model in a unified end-to-end framework, where the implicit neural representation is adopted in the decoding process to learn continuous-resolution representation. Furthermore, we design a scale-controllable conditioning mechanism that consists of a low-resolution (LR) conditioning network and a scaling factor. The scaling factor regulates the resolution and accordingly modulates the proportion of the LR information and generated features in the final output, which enables the model to accommodate the continuous-resolution requirement. Extensive experiments validate the effectiveness of our IDM and demonstrate its superior performance over prior arts.
Inference-InfoGAN: Inference Independence via Embedding Orthogonal Basis Expansion
Oct 02, 2021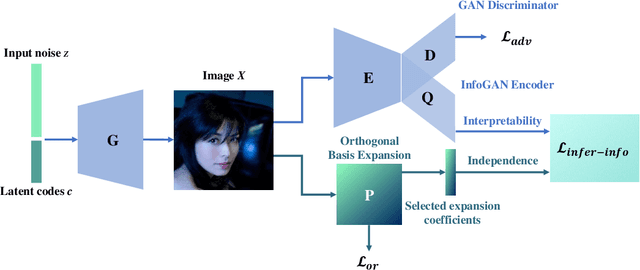
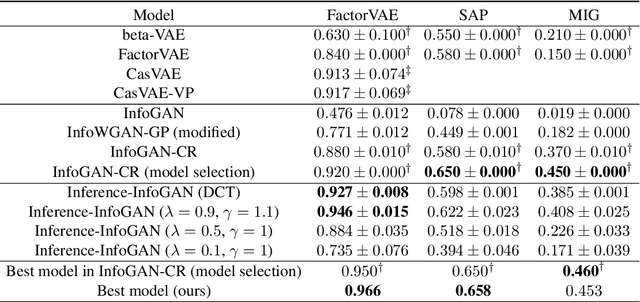
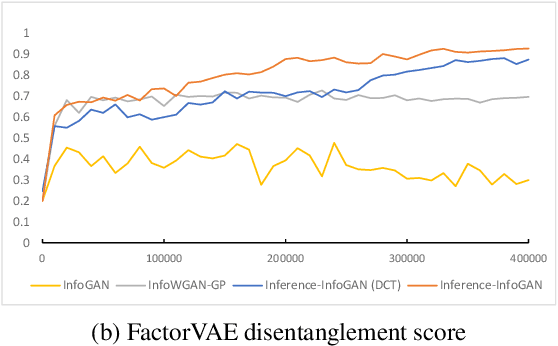
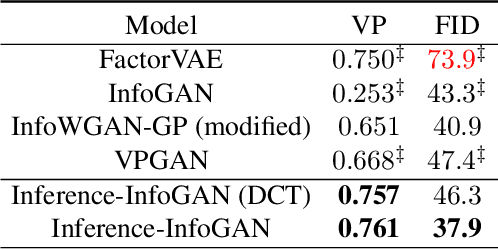
Disentanglement learning aims to construct independent and interpretable latent variables in which generative models are a popular strategy. InfoGAN is a classic method via maximizing Mutual Information (MI) to obtain interpretable latent variables mapped to the target space. However, it did not emphasize independent characteristic. To explicitly infer latent variables with inter-independence, we propose a novel GAN-based disentanglement framework via embedding Orthogonal Basis Expansion (OBE) into InfoGAN network (Inference-InfoGAN) in an unsupervised way. Under the OBE module, one set of orthogonal basis can be adaptively found to expand arbitrary data with independence property. To ensure the target-wise interpretable representation, we add a consistence constraint between the expansion coefficients and latent variables on the base of MI maximization. Additionally, we design an alternating optimization step on the consistence constraint and orthogonal requirement updating, so that the training of Inference-InfoGAN can be more convenient. Finally, experiments validate that our proposed OBE module obtains adaptive orthogonal basis, which can express better independent characteristics than fixed basis expression of Discrete Cosine Transform (DCT). To depict the performance in downstream tasks, we compared with the state-of-the-art GAN-based and even VAE-based approaches on different datasets. Our Inference-InfoGAN achieves higher disentanglement score in terms of FactorVAE, Separated Attribute Predictability (SAP), Mutual Information Gap (MIG) and Variation Predictability (VP) metrics without model fine-tuning. All the experimental results illustrate that our method has inter-independence inference ability because of the OBE module, and provides a good trade-off between it and target-wise interpretability of latent variables via jointing the alternating optimization.